Cheat Sheet of NLP Practitioner
I am actively maintaining this blog post, gathering NLP papers around large language models, information extraction, structured data-related downstream applications, {retrieval, tool}-augmented language models, prompting techniques and beyond.
Table of Contents
- 1. Knowledge Retrieval - Augmented Language Model
- Retrieval Meets Long Context Large Language Models (Xu, arxiv 2023)
- Meta-training with Demonstration Retrieval for Efficient Few-shot Learning (Mueller, Finding ACL 2023)
- GLIMMER: generalized late-interaction memory reranker (de Jong, arxiv 2023)
- Pre-computed memory or on-the-fly encoding? A hybrid approach to retrieval augmentation makes the most of your compute (de Jong, ICML 2023)
- How Does Generative Retrieval Scale to Millions of Passages? (Pradeep∗ et al., GenIR@SIGIR 2023)
- Recitation-Augmented Language Models (Sun et al., ICLR 2023)
- REPLUG: Retrieval-Augmented Black-Box Language Models (Shi et al., arxiv 2023)
- Rethinking with Retrieval: Faithful Large Language Model Inference (He et al., arxiv 2023)
- Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions (Trivedi et al., ACL 2023)
- Transformer Memory as a Differentiable Search Index (Tay et al., Neurips 2022)
- Autoregressive Search Engines: Generating Substrings as Document Identifiers (Bevilacqua et al., Neurips 2022)
- Atlas: Few-shot Learning with Retrieval Augmented Language Models (Izacard et al., arxiv 2022)
- EIDER: Empowering Document-level Relation Extraction with Efficient Evidence Extraction and Inference-stage Fusion (Xie et al., ACL Findings 2022)
- Don’t Prompt, Search! Mining-based Zero-Shot Learning with Language Models (van de Kar et al., EMNLP 2022)
- SKILL: Structured Knowledge Infusion for Large Language Models (Moiseev et al., NAACL 2022)
- Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (Izacard et al., EACL 2021)
- REALM: Retrieval-Augmented Language Model Pre-Training (Guu et al., ICML 2020)
- Generalization through Memorization: Nearest Neighbor Language Models (Khandelwal et al., ICLR 2020):
- 2. Information Extraction
- How to Unleash the Power of Large Language Models for Few-shot Relation Extraction? (Xu et al., SustaiNLP@ACL 2023)
- GPT-RE: In-context Learning for Relation Extraction using Large Language Models (Wan et al., arxiv 2023)
- Universal Information Extraction as Unified Semantic Matching (Lou et al., AAAI 2023)
- StructGPT: A General Framework for Large Language Model to Reason over Structured Data (Jiang et al., arxiv 2023)
- GPT4Graph: Can Large Language Models Understand Graph Structured Data? An Empirical Evaluation and Benchmarking (Guo et al., arxiv 2023)
- NEUROSTRUCTURAL DECODING: Neural Text Generation with Structural Constraints (Bastan et al., ACL 2023)
- Retrieval-Enhanced Generative Model for Large-Scale Knowledge Graph Completion (Yu et al., SIGIR 2023)
- Knowledge Base Completion for Long-Tail Entities (Chen et al., arxiv 2023)
- InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction (Wang et al., arxiv 2023)
- Unifying Molecular and Textual Representations via Multi-task Language Modelling (Christofidellis et al., ICML 2023)
- Triggering Multi-Hop Reasoning for Question Answering in Language Models using Soft Prompts and Random Walks (Misra et al., Findings ACL 2023)
- Flexible Grammar-Based Constrained Decoding for Language Models (Geng et al., arxiv 2023)
- Methods for Measuring, Updating, and Visualizing Factual Beliefs in Language Models (Hase et al., EACL 2023)
- Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge (Onoe et al., ACL 2023)
- DEMONSTRATE–SEARCH–PREDICT: Composing retrieval and language models for knowledge-intensive NLP (Khattab et al., arxiv 2023)
- CODEIE: Large Code Generation Models are Better Few-Shot Information Extractors (Li et al., ACL 2023)
- Evaluating Language Models for Knowledge Base Completion (Veseli et al., ESWC 2023)
- Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction (Josifoski et al., arxiv 2023)
- Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! (Ma et al., arxiv 2023)
- Understanding Fine-tuning for Factual Knowledge Extraction from Language Models (Kazemi et al., submitted to JMLR)
- Crawling The Internal Knowledge-Base of Language Models (Cohen et al., TBD)
- GREASELM: Graph Reasoning Enhanced Language Models for Question Answering (Zhang et al., ICLR 2022)
- Entity Cloze By Date: What LMs Know About Unseen Entities (Onoe et al., Finding NAACL 2022)
- Large Language Models Struggle to Learn Long-Tail Knowledge (Kandpal et al., arxiv 2022)
- Unified Structure Generation for Universal Information Extraction (Lu et al., ACL 2022)
- GenIE: Generative Information Extraction (Josifoski et al., NAACL 2022)
- EIDER: Empowering Document-level Relation Extraction with Efficient Evidence Extraction and Inference-stage Fusion (Xie et al., ACL Findings 2022)
- KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction (Chen et al., The WebConf 2022)
- Rewire-then-Probe: A Contrastive Recipe for Probing Biomedical Knowledge of Pre-trained Language Models (Meng et al., ACL 2022)
- Do Pre-trained Models Benefit Knowledge Graph Completion? A Reliable Evaluation and a Reasonable Approach (Lv et al., ACL-Findings 2022)
- SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models (Wang et al. ACL 2022)
- Task-specific Pre-training and Prompt Decomposition for Knowledge Graph Population with Language Models (Li et al., LM-KBC@ISWC 2022 Challenge)
- GENRE: Autoregressive Entity Retrieval (De Cao et al., ICLR 2021).
- Structured Prediction as Translation Between Augmented Natural Languages (Paolini et al., ICLR 2021)
- How Can We Know What Language Models Know? (Jiang et al., TACL 2020)
- 3. Prompting Methods
- Large Language Models as Optimizers (Yang, arxiv 2023)
- How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources (Wang et al., arxiv 2023) + The Flan Collection: Designing Data and Methods for Effective Instruction Tuning (Longpre et al., ICML 2023)
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models (Zhou et al., ICLR 2023)
- Multitask Prompt Tuning enables Parameter-Efficient Transfer Learning (Wang et al., ICLR 2023)
- Grammar Prompting for Domain-Specific Language Generation with Large Language Models (Wang et al., arxiv 2023)
- Symbol Tuning Improves In-Context Learning In Language Models (Wei et al., arxiv 2023)
- Selective Annotation Makes Language Models Better Few-Shot Learners (Su et al., ICLR 2023)
- Learning to Reason and Memorize with Self-Notes (Lanchantin et al., arxiv 2023)
- Self-Consistency improves Chain Of Thought Reasoning in Language Models (Wang et al., ICLR 2023)
- Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations (Jung et al., EMNLP 2022):
- MetaICL: Learning to Learn In Context (Min et al., NAACL 2022)
- Self-Instruct: Aligning LM with Self Generated Instructions (Wang et al., arxiv 2022)
- Finetuned Language Models are Zero-Shot Learners (Wei et al., ICLR 2022)
- Multitask Prompted Training Enables Zero-Shot Task Generalization (Sanh et al., ICLR 2022)
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., Neurips 2022)
- Do Prompt-Based Models Really Understand the Meaning of Their Prompts? (Webson et al., NAACL 2022)
- Prefix-Tuning: Optimizing Continuous Prompts for Generation (Li et al., ACL 2021)
- The Power of Scale for Parameter-Efficient Prompt Tuning (Lester et al., EMNLP 2021)
- 4. Tools-Augmented Language Model
- 5. Misc
- Task-Specific Skill Localization in Fine-tuned Language Models (Panigrahi et al., ICML 2023)
- Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models (Liu et al., ICML 2023)
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining (Xie et al., arxiv 2023)
- Data Selection for Language Models via Importance Resampling (Xie et al., arxiv 2023)
- Language Models represent Space and Time (Gurnee et al., arxiv 2023)
- Can Foundation Models Wrangle Your Data? (Narayan et al., VLDB 2023)
- Ranking and Tuning Pre-trained Models: A New Paradigm for Exploiting Model Hubs (You et al., JMLR 2023) + LogME: Practical Assessment of Pre-trained Models for Transfer Learning (You et al., ICML 2021)
- On Exploring the Reasoning Capability of Large Language Models with Knowledge Graphs (Lo et al., GenIR@SIGIR 2023)
- Towards Robust and Efficient Continual Language Learning (Fisch et al., arxiv 2023)
- Beyond Scale: the Diversity Coefficient as a Data Quality Metric Demonstrates LLMs are Pre-trained on Formally Diverse Data (Lee et al., ICML 2023)
- Textbooks Are All You Need (Gunsasekar et al., arxiv 2023)
- Evaluating and Enhancing Structural Understanding Capabilities of Large Language Models on Tables via Input Designs (Sui et al., arxiv 2023)
- Benchmarking Large Language Model Capabilities for Conditional Generation (Joshua et al., ACL 2023)
- Lost in the Middle: How Language Models Use Long Contexts (Nelson et al., arxiv 2023)
- Faith and Fate: Limits of Transformers on Compositionality (Dziri et al., arxiv 2023)
- Improving Representational Continuity with Supervised Continued Pretraining (Sun et al., arxiv 2023) + Fine-tuning can distort pretrained features and underperform out-of-distribution (Kumar et al., ICLR 2022)
- Can Language Models Solve Graph Problems in Natural Language? (Wang et al., arxiv 2023)
- Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning (Creswell et al., ICLR 2023)
- Trusting Your Evidence: Hallucinate Less with Context-aware Decoding (Shi et al., arxiv 2023)
- CodeT5+: Open Code Large Language Models for Code Understanding and Generation (Wang et al., arxiv 2023)
- Emergent World Representations: Exploring a Sequence Model Trained On a Synthetic Task (Li et al., ICLR 2023).
- Quantifying Memorization Across Neural Language Models (Carlini et al., ICLR 2023)
- I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation (Bhagavatula et al.):
- Symbolic Knowledge Distillation: from General Language Models to Commonsense Models (West et al., NAACL 2022)
- Efficient Training of Language Models to Fill in the Middle (Bavarian et al., arxiv 2022).
- Language Models of Code are Few-Shot Commonsense Learners (Madaan et al., EMNLP 2022).
- Fast Model Editing at Scale (Mitchell et al., ICLR 2022).
- Locating and Editing Factual Associations in GPT (Meng et al., Neurips 2022).
- Understanding Dataset Difficulty with V-Usable Information (Ethayarajh et al., ICML 2022).
- A Contrastive Framework for Neural Text Generation (Su et al., NeurIPS 2022).
- The Trade-offs of Domain Adaptation for Neural Language Models (Grangier et al., ACL 2022)
- Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models (Tirumala et al., Neurips 2022)
- From zero-shot to few-shot Text Classification with SetFit (Tunstall et al., ENLSP at Neurips 2022)
- Improving Language Models by Retrieving from Trillions of Token (Borgeaud et al., ICML 2022)
- Adapt-and-Distill: Developing Small, Fast and Effective Pretrained Language Models for Domains (Yao et al., ACL Findings 2021)
- UDALM: Unsupervised Domain Adaptation through Language Modeling (Karouzos et al., NAACL 2021)
- MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers (Pillutla et al., NeurIPS 2021).
- SimCSE: Simple Contrastive Learning of Sentence Embeddings (Gao et al., EMNLP 2021).
- Surface Form Competition: Why the Highest Probability Answer Isn’t Always Right (Holtzman et al., EMNLP 2021)
- Prefix-Tuning: Optimizing Continuous Prompts for Generation (Li et al., ACL 2021)
- The Power of Scale for Parameter-Efficient Prompt Tuning (Lester et al., EMNLP 2021)
- BioMegatron: Larger Biomedical Domain Language Model (Shin et al., EMNLP 2020)
- Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (Gururangan et al., ACL 2020):
- Generalization through Memorization: Nearest Neighbor Language Models (Khandelwal et al., ICLR 2020):
- When does label smoothing help?. (Müller et al., NeurIPS 2019).
- Back Translation Improving Neural Machine Translation Models with Monolingual Data (Sennrich et al., ACL 2016)
1. Knowledge Retrieval - Augmented Language Model
2023
-
Retrieval Meets Long Context Large Language Models (Xu, arxiv 2023)
The paper demonstrates the benefit of passage retrieval for both short and long context language model on 7 close book QA datasets. Several observations ares:
- Retrieval is especially useful for 4K-context LLM as the context provided for each question in 7 tasks usually exceeds 4K tokens.
- With the same retrieval passages, 16K-context LLMs exploits the passages more effectively than 4K-context LLMs, leading to better performance. Authors speculate this is because 4K-context suffers from “lost in the middle” issue while retrieval passages are only at the beginning part of 16K-context LLM.
- Retrieval is useful for both long and short-context LLMs (i.e. outperform the without-retrieval counterpart)
-
Meta-training with Demonstration Retrieval for Efficient Few-shot Learning (Mueller, Finding ACL 2023)
Inspired by MetaICL, this paper proposes few-shot meta learning with demonstration retrieval that leverages multi-task learning on a large variety of tasks, endowing small language models with better ability to generalize across different tasks and domains. The meta-training is conducted by employing a freezed dense passage retriever (i.e. RAG) to retrieve k demonstrations \(z\) for an input \(x\). Each demonstration \(z\) is then concatenated with input \(x\) and is fed into a BART-large model. The model is trained to predict the output \(y\) marginalizing over k retrieved demonstrations:
\[p (y|x) \approx \prod_{i}^{N} \sum_{k}^{K} \; p_{retriever} (z_k | x) \; p_{PLM} (y | x, z_k, y_{1:i-1})\]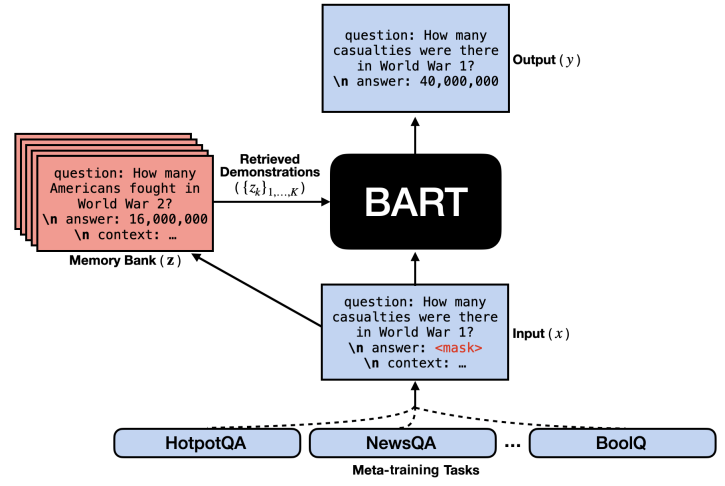
(source: copied from the paper).
To adapt BART to various tasks without architectural modification, input and output are standardized according to an unified template:
Encoder: "question: ... \n answer: [MASK] \n context: \n" Decoder: "question: ... \n answer: ..."Author argues this template aligns with BART’s pre-training objective (generate both question and answer). The results stress the importance of external knowledge bank to the few-shot performance of meta-learned model.
-
GLIMMER: generalized late-interaction memory reranker (de Jong, arxiv 2023)
LUMEN (see here) is a quality-compute trade-off solution for retrieval-augmented LM. GLIMMER is built on LUME with several improvements:
- The memory encoder is fine-tuned, instead of being frozen.
- Live fine-tuned encoder is divided into two parts:
- First N layers (Live-A) is used to re-rank retrieved passages conditioned on the input question. Top-k relevant passages are kept and passed to last M encoder layers.
- Last M layers (Live-B) updates the representation of each {question input, retrieved passage} and sends them to the decoder, similarly to LUME’s live encoder.
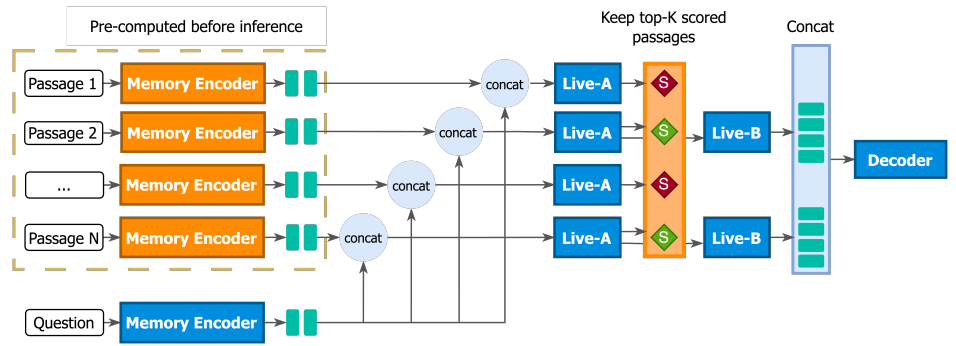
(source: copied from the paper).
Both memory encoder, live encoders and deocer are fine-tuned end-to-end with multi-task learning to endow components better generalization capability. The training loss is inspired Atlas’s PDist (see atlas): promote the passages that lower the generation’s perplexity to be ranked higher.
\(\mathcal{L_{pdist}} = KL (p^{rank} \; | \; p^{LM})\) where \(p^{rank} \varpropto exp(score(passage_k, \; question)/\tau)\) and \(p^{LM} \varpropto exp(log \; p_{LM} (answer \; | \; passage_k, \; question)/\tau)\)
-
Pre-computed memory or on-the-fly encoding? A hybrid approach to retrieval augmentation makes the most of your compute (de Jong, ICML 2023)
LUMEN is a retrieval-augmented LM that neutralizes the pros/cons of Fusion-in-Decoder LM (on-the-fly-encoding) and memory-augmented LM (pre-computed memory):
- Fusion-in-Decoder (FiD) encodes the retrieved passages on-the-fly together with the input \(Enc(input, passage_i)\). Hence, it is expensive if number of retrieved passages is large.
- Memory-augmented pre-computes the embedding of passages, without taking the input into account, \(Enc(passage_i)\). Hence, the representation of each passage is input-agnostic. This method is more efficient than FiD but less powerful.
LUMEN trade-off both methods by employing a frozen large encoder to pre-compute the embeddings for the passages and a live (aka. parameters will be fine-tuned) question-encoder to encode the question. Then, another live encoder but with smaller number of parameters will update the representation of a passage conditioned on the input. Finally, the decoder performs cross-attention over {input, retrieved passage} pairs to select the most relevant one, just like in FiD. As the live encoder in LUME is much smaller than FiD, LUME is more efficient accordingly.
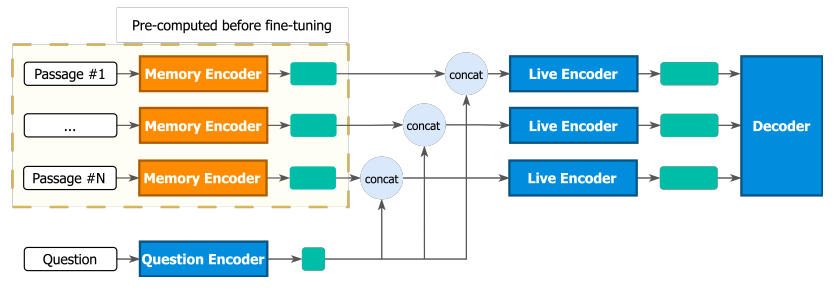
(source: copied from the paper).
Experiments demonstrates the LUME’s performance is very close to FiD while being much cheaper.
-
How Does Generative Retrieval Scale to Millions of Passages? (Pradeep∗ et al., GenIR@SIGIR 2023)
Differential search index (DSI) has emerged as a novel generative retrieval, deviating from common retrieve-then-rerank paradigm. While working effectively on small corpus ( O(100k) documents ), this paper has pointed that the performance of DSI when scaling to large corpus ( O(1M) documents ) is significantly degraded. Several observations:
- Synthetic queries for the fine-tuning of retrieval phase are important, as it helps to reduce the coverage gap: indexing phase sees the whole corpus while this is not the case for retrieval phase.
- In case of MSMarco, indexing phase does not yield gain.
- In case of MSMarco, using Naive IDs as Document Identifiers has strongest performance among {Atomic ID, Naive ID, Semantic ID}. However, scaling LM from T5-XL (3B) to T5-XXL (11B) causes performance drop.
Note: the paper consider only MS-Marco as large corpus, which may cause a bias in the evaluation.
-
Recitation-Augmented Language Models (Sun et al., ICLR 2023)
Leveraging the memorizing ability of large language models, the paper propose RECITE, a recite-and-answer strategy for close book question answering. Instead of retrieving supports from external corpus (“open book”), the model tries to recite the relevant knowledge stored in the model parameters (“close book”) and then answer the question (in the similar way to chain-of-thought prompting).
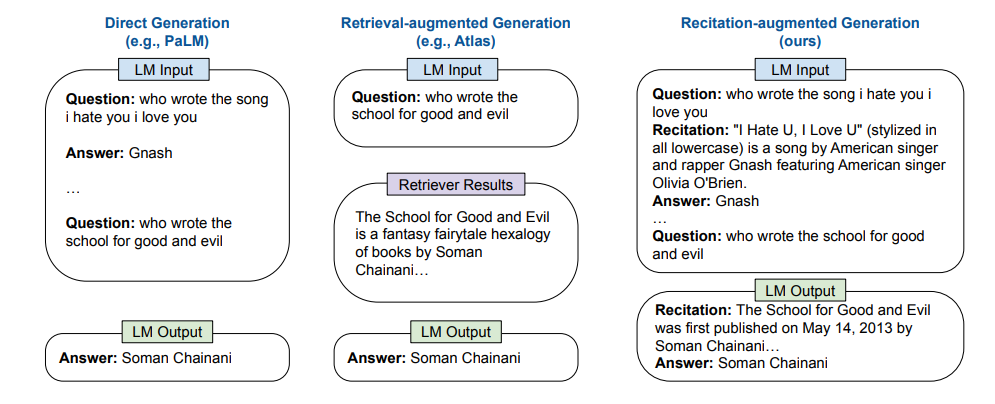
(source: copied from the paper).
They introduces 3 RECITE settings which are all based on in-context learning:
- Recite a single passage for the question, then answer the question using the recitation.
- Self-consistency ensemble: recite multiple passages instead of one using top-k sampling, each passage leads to an answer, the final answer is decided via majority vote.
- Multiple-recite-and-answer: recite multiple passages, then concatenate them and output a single answer based on the concatenation.
- Passage hint-based diversified recitation: solution to hallucinating wrong recitation while ensuring enough diversity of generated recitations, this method proposes to recite the “hint” first which then serves as a guide to recite the associated passage appropriately. In Wikipedia, the hint of a section can be the concatenation of page title + section title.
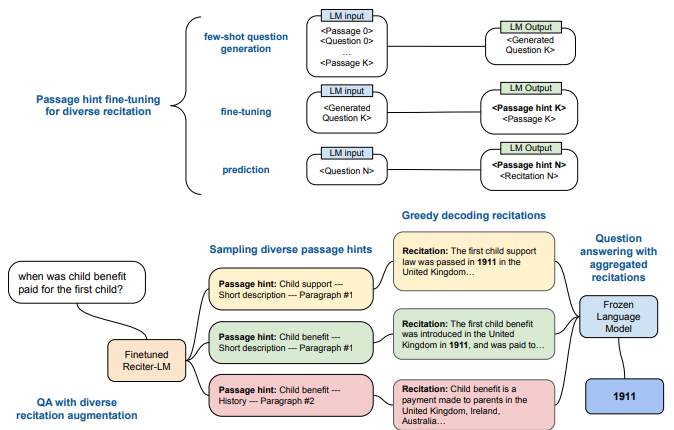
(source: copied from the paper).
Ablation studies shows RECITE improves when number of recitations increases, and is robust to the prompt’s demonstration.
-
REPLUG: Retrieval-Augmented Black-Box Language Models (Shi et al., arxiv 2023)
REPLUG (Retrieve and Plug) takes another approach in retrieval-augmented LM where the LM is a black-box (hence, unknown parameters and impossible to retrain/finetune) and the retriever is either frozen or trainable. This characteristic makes REPLUG particularly flexible that it can be used with any existing LLM (yes, only large LM (>100B parameters)).
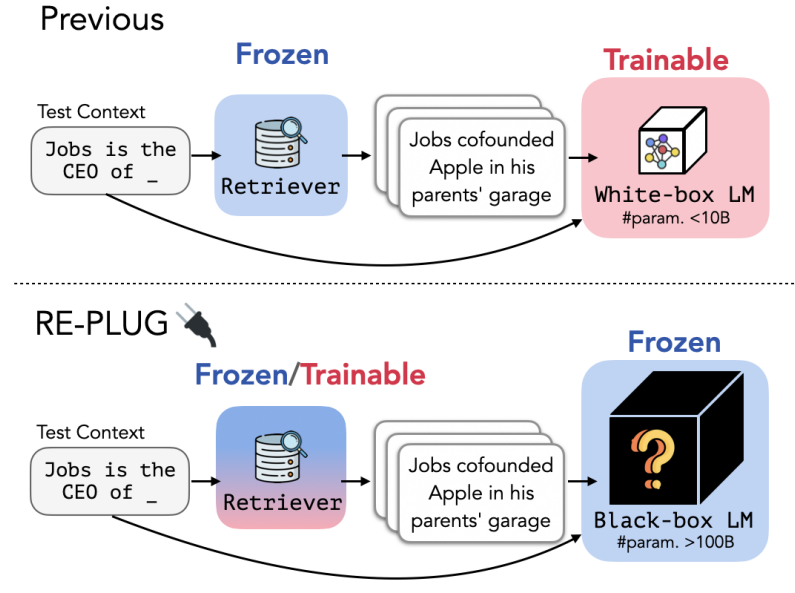
(source: copied from the paper).
The architecture of the retriever is almost the same for every retrieval-augmented LMs. It is based on dual-encoder to compute top-k documents for the input query in the embedding space. If the retriever is trainable, we then have REPLUG LSR (REPLUG with LM-Supervised Retrieval). Similarly to Atlas’s Perplexity Distillation training objective, the retriever is trained to predict how much each retrieved document would improve the black-box LM perplexity, conditioned on the query. The LM perplexity scores are normalized (via softmax) and are then distilled into the retriever to encourage the documents yielding the higher LM perplexity.
The black-box LM takes in both the input query and every retrieved document, producing a probability distribution. These distributions are combined using an ensemble method to form the final probability distribution.
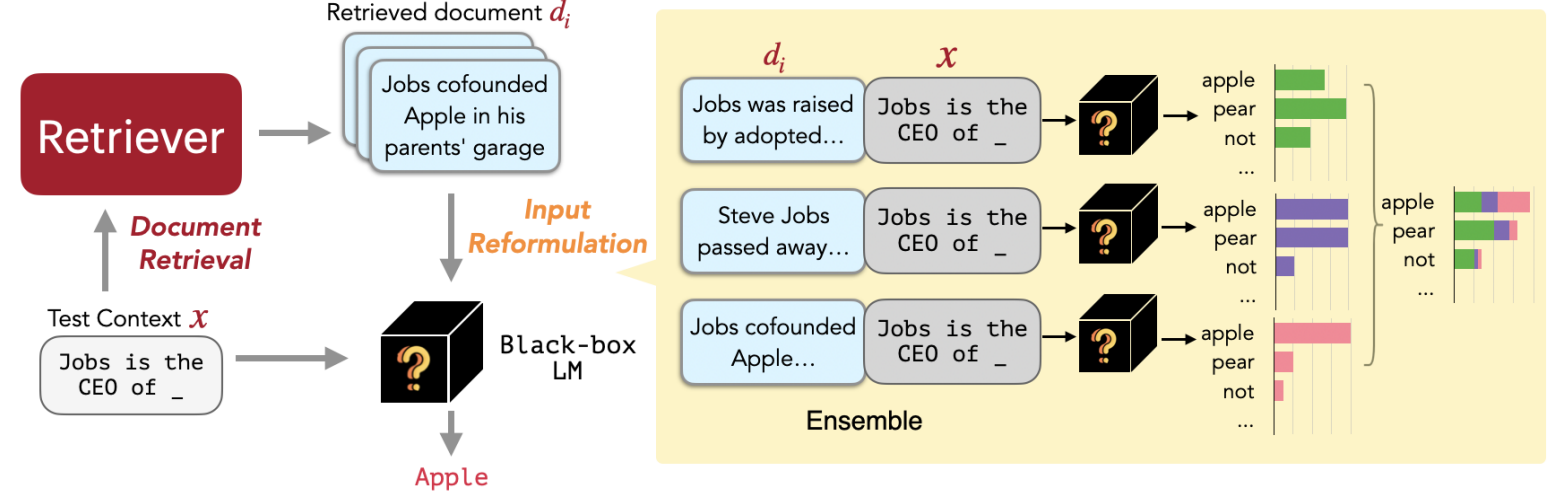
(source: copied from the paper).
REPLUG can benefit rare entities.
-
Rethinking with Retrieval: Faithful Large Language Model Inference (He et al., arxiv 2023)
The knowledge stored in the LM’s parameters may inevitable be incomplete, out-of-date or incorrect. The paper proposes rethinking with retrieval (RR), a simple post-preprocessing method that uses the a diverse set of reasoning steps obtained from the chain-of-thought prompting to retrieve relevant knowledge from external sources, to improve the the explanation, thereby, the prediction of LLMs. This approach require no additional training or finetuning and is not limited by the input length of LLMs.
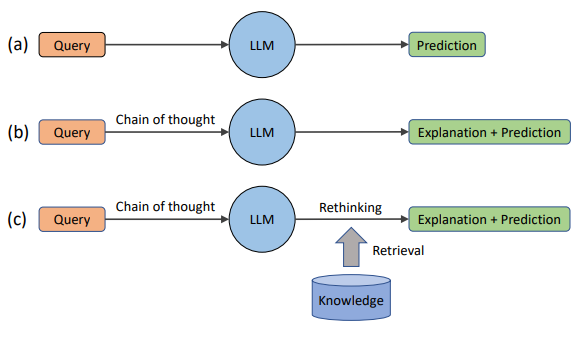
(source: copied from the paper).
Specifically, for each sentence in each reasoning path, a retriever (e.g. BM25) is employed to retrieve the top-K most relevant paragraph from an external knowledge source (e.g. Wikipedia). Then, each sentence is assigned three scores:
- semantic similarity score: calculated by the maximum cosine similarity between the sentence embeddings of retrieved paragraphs and the sentence.
- entailment score and contradiction score: use a NLI model to calculate those scores assuming the most similar paragraph (according to above semantic similarity) as the premise and the sentence as the hypothesis.
The faithfulness of a reasoning path is computed using the scores of all sentences in the path. To arrive at final prediction, priority is given to the reasoning paths that exhibit higher levels of faithfulness.
rethinking with retrieval (RR) outperforms chain-of-thought prompting even when using smaller LMs.
-
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions (Trivedi et al., ACL 2023)
Interleaving Retrieval with Chain-of-Thought (IRCoT) interleaves a knowledge retriever at each reasoning step obtained from chain-of-thought (CoT) prompting to mutually guide the retrieval by CoT and vice-versa. This strategy allows to retrieve more relevant supports for later reasoning steps in the reasoning path, thereby, enhance the answer for complex multi-step reasoning question.
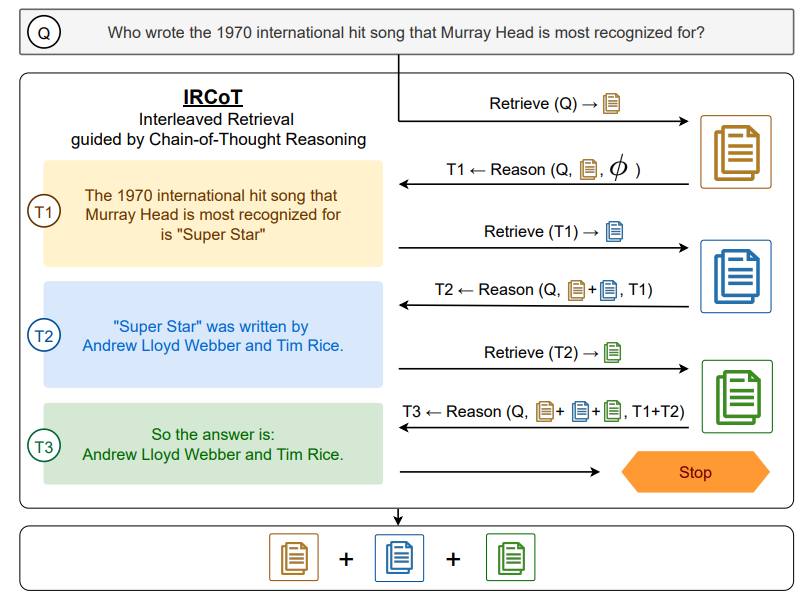
(source: copied from the paper).
IRCoT follows \(\textsf{retrieve-and-read}\) mechanism:
- \(\textsf{retrieve}\) step: perform interleavingly and iteratively two sub steps until the termination criterion (e.g. the phrase “the answer is” is generated in the reasoning path) is met:
- CoT-guided retrieval step (“retrieve”): using the last generated CoT sentence in the reasoning path as a query to retrieve relevant support paragraph from external knowledge source.
- Retrieval-guided reasoning step (“reasoning”): using the question, the paragraphs collected so far and the CoT sentences generated so far to generate the next CoT sentence in the reasoning path.
-
\(\textsf{read}\) step: all the support paragraphs collected from the \(\textsf{retrieve}\) step are appended to the CoT prompting as the context, asking LLM to generate the answer. The prompting template can appear like:
Wikipedia Title: <Page Title> <Paragraph Text> ... Wikipedia Title: <Page Title> <Paragraph Text> Q: <question> A: <CoT-Sent-1> ... <CoT-Sent-n>IRCoT has shown some remarkable benefits:
- IRCoT retriever outperforms (with higher recall) one-step retriever that relies solely on the question as query.
- IRCoT is also effective for smaller LMs (e.g. T5-Flan-large 0.7B). IRCoT for QA based on Flan-T5-XL (3B) even outperform GPT3 (175B) with no retriever or on-step retriever.
- Although IRCoT retriever (\(\textsf{retrieve}\) step) can itself produce the answer from its last generated CoT sentence, the \(\textsf{read}\) step where a separate QA reader is employed to consider all collected support paragraphs together is still necessary, since it yields much better accuracy.
- \(\textsf{retrieve}\) step: perform interleavingly and iteratively two sub steps until the termination criterion (e.g. the phrase “the answer is” is generated in the reasoning path) is met:
2022
-
Transformer Memory as a Differentiable Search Index (Tay et al., Neurips 2022)
Traditional Information retrieval (IR) system involves retrieve-then-rank mechanism: (i) given a query, \(k\) nearest documents are retrieved from an indexed corpus, (ii) retrieved documents are then sorted. The paper presents the Differentiable Search Index (DSI), a new paradigm for learning an end-to-end search system where the retrieve phase and the rank phase are performed within a single seq2seq neural model (e.g. T5, BART). It is shown with an appropriate design for {document representation, document identifier representation, document indexing strategy, training strategy}, DSI can obtain significant gain over state-of-the-art baselines (dual encoder, BM25):
- Document representation: a document is represented by its first \(L\) tokens.
- Document identifier representation: a document can be tagged by an unique integer, or unique \(tokenizable\) string, or semantically structured identifiers.
- Documents are indexed by training a Seq2Seq model to learn the mapping \(\textsf{doc_tokens} \rightarrow \textsf{docid}\). In other word, this task makes the model memorize which document corresponds to which identifier.
- At the same time, the model is jointly trained (under multi-task learning, similarly to T5 training style) with (\(\textsf{query, docid}\)) samples, so that at inference time, the decoder is able to generate relevant \(\textsf{docid}\) (s) for given input query.
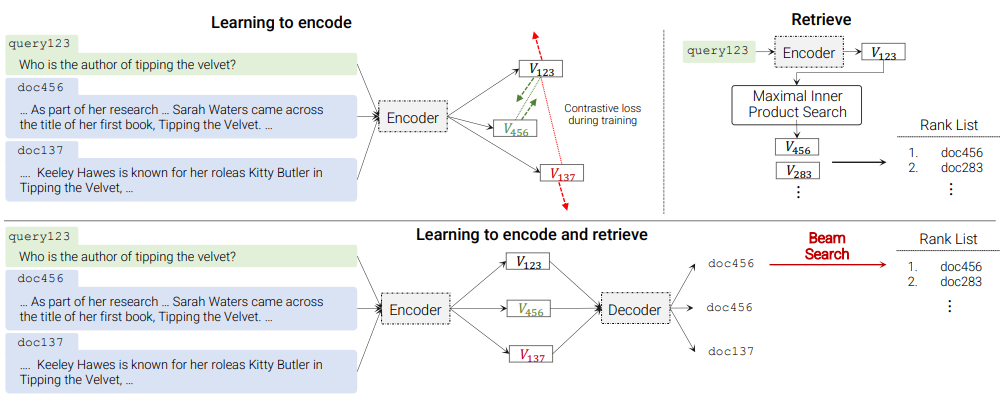
(source: copied from the paper)
In summary, the multi-task training of DSI looks like:
Input: "Document indexing: document_tokens" --> T5 --> Output: "docid" Input: "Document retrieval: query_tokens" --> T5 --> Output: "docid" -
Autoregressive Search Engines: Generating Substrings as Document Identifiers (Bevilacqua et al., Neurips 2022)
Autoregressive models has emerged as the de-facto way to address the knowledge-intensive language task (KILT). This paper suggests that this kind of model also has the capability to performance the evidence retrieval with minimal intervention to the model’s architecture. The whole evidence corpus is indexed using an efficient data structure (FM index) in the way that for a given token, we can quickly figure out all possible next tokens in the corpus. The paper introduces SEAL, an autoregressive model that can directly locate the answer as well as the document containing the answer via generation constraint on FM index, for a query. It proposes a clever scoring function combining LM’s score and token’s frequency in the corpus while taking into account the fact that a document can contain multiple supports.
Ablation studies reveal:
- SEAL can work well even with small size (~400M)
- Performance increase with a larger beam search, and seems to start decreasing when the beam reaches between 10 and 15.
- Decoding maximum length is a crucial factor, where longer output sequence is more informative than shorter one.
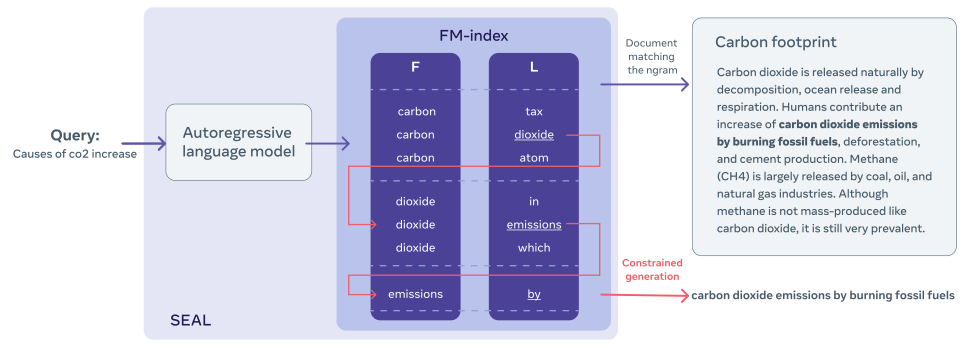
(source: copied from the paper)
-
Atlas: Few-shot Learning with Retrieval Augmented Language Models (Izacard et al., arxiv 2022)
Medium LMs augmented with retrieval capability can be competitive with (or even outperform) LLMs in few-shot learning while being much more parameter-efficient. Atlas consists of a retriever and a LM that are jointly learnt with a focus on the ability to perform various knowledge intensive tasks with very few training examples.
-
Retriever: initialized from a BERT-based dual-encoder pre-trained with contrastive loss.
-
LM: all tasks are casted as text-to-text. The model is initialized from the T5-1.1-lm-adapt (trained on unlabeled text only + trained with LM objective) variants.
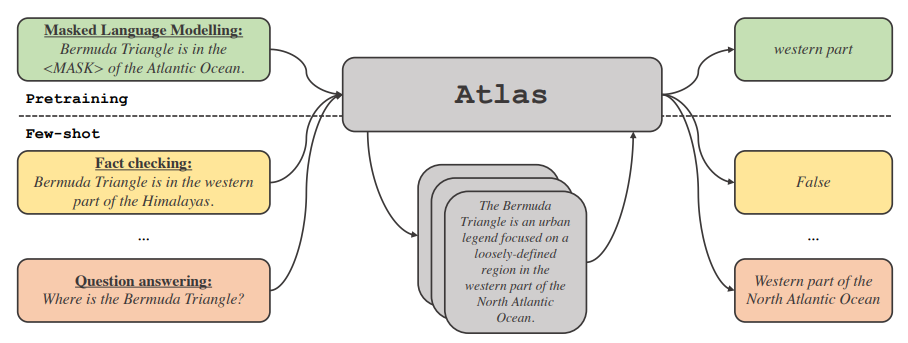
(source: copied from the paper)
Before fine-tuning with few-shot examples, the retriever and the LM are jointly pretrained with a set of objectives:
-
Attention Distillation (ADist): the cross-attention scores between the input documents and the output are distilled into the retriever to encourage the retrieval of documents of higher scores.
-
End-to-end training of Multi-Document Reader and Retriever (EMDR2): minimize the loss (similar to REALM):
\[log \sum_{z \in Z}{ p_{LM} (x | q, z ) * p_{retriever} (z | q) }\]where \(q\) is the input query, \(x\) is the output, and \(z\) is retrieved documents, playing as latent variable.
-
Perplexity Distillation (PDist): train the retriever to predict how much each retrieved document would improve the LM perplexity, conditioned on the query. The LM perplexity scores are normalized (via softmax) and are then distilled into the retriever to promote the documents yielding the higher LM perplexity at later stage.
-
Leave-one-out Perplexity Distillation (LOOP): if removing one of the retrieved documents, how much it affects the prediction of the LM.
-
Prefix language modelling: divide the sentence into two parts, taking first part as input and predicting the second part.
-
Masked language modelling: similar to T5.
The experimentation show Perplexity Distillation and Mask language modelling to be more stable than other objectives.
As retriever’s parameters are updated every training step, re-calculating the embedding and re-indexing the whole collection of documents is significantly computationally expensive (or even impossible), Atlas propose several efficient index update: (i) re-indexing the collection of document embedding every \(k\) epoch; (ii) instead of re-indexing the whole collection, only perform on top-k documents return; or (iii) freeze the index of documents.
A remarkable feature of retrieval-augmented model is that their knowledge can be kept up-to-date without retraining, by simply maintaining a collection of documents. -
-
EIDER: Empowering Document-level Relation Extraction with Efficient Evidence Extraction and Inference-stage Fusion (Xie et al., ACL Findings 2022)
EIDER: Extracted Evidence Empowered Relation Extraction
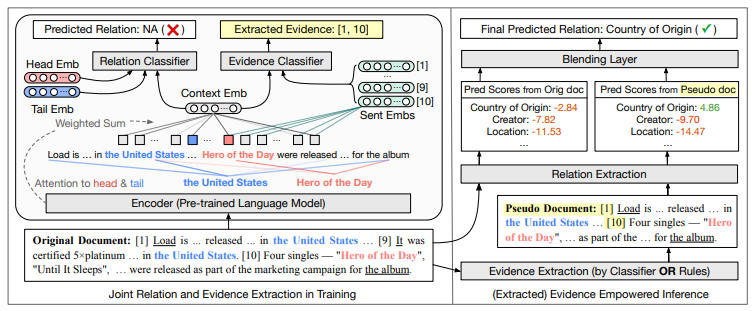
(source: copied from the paper)
Typical document-level relation extraction models rely on the whole document to infer the relation of an entity pair in the document. On the one hand, a minimal set of sentences (i.e. evidences) in the documents is enough for human to annotate the relation, taking the whole document as input may add noise and ambiguity to the model. On the other hand, there is no way to extract such minimal set perfectly, leading to missing important information. EIDER alleviates both aspect by introducing:
- Joint training of relation extraction end evidence sentence extraction: a base encoder is employed to learn the representation of the relation from the counterparts of the head entity, tail entity and the whole document \(p(r \mid e_h, e_t, c_{h,t})\), as well as to learn the representation of each evidence sentence \(s_n\) given the head and tail entity \(p (s_n \mid e_h, e_t)\). For the training, evidence sentences for each entity pair in a document can be either manually provided, or extracted using simple heuristics (e.g. a sentence containing both head and tail entities is considered as an evidence for this entity pair).
- Fusion of evidence in Inference: the score of each candidate relation is given by two inferences: one with the prediction from the whole documents, one with the prediction from the set of extracted evidence sentences (a subset of original document). \s
-
Don’t Prompt, Search! Mining-based Zero-Shot Learning with Language Models (van de Kar et al., EMNLP 2022)
\(\textsf{Generate-filter-finetune}\) approach for zero-shot learning
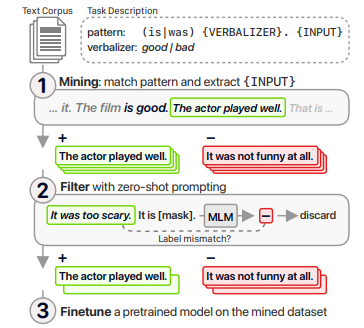
(source: copied from the paper)
The paper introduces a retrieval augmented zero-shot learning method which is more flexible and interpretable than prompting methods. The present method is reliant on an unlabeled corpus playing as knowledge source (e.g. the corpus used for pretraining), a regex-like mining pattern and a set of verbalizer that represents a downstream task (similar to prompting), such as \(\textsf{(is} \mid \textsf{was) \{VERBALIZER\}*. \{INPUT\} }\) for sentiment analysis where \(\textsf{VERBALIZER} \in\) \(\textsf{\{good, great, awesome, etc\}}\) for positive label and \(\textsf{\{bad, awful, terrible, etc\}}\) for negative label. It consists of 3 steps:
- Using the regex-based mining pattern to extract training samples from the unlabeled corpus. For example, given the pattern above, the sentences following “is good” or “was good” are examples of the positive class, and the sentences following “is bad”, “was bad” are examples of the negative class.
- As mined samples can be noisy, they are filtered by zero-shot prompting. Specifically, samples in which predicated label by zero-shot prompting and the mined label do not match will be removed.
- The mined dataset is then used to finetune a pretrained LM for the downstream task. Intuitively, the original zero-shot learning is casted as full finetuning with the help of mined dataset.
Experimented on sentiment analysis, topic classification and NLI tasks, mining approach outperforms zero-shot prompting method when using the same verbalizers and comparable patterns. It can partly explain the performance of prompting method using the fact that many task-relevant examples are seen during the training which can be explicitly retrieved through simple regex mining pattern.
-
SKILL: Structured Knowledge Infusion for Large Language Models (Moiseev et al., NAACL 2022)
The paper introduces SKILL a simple way to inject knowledge from structured data, such as a KG, into a language model, that can benefit knowledge-retrieval-based downstream tasks. SKILL continue to pretrain LLM directly on structured data (e.g. triples in KG) with salient-term masking without synthesizing them into equivalent natural sentences (e.g. KELM) as they found that the two approaches are competitive with each other.
SKILL demonstrates better performance than original LMs on Wikidata-related QA benchmarks as it is pre-trained on Wikidata triples. Most of the gains comes from the ability to memorize KG triples during the training. As a consequence, the model can perform very well on 1-hop questions that are supported by single triples, such as “When was Elon Musk born ?” corresponds to the triple <Elon Musk, date of birth, ?>. However, when it comes to answering multi-hop questions (e.g. “Who worked at the companies directed by Elon Musk ?” may correspond to two triples <Elon Musk, owner of, ?x> and <?y, employer, ?x> ) which requires not only the memorizing ability but also the reasoning ability, SKILL performs just slightly better than original LMs. The author points out one limitation of SKILL is that the training relies on a random set of independent triples, lacking of topological structure exploitation of a KG describing how triples are connected. Addressing this issue can improve the multi-hop QA tasks.
2021
-
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (Izacard et al., EACL 2021)
Retrieved evidence fusion in decoder (Fusion-in-Decoder).

(source: copied from the paper)
To address the Open Domain Question Answering, firstly, an independent knowledge retriever is leveraged to retrieve supporting passages for the input question, then, a seq2seq model (T5) takes as input the combination of the input question and supporting passages to produce the answer. Specifically, each retrieved passage concatenated with the input question is independently encoded by the encoder and their representations are merged together before sending to the decoder, in this way, the decoder can attend over the whole set of retrieved potential evidences and rely on them to generate the answer. There are two advantages of this fusion-in-decoder method:
- Avoid encoding all retrieved passages and the input question in one place which is very costly due to significant lengths of the passages.
- Thanks to the first point, we can efficiently increase the number of retrieved support passages, leading to the higher accuracy in the answer.
2020
-
REALM: Retrieval-Augmented Language Model Pre-Training (Guu et al., ICML 2020)
Knowledge Retriever jointly pre-trained with LM.
BERT-style LM is pre-trained to denoise a corrupted input sentence \(\hat{x}\) by predicting the masked tokens [MASK] in \(\hat{x}: p(x| \hat{x})\). For example, given “The [MASK] is the currency of the United Kingdom” as \(\hat{x}\), then the answer for [MASK] is “pound”. REALM makes the prediction more interpretable by first retrieving possibly helpful documents \(z\) (\(z\) plays as latent variable) from a knowledge source \(Z\) and using them (as evidences) to support the prediction of [MASK], as following:
\[p(x \mid \hat{x}) = \sum_{z \in Z}{ p (x | \hat{x}, z ) * p (z | \hat{x}) }\]\(p (x \mid \hat{x}, z )\) helps to inform which documents \(z\) contribute the most to [MASK] tokens. The knowledge retriever \(p_{\theta}(z \mid \hat{x})\) and knowledge-augmented encoder \(p_{\phi}(x \mid \hat{x}, z )\) are modelled separately using two different BERT\(_{\theta}\) and BERT\(_{\phi}\). Document \(z\) is represented by its title and body. \(p_{\theta}(z \mid \hat{x})\) involves the cosine similarity between the sentence embedding produced by BERT\(_{\theta}\) of \(\hat{x}\) and \(z\). During the pre-training, the marginal \(p(x \mid \hat{x})\) requires a summation over all documents \(z\) in \(Z\) which is very costly. Also, as \({\theta}\) changes every training step, hence the embeddings Emb(z) of all documents \(z\) in \(Z\) need to be recalculated every step \(\rightarrow\) sound impossible. To deal with these issues, REALM proposes two training strategies
- \(p_{\theta}(z \mid \hat{x})\) is marginalized over only top-K documents \(z\) instead of all. Top-K relevant documents \(z\) w.r.t. input \(\hat{x}\) can be efficiently performed by Maximum Inner Product Search (MIPS) algorithm where the embeddings of \(z\)(s) are pre-computed and pre-indexed.
- The Emb(z) are freezed for an amount of time and are only re-calculated every several hundred update step.
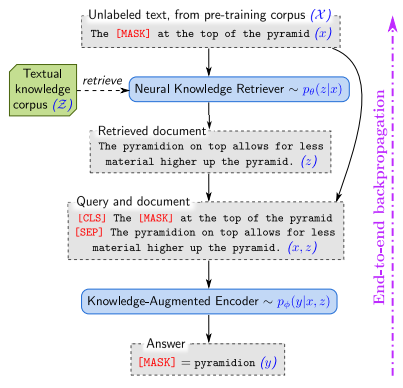
(source: copied from the paper)
Regarding the training setting, the model is trained using masked-language modelling. They found that masking salient terms instead of masking random span could significantly improve the performance on downstream tasks.
-
Generalization through Memorization: Nearest Neighbor Language Models (Khandelwal et al., ICLR 2020):
The paper hypothesizes that the representation learning problem may be easier than the prediction problem. For example, two sentences Dickens is the author of and Dickens wrote will essentially have the same distribution over the next word, even if they do not know what that distribution is. Given a sequence of tokens \(x = (w_1,...,w_{t-1})\), \(k\) nearest neighbors \(\mathcal{N}\) of \(x\) is retrieved from a pre-built catalog \(\mathcal{C}\) by comparing the sentence embedding of each sequence in Eclidean space. Each nearest neighbor \(x_i\) of \(x\) has a next token \(y_i\): \((x_i, y_i) \in \mathcal{N}\). The distribution of the next token \(y\) of \(x\) can be estimated via a simple linear regression: \(p_{kNN} (y \mid x) = \sum_{(x_i, y_i) \in \mathcal{N}} softmax (\mathbb{1}_{y=y_i} exp (-d (\textsf{Emb}(x), \textsf{Emb}(x_i))))\).
The LM distribution of a token \(y\) \(p_{LM} (y \mid x)\) given \(x\) is then updated by the nearest neighbor distribution \(p_{kNN} (y \mid x)\): \(p (y \mid x) = \lambda p_{kNN} (y \mid x) + (1-\lambda) p_{LM} (y \mid x)\).
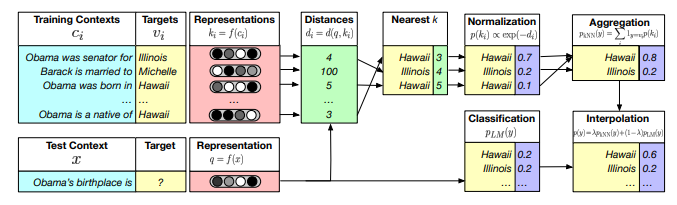
(source: copied from the paper)
Several advantages of nearest neighbor LM:
- No additional training required.
- Long-tail patterns can be explicitly memorized in the pre-built catalog \(\mathcal{C}\) instead of encoded implicitly in model parameters. New domain can be adapted to LM by creating a new catalog for the target domain dataset.
- \(k\) nearest neighbor search in the embedding space of word sequences can be efficiently done using FAISS index.
2. Information Extraction
2023
-
How to Unleash the Power of Large Language Models for Few-shot Relation Extraction? (Xu et al., SustaiNLP@ACL 2023)
-
GPT-RE: In-context Learning for Relation Extraction using Large Language Models (Wan et al., arxiv 2023)
-
Universal Information Extraction as Unified Semantic Matching (Lou et al., AAAI 2023)
-
StructGPT: A General Framework for Large Language Model to Reason over Structured Data (Jiang et al., arxiv 2023)
-
GPT4Graph: Can Large Language Models Understand Graph Structured Data? An Empirical Evaluation and Benchmarking (Guo et al., arxiv 2023)
The paper presents a graph understanding benchmark to evaluate the capability (0-shot and 1-shot) of LLM (i.e. InstructGPT3,5) in comprenhending graph data. The benchmarking tasks are classified into 2 categories: structure understanding and semantic understanding, as below:
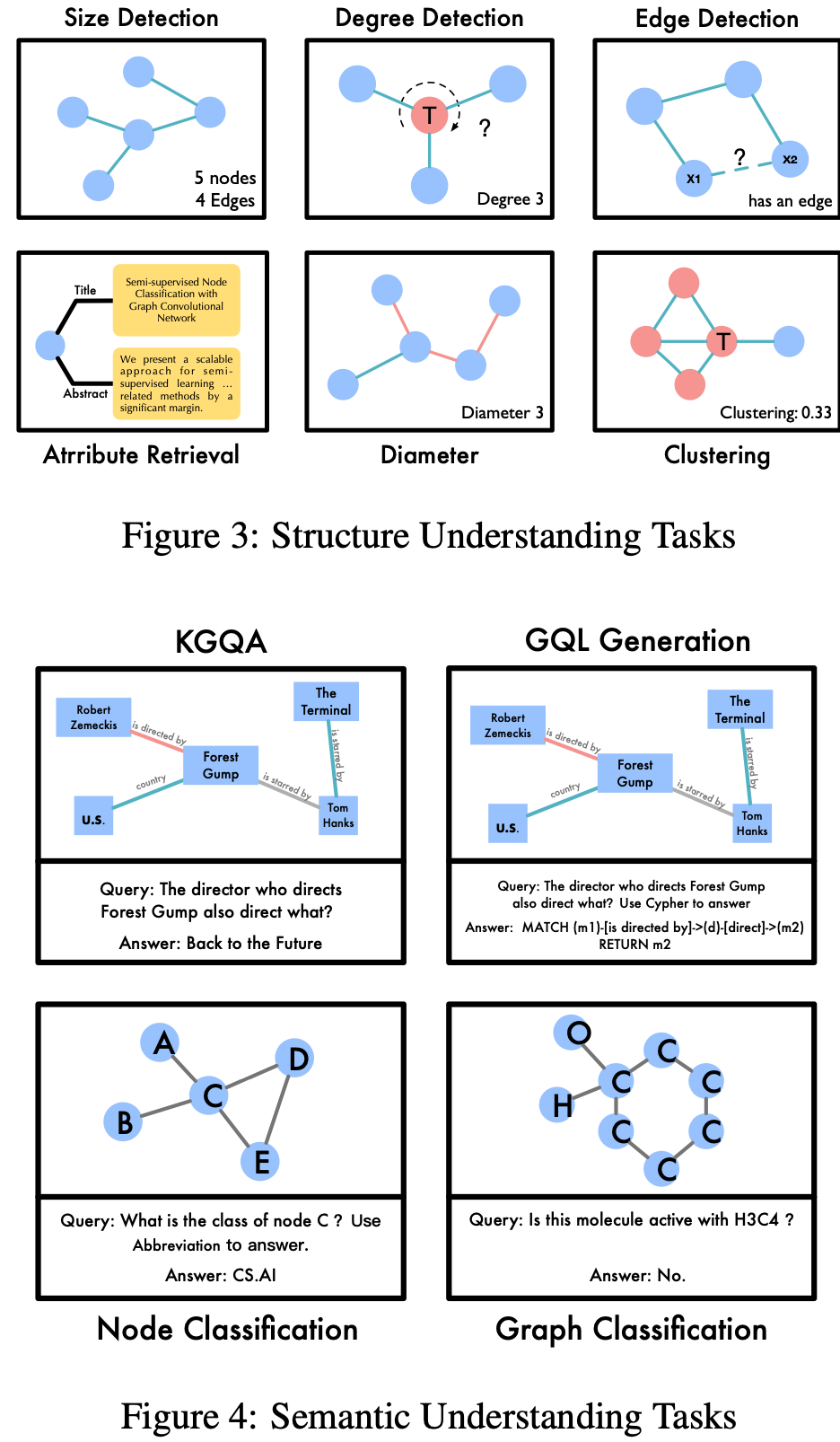
(source: copied from the paper)
Several findings:
- Input design (e.g. order of graph and question, format explaination) has a significant impact.
- Role prompting is beneficial: explicitly ask the model to summarize the graph, then use it as new context, combine with initial prompt for the target task.
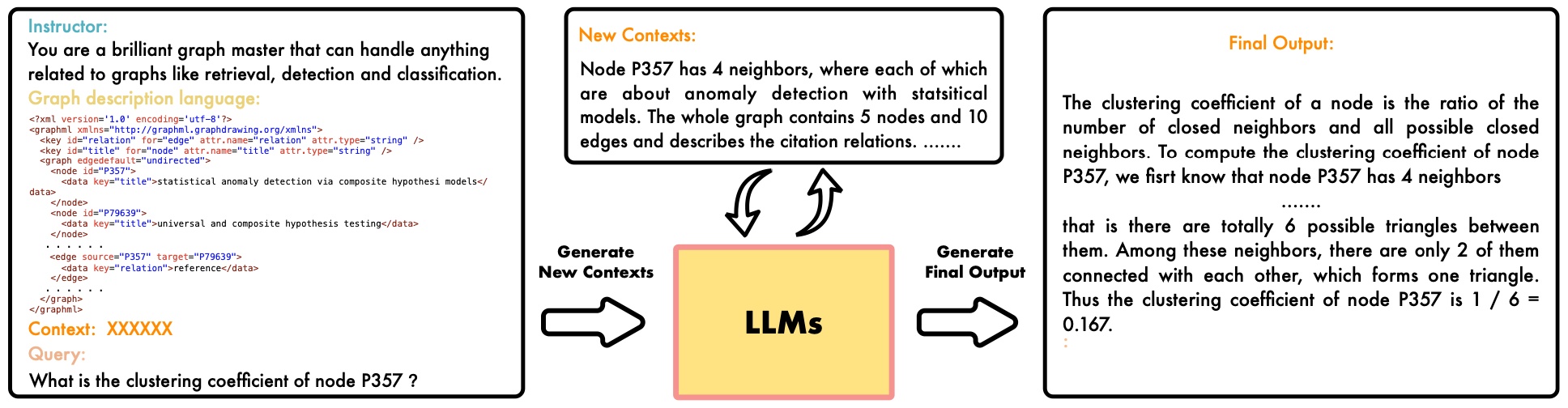
(source: copied from the paper)
-
NEUROSTRUCTURAL DECODING: Neural Text Generation with Structural Constraints (Bastan et al., ACL 2023)
NeuroStructural Decoding is a new beam-search based decoding scheme in generative LLMs that guides the model to follow given structural constraints when generate the output.
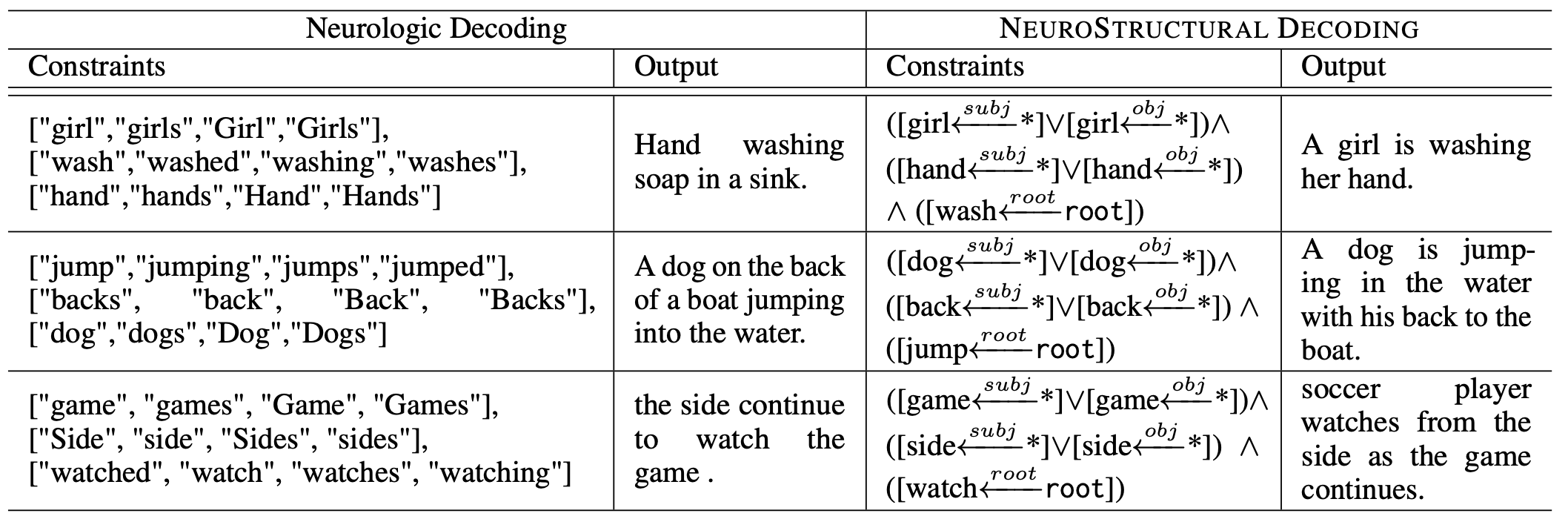
(source: copied from the paper)
Structural constraints considered in this work are classified into three types:
- Unary Constraint: constraints the role of a single word in generated text such as D = (ball, obj): the word ball should appear as an object of some verb.
- Binary Constraint: constraints the relation between two words such as D = (team, subj, run): the word team should be the subject of the word run.
- Triplet Constraint: a triplet, such as D = (team, run, field) should appear in the generated text.
At each decoding step, the score of a token is modified as: \(P_{\theta} (y | x) - \lambda \sum_{i=1}^{k} ( 1 - C_i)\) where the second term pernalizes the token that does not satisfies a clause \(i\) consisting of disjunctive constraints (\(C_i = 0\)), if sastified, \(C_i = 1\).
To effectively search for relevant tokens in a beam at each decoding step, NeuroStructural Decoding tracks the states of each clause, whereby prune the paths that irreversibly violate a constraint or group paths that share irreversiby satisfied clauses. To evaluate whether partially generated text holds a syntactic constraint, it needs a syntactic parser that is capable of parsing incomplete sentence. To this end, author continues to train a dependency parser on incomplete sentence to improve its performance on such pattern.
-
Retrieval-Enhanced Generative Model for Large-Scale Knowledge Graph Completion (Yu et al., SIGIR 2023)
ReSKGC is a retrieval-augmented generative model for KG completion. It consists of two steps:
- retrieval: the KG’s triplets and input tripet with to-be-predicted object (s, p, ?) is linearized into text (see figure below). Then, the input is used to retrieve $k$ relevant KG’s linearized triplets using non-parametric retriever BM25.
- fusion-in-decoder (FiD): a FiD is employed to encode efficiently the concatenation of retrieved passages and the input, whereby generate the missing object in the triplet (s, p, ?). ReSKGC attains the new sota performance on Wikidata5M and WikiKG90Mv2 benchmarks.
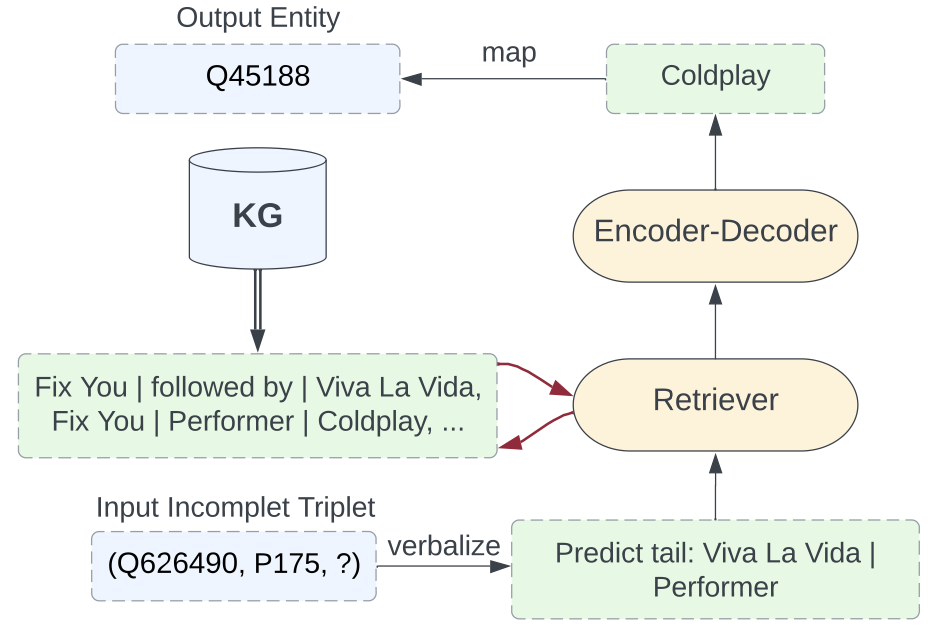
(source: copied from the paper)
-
Knowledge Base Completion for Long-Tail Entities (Chen et al., arxiv 2023)
MALT is a dataset for KB completion that focuses on long-tail entities and is extracted from Wikidata. Long-tail entities are defined as being involved in less than 14 triples in KG. The dataset contains 3 entity types (i.e. business, musicComposition and human) and 8 associated predicates such as foundedBy, placeOfBirth.
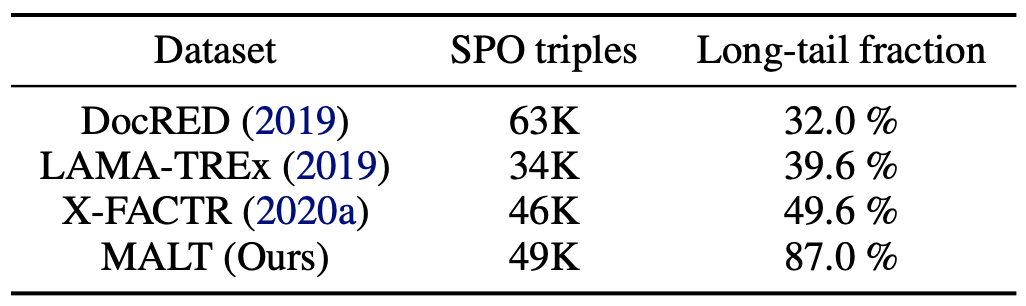
(source: copied from the paper)
-
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction (Wang et al., arxiv 2023)
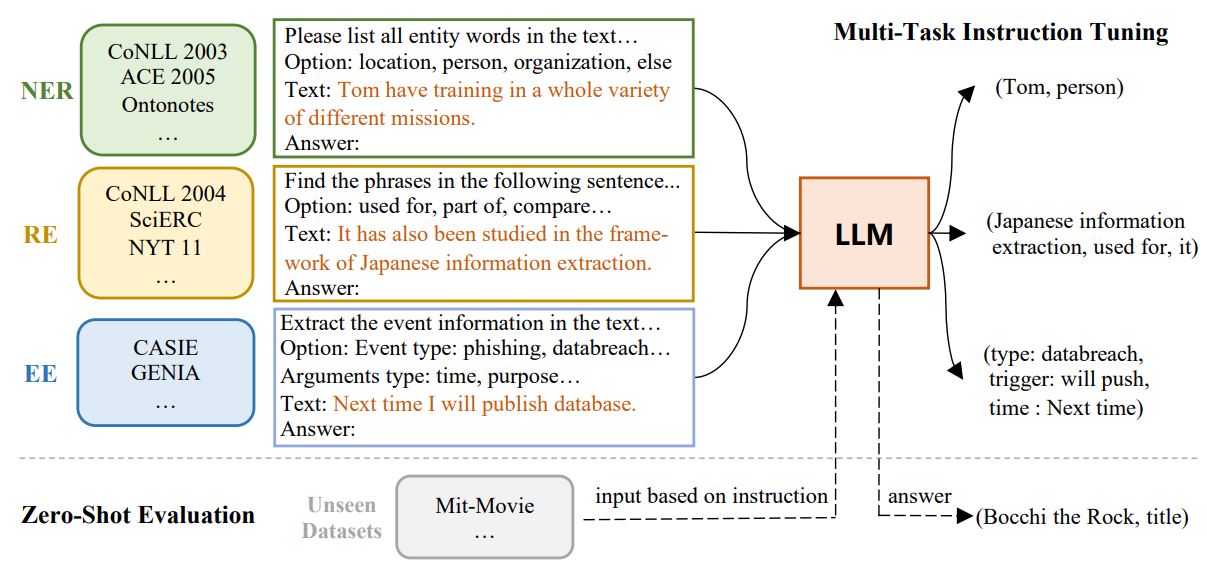
(source: copied from the paper)
InstructUIE gathers 32 public datasets covering three IE tasks: NER, RE, EE and transform each sample in each dataset into text-2-text-with-instruction format (see figure above). They then fine-tune a FLAN-T5 11B on those datasets. InstructUIE demonstrates better performance than UIE and USM on in-domain test set and than GPT-3-davinci or ChatGPT (for RE task) on out-of-domain test set.
-
Unifying Molecular and Textual Representations via Multi-task Language Modelling (Christofidellis et al., ICML 2023)
-
Triggering Multi-Hop Reasoning for Question Answering in Language Models using Soft Prompts and Random Walks (Misra et al., Findings ACL 2023)
LM can perform well with KG-based one-hop Q/A thanks to its ability to memorize injected triples. However, for two-hop Q/A, the model finds difficult to combine separate triples that supports the question to arrive at the correct answer. This paper improves the two-hop Q/A by exposing the model to two-hop predicate paths explicitly. This is done through several tuning based on T5, resulting KNowledge-Integrated T5 (KNIT5):
- Knowledge Integration: given a triple (s,p,o), model is tuned to predict o given s and p.
- Two-hop Knowledge Integration: given two triples (s1, p1, o1) and (o1, p2, o2), model is prefix tuned to predict o2 given s1, p1, o1, p2.
- Either of the two prefix tuning methods below is considered
- Parse-the-Hop: consists of two steps: (i) given input question, model is tuned to parse the question into a two-hop path (s1, p1, o1, p2); (ii) model then predict the answer o2 given (s1, p1, o1, p2).
- MixHop: jointly tune the two steps.
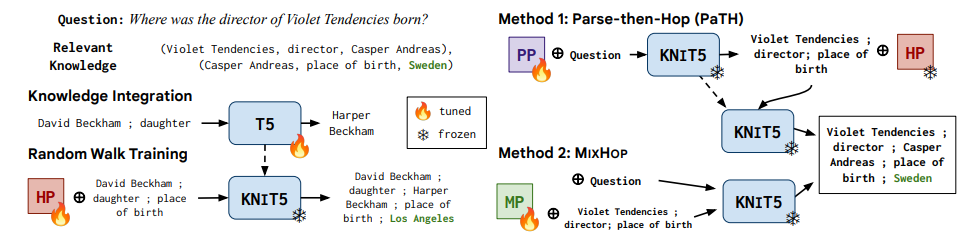
(source: copied from the paper)
The above training paradigm shows to improve substantially the 2-hop capabilities of LMs, but mostly in large LMs. (e.g. T5-XXL).
-
Flexible Grammar-Based Constrained Decoding for Language Models (Geng et al., arxiv 2023)
-
Methods for Measuring, Updating, and Visualizing Factual Beliefs in Language Models (Hase et al., EACL 2023)
-
Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge (Onoe et al., ACL 2023)
This work investigates whether LM can add a new entity through entity’s description, propagate this information and performance inference on the new entity.

(source: copied from the paper)
Different from works on injecting facts into LM, where the inference is usually based on the paraphrasing version of injected facts (e.g. upper part of the image above), this work involves higher level of inference complexity, which requires the model learn/propagate new entities from their definitions, and evaluate diverse facts around the new entities. A few examples can be found in the table below:
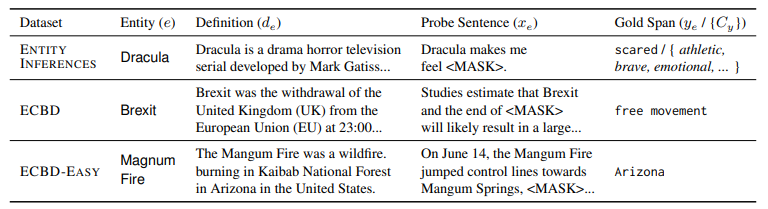
(source: copied from the paper)
Evaluation metrics for the inference on injected entities:
- Update success: accuracy or perplexity (i.e updated model should have lower perplexity on facts related to new entities)
- Specificity: the entity injection should not impact the existing facts that do not relate to new entities. Or, the perplexity on those facts should not be increased.
Findings: (i) full fine-tuning approach can work effectively on controlled benchmark (LM does not predict an answer for a probe, but instead choose an answer from a set of candidates) , but it comes at the cost of increasing the specificity.; (ii) finetuning for longer does not necessarily propagate the entity’s information into the model; (iii) for more realistic benchmark which require higher level of reasoning/inference, none of model editting techniques improve the update success while keeping specificity stable. Furthermore, author found that such techniques only work when there is lexical overlap between the target inference and the definition of injected entity (e.g. answer span contained in the definition).
-
DEMONSTRATE–SEARCH–PREDICT: Composing retrieval and language models for knowledge-intensive NLP (Khattab et al., arxiv 2023)
-
CODEIE: Large Code Generation Models are Better Few-Shot Information Extractors (Li et al., ACL 2023)
Code language model (i.e. model trained on code, among other things) has been discovered that it has better capability to deal with the generation of structured output (e.g. graph, rdf triplet, dictionary…), as code has also structure. Natural-text LM needs to serialize the structured output as plain text, which is very different from what it saw during the pretraining, making the inference difficult.
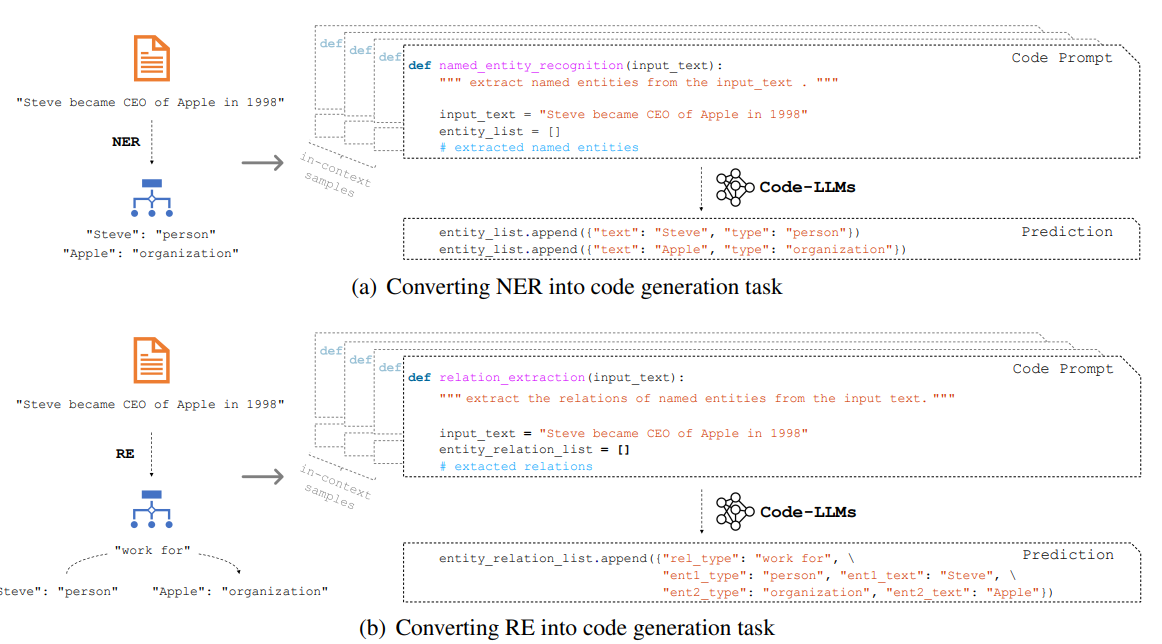
(source: copied from the paper)
This paper employs a code-LLM (i.e. OpenAI’s Codex) to perform few-shot information extraction (NER and RE). The prompting templates for two tasks are described in the figure above. The results show that:
- Code-style prompt is better than plain-text prompt
- CodeLM has better few-shot performance (even with plain-text prompt) on information extraction tasks than text-LM.
- Code-style prompt with CodeLM yields lower structural error rate. In other words, it can generate the output with correct format.
-
Evaluating Language Models for Knowledge Base Completion (Veseli et al., ESWC 2023)
Previous benchmarks for LM-based Knowledge Base Completion tends to be biased toward popular entities, leading to an overestimate of the completion performance of LM. This paper proposes WD-Know, a new benchmark to address this issue. It relies on Wikidata to extract facts via randomly and equally sampling entities. The new benchmark reveals that the completion accuracy of LM is not equal across relations. While LM achieves high precision and good generalization for language-related and socio-demographic relations (e.g. citizenOf, headquarteredIn), non-socio-demographic relations (e.g. producedBy) may require the fact to be present explicitly (retrieve rather than generalize).
-
Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction (Josifoski et al., arxiv 2023)
Author points out that the lack of a large, balanced, high quality training dataset has been a important obstacle for the success of close Information Extraction (cIE). Indeed, previous datasets exposes several problems: (i) skewness: rare relations/subjects/object appear only a few times. Most models perform poorly on these entities; (ii) noisy: target output does not always contain all the facts conveyed in the input. For these reasons, author proposes to generate a synthetic balanced dataset with the help of LLM. Specifically, LLM is asked to generate text describing a knowledge subgraph fed as input.
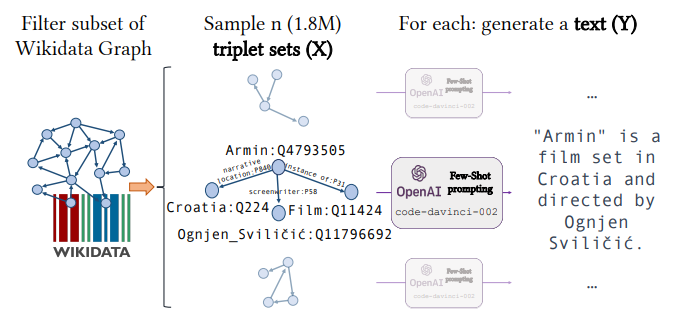
(source: copied from the paper)
They then train a FLAN-T5 on this synthetic dataset, yielding SynthIE. Experiments show SynthIE performs much better than GenIE on test synthetic dataset, but much worse than GenIE on REBEL’s test set. They argue REBEL’s test set is a poor approximation of performance.
-
Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! (Ma et al., arxiv 2023)
Through an exhaustive evaluation on multiple information extraction tasks (NER, RE, ED), the paper argues that LLM is not an effective few-shot information extractor and still lags behind well-finetuned small LMs, given enough training data. The rationales are:
- Limited number of demonstrations in in-context learning: challenging when dealing with learning problems that involves many labels.
- Author speculates that ICL has difficulty with structured prediction.
In addition, author also found that LLM can work well on samples that seem to be hard for small LMs. This motivates them to propose a hybrid model combining both small LM and LLM. Concretely, samples for which small LM yields small scores are passed to LLM to re-evaluate.
-
Understanding Fine-tuning for Factual Knowledge Extraction from Language Models (Kazemi et al., submitted to JMLR)
This study dives more deeply into the application of using language models to construct a knowledge graph. By investigating the behavior of LMs finetuned for factual knowledge extraction, the author argues that the finetuning process results both positive and negative impacts, depending on the frequency mismatch of entity appearance between the train data and the test data. They relates this issue to the well-known Out-of-distribution generalization in machine learning:
-
Positive impact: if the train and test dataset have similar entity frequency (low mismatch), the fine-tuning yields improvements for knowledge extraction.
-
Negative impact: otherwise (high mismatch), the fine-tuning is no better than zero-shot or few-shot learning due to the appearance of forgetting-related effects: Frequency Shock and Range Shift that may sometimes outweigh positive impact.
Examples of Frequency Shock are shown below:

(source: copied from the paper)
Even though both “Moscow” and “Baku” are observed an equal number of times (5) during the fine-tuning, “Baku” is less popular then “Moscow” during the pre-training of the LM \(\rightarrow\) the fine-tuned model receives a frequency shock (i.e. “Boku” shift from “unpopular” in pre-training to “as-popular-as” “Moscow” in fine-tuning), making it over-predict “Baku” (rare entity) in the test dataset.
Range Shift: finetuning makes the model tend to predict entities that are seen as answer during the fine-tuning (cold-start problem)
To alleviate the negative impact of finetuning, the paper propose two solutions: (i) ensemble models (fine-tuning + k-shot) as k-show is better than fine-tuning for high mismatch scenario; (ii) mixture training (similar to solution to catastrophic forgetting): jointly fine-tune the model with two objectives: knowledge extraction task and LM objective (e.g. MLM).
-
-
Crawling The Internal Knowledge-Base of Language Models (Cohen et al., TBD)
The paper presents LMCRAWL, a pipeline for crawling a subgraph centering around a seed entity, from LM using in-context learning with GPT-3 model.
The crawling processing is decomposed into subtasks:
- Relation Generation: generate a set of relations given subject entity. They leverage Wikidata to generate in-context examples.
- Relation Paraphrasing: generate different surface forms for a relation.
- Subject Paraphrasing: generate different surface forms for an entity.
- Object Generation: given a subject entity and a relation, generate a list of object entities. Only objects that are generated by at least two variants of the relation (via relation paraphrasing) are accepted.
- Learning to say “Don’t Know” instead of giving an erroneous fact: they simply include “don’t know” in-context examples to make the model aware of answering “don’t know” if needed.
Examples of in-context learning are shown below:

(source: copied from the paper)
2022
-
GREASELM: Graph Reasoning Enhanced Language Models for Question Answering (Zhang et al., ICLR 2022)
The paper presents GREASELM, a Graph Reasoning Enhanced LM for improving multiple choice QA. Differing from previous works, GREASELM fuses encoded representations of LM (used to encode QA context) and GNN (used to encode the KG that contains entities appearing in QA context) across multiple network layers. The information propagates from LM to GNN, and vice versa via two proxies: interaction token \(w_{int}\) appended to QA context and interaction node \(e_{int}\) appended to entity graph.
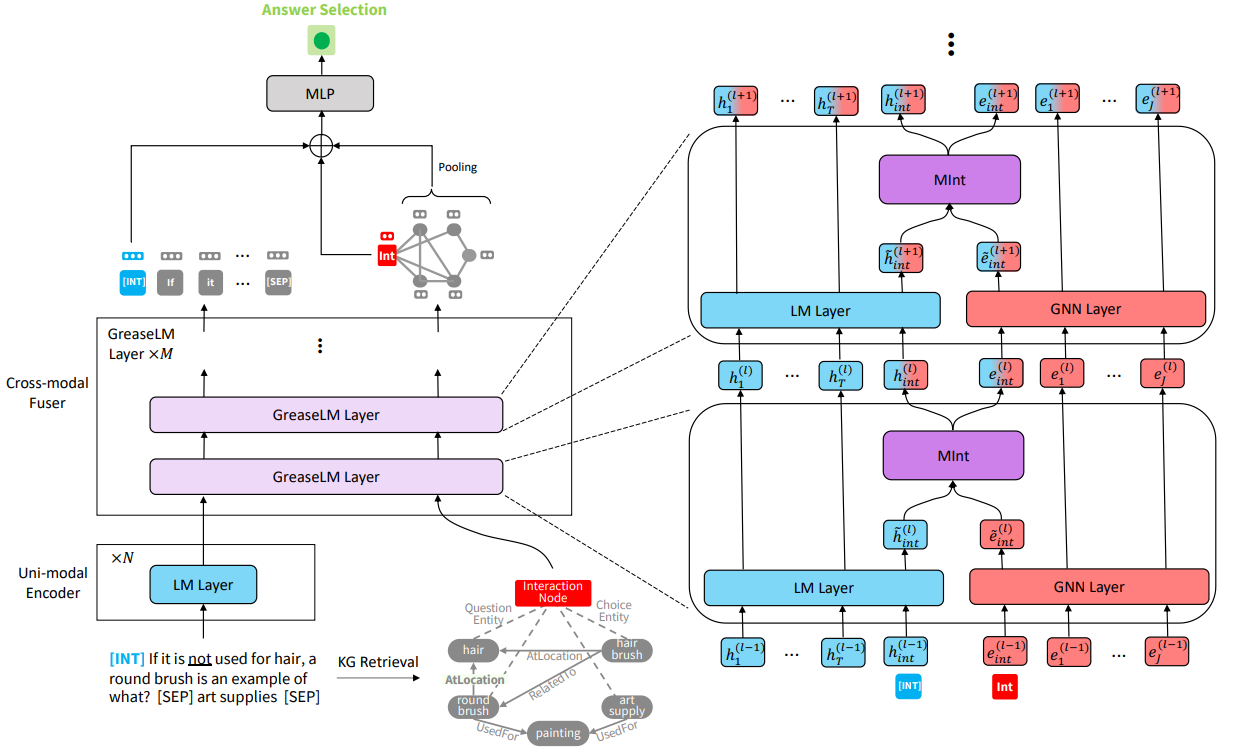
(source: copied from the paper)
GREASELM consists of three components stacked vertically:
- LM representation: an uni-modal encoder of N layers encodes the QA context and the prefix interaction token \(w_{int}\).
- Graph representation and Cross-modal Fuser of M layers:
- An entity linker is employed to extract KG entities from QA context from which a small KG \(\mathcal{G}\) is constructuted.
- The embeddings of entity nodes and proxy interactive node \(e_{int}\) are calculated by graph attention network.
- LM leverages the reasoning skills of GNN by fusing, at every layer, the representations of tokens and nodes through two proxies \(w_{int}\) and \(e_{int}\):
where (\(\hat{\textbf{h}}_{int}^{(l)},\hat{\textbf{e}}_{int}^{(l)}\)) and \((\textbf{h}_{int}^{(l)},\textbf{e}_{int}^{(l)})\) are embeddings of (\(w_{int}\), \(e_{int}\)) before and after fusion. \(Mint\) is a two-layer MLP.
- For multi-choice QA, the score of an answer is computed by another MLP taking in \((\textbf{h}_{int}^{(N+M)},\textbf{e}_{int}^{(M)}, g)\) where \(g\) is attention-weighted embedding of graph entities.
GREASELM demonstrates better performance than previous KG-enhanced LM for CommonsenseQA, OpenbookQA, MedQA-USMLE.
Ablation shows :
- GREASELM’s improvement questions that require complex reasoning: negation, hedging term’s presence.
- Attention visualization makes sense.
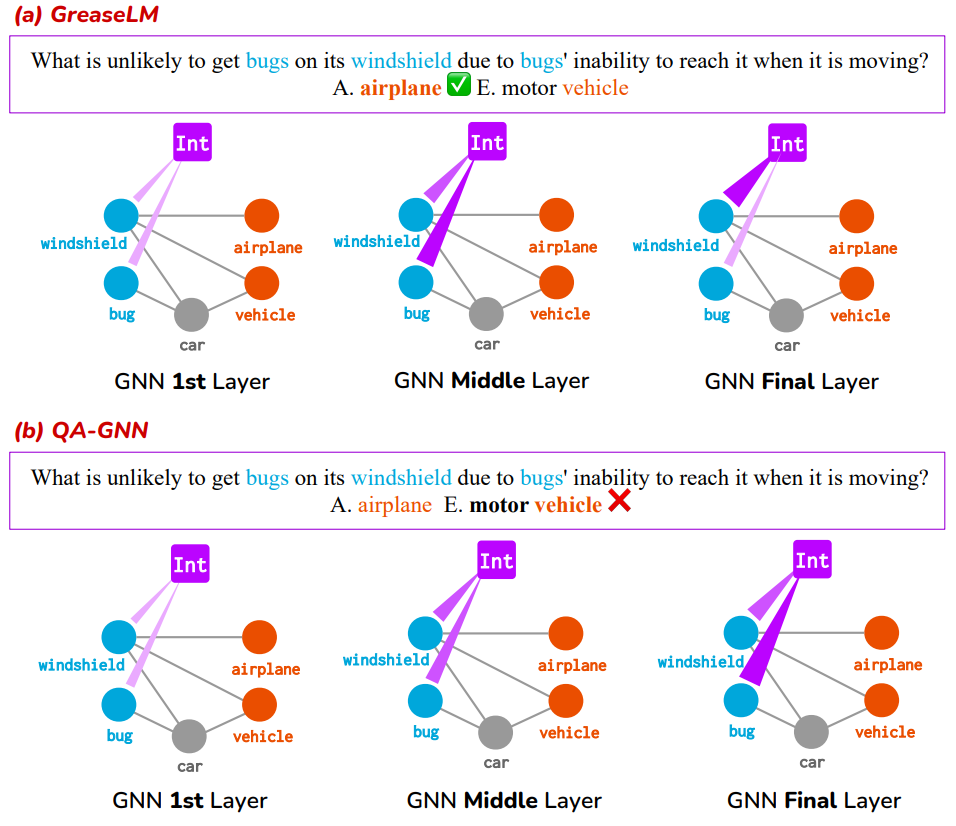
(source: copied from the paper)
-
Entity Cloze By Date: What LMs Know About Unseen Entities (Onoe et al., Finding NAACL 2022)
The paper introduces ECBD dataset, containing new entities that are did not exist when the LMs were pretrained, together with cloze sentences in which the entity mentions are found.
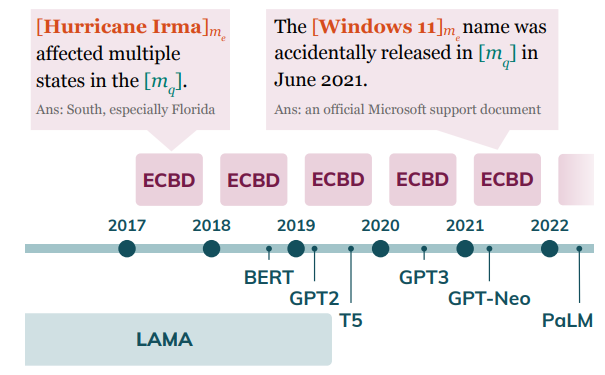
(source: copied from the paper)
The masked spans in cloze sentences are chosen that likely relates to the new entities. For each cloze sentence (ORIGINAL), three variants are generated:
- NO ENT: replaces the entity mention span by mention of another entity that is seen during pre-training.
- RANDOM DEFINITION: prepend the definition of a random entity to ORIGINAL.
- DEFINITION: prepend the definition of the gold entity to ORIGINAL.
By measuring the perplexity on 4 categories of cloze sentence, author suggest that injecting additional information (i.e. entity definition) can help the LM guess better (perplexity order: DEFINITION < ORIGINAL~RANDOM DEFINITION < NO ENT) the masked spans related to new entities.
-
Large Language Models Struggle to Learn Long-Tail Knowledge (Kandpal et al., arxiv 2022)
The paper experimentally shows that the performance of LM on entity-centric knowledge-intensive task (e.g. question-answering) depends strongly in the co-occurrence of {question entity, anwser entity} in the training documents. Specifically, questions related to entities of low frequency result significant low accuracy. They argue this is not due to the questions being “harder”, which causes the drop in the performance, as human performs very well for those questions.
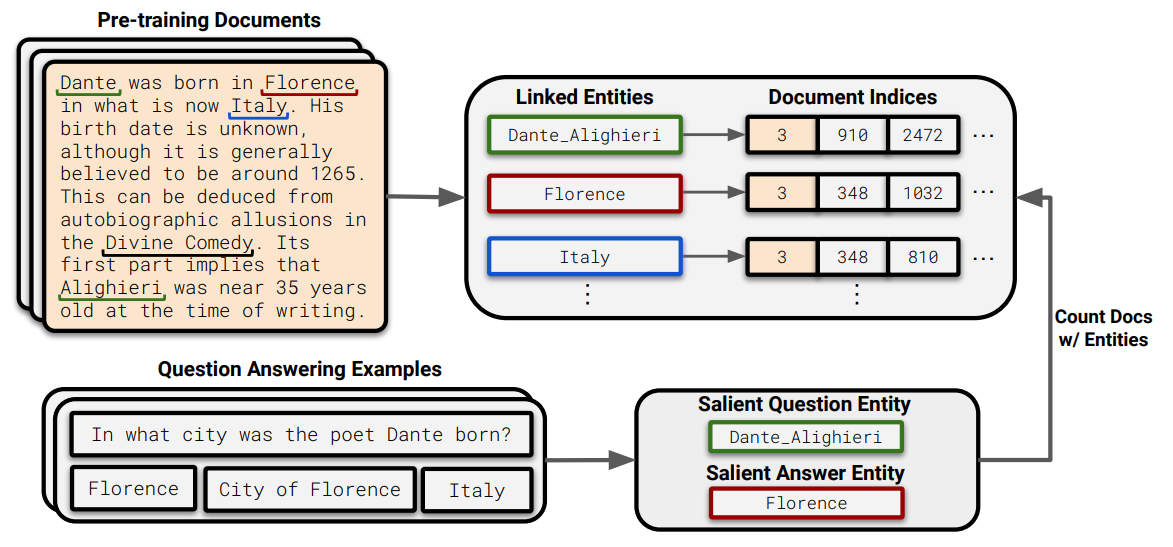
(source: copied from the paper)
-
Unified Structure Generation for Universal Information Extraction (Lu et al., ACL 2022)
Universal Information Extraction (UIE) is a unified text-to-structure framework for Information Extraction tasks. It models various IE tasks (NER, EL, RL, etc) within a single T5-based model, allowing different tasks to be jointly learned, to share and collaborate. To this end, UIE introduces two univeral templates for linearizing the heterogeneous input and the heterogeneous output and pre-training scheme to endow the model with common IE abilities (i.e. mapping text to structure, decoding structure).
In more details:
- SSI (Structural Schema Instructor) template to represent the heterogeneous input: e.g. \(\textsf{[spot] person [asso] work for [text] Steve became CEO of Apple in 1997}\) where special tokens \(\textsf{[spot]}\) and \(\textsf{[asso]}\) indicate what to extract in \(\textsf{[text]}\) (\(\textsf{[spot]}\): person entity, \(\textsf{[asso]}\): its attribute).
- SEL (Structured Extraction Language) template to represent the heterogeneous output such as \(\textsf{((entity: (attribute: )))}\): e.g. \(\textsf{((person: Steve (work for: Apple)))}\) for the above input.
- Pre-training paradigm: UIE is jointly trained with three objectives: (1) text-to-structure with Wikipedia-Wikidata aligned (text, KB triplets) pairs. (2) UIE decoder pretraining to autoregressively predict components (predicate, object) in KB triplets. (3) T5’s training objective: span corruption based MLM.
-
Rejection Machanism: adding NULL to the training data to help the model learn to reject misleading generation.
Example Encoder: <spot> person ... <spot> facility <asso> ... <text> Steve became CEO of Apple in 1997. Decoder: ((person: Steve (work for: Apple)) (facility: [NULL]) ...
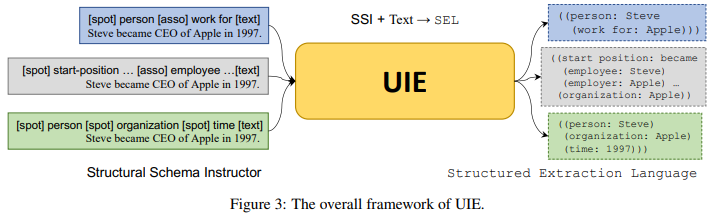
(source: copied from the paper)
-
GenIE: Generative Information Extraction (Josifoski et al., NAACL 2022)
Close Information Extraction (cIE) typically aims at extracting an exhaustive set of relational triplets \((subject, relation, object)\) from given text where \(subject/object\) entity and \(relation\) are constrained to come from a predefined knowledge base. Traditional cIE pipeline encompasses multiple independent sub-tasks (NER, NED, RE) which suffers from the error accumulation. GenIE is an end-to-end autoregressive cIE system that casts the triplet extraction as text-2text problem in which the decoder generates entities and relations token-by-token in an autoregressive fashion. They introduce special tokens <sub>, <rel>, <obj>, <end_of_triplet> to linearize the generated output. To assure that generated tokens refer to valid entity and relation, GenIE employs constrained beam search to guide the decoding following prefix tries built on the entity set and the relation set of the knowledge base. This makes the beam search effective for large million of entities.
Example Encoder: John Smith acts in the movie Wichia Decoder: <sub> Wichia (1995 film) <rel> cast member <obj> John Smith (actor) <end_of_triple> <sub> Wichia (1995 film) <rel> instance of <obj> film <end_of_triple>GenIE enforces the order of generated triplets in the way that triples for which the subject entity appears earlier in the text will be generated first.
GenIE can be extended to the generation of literal object \(\rightarrow\) similar to open Information Extraction where the object does not need to be aligned with a KB.
-
EIDER: Empowering Document-level Relation Extraction with Efficient Evidence Extraction and Inference-stage Fusion (Xie et al., ACL Findings 2022)
EIDER: Extracted Evidence Empowered Relation Extraction
(source: copied from the paper)
Typical document-level relation extraction models rely on the whole document to infer the relation of an entity pair in the document. On the one hand, a minimal set of sentences (i.e. evidences) in the documents is enough for human to annotate the relation, taking the whole document as input may add noise and ambiguity to the model. On the other hand, there is no way to extract such minimal set perfectly, leading to missing important information. EIDER alleviates both aspect by introducing:
- Joint training of relation extraction end evidence sentence extraction: a base encoder is employed to learn the representation of the relation from the counterparts of the head entity, tail entity and the whole document \(p(r \mid e_h, e_t, c_{h,t})\), as well as to learn the representation of each evidence sentence \(s_n\) given the head and tail entity \(p (s_n \mid e_h, e_t)\). For the training, evidence sentences for each entity pair in a document can be either manually provided, or extracted using simple heuristics (e.g. a sentence containing both head and tail entities is considered as an evidence for this entity pair).
- Fusion of evidence in Inference: the score of each candidate relation is given by two inferences: one with the prediction from the whole documents, one with the prediction from the set of extracted evidence sentences (a subset of original document). \s
-
KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction (Chen et al., The WebConf 2022)
KnowPrompt: prompting with knowledge constraint
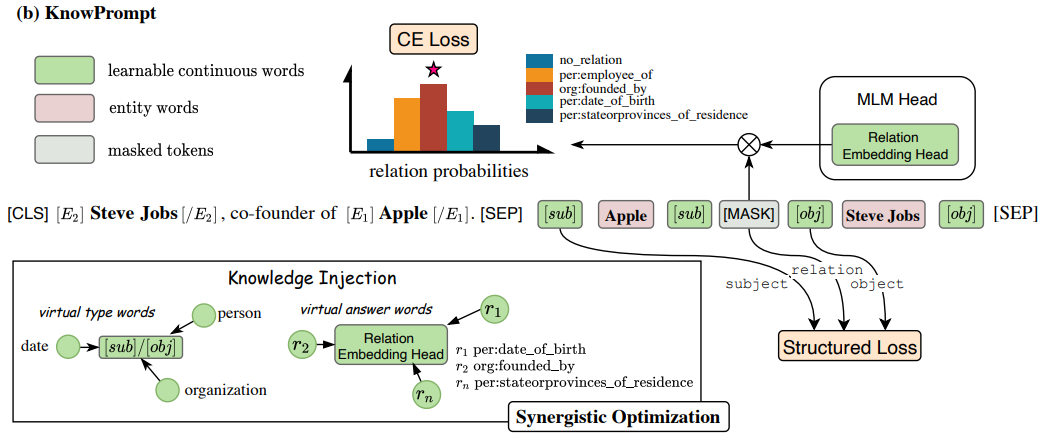
(source: copied from the paper)
KnowPrompt relieves the cumbersome prompt engineering by representing the prompt template and prompt verbalizer by learnable virtual words. Specifically, given a prompt: \(\textsf{[CLS] It solds [E1] ALICO [/E1] to [E2] MetLife Inc [/E2] for \$162 billion. [SEP] [sub] ALICO [sub] [MASK] [obj] Metlife Inc [obj]. [SEP] }\) where the first sentence is the context in which foreknow sentinel tokens \(\textsf{[E1], [E2]}\) indicates entities whose relation will be discovered in the second sentence. Three tokens \(\textsf{[sub], [MASK], [obj]}\) are considered as virtual words representing the subject entity type, the relation, and the object entity type respectively. The possible relation \(r\) between \(\textsf{E1}\) and \(\textsf{E2}\) is computed from the probability distribution at \(\textsf{[MASK]}\) token.
To guide \(\textsf{[sub], [obj]}\) to represent meaningfully the associated entity \(\textsf{E1, E2}\) as well as to encode the structural constraint between them and the relation, KnowPrompt:
- Instead of random initialization, the embeddings of \(\textsf{[sub], [MASK], [obj]}\) are initialized with prior distribution (calculated by frequency statistics) of entity type’s word-embedding and relation’s word embedding.
- Incorporate structural knowledge constraint: apart from LM loss, inspired by knowledge graph embedding, KnowPrompt interprets \(\textsf{[MASK]}\) as a translation from \(\textsf{[sub]}\) to \(\textsf{[obj]}\) (similar to TransE), leading to the minimization of the Euclidean distance in the embedding space: \(d([sub], [obj]) = \mid \mid [sub] + [MASK] - [obj] \mid \mid_2\)
-
Rewire-then-Probe: A Contrastive Recipe for Probing Biomedical Knowledge of Pre-trained Language Models (Meng et al., ACL 2022)
Contrastive-Probe for Knowledge probing from LM.
Knowledge probing approaches based on mask prediction or text generation have two typical drawbacks:
-
Multi-token span prediction: the mask prediction approaches use the MLM head to fill in a single mask token in a cloze-style query \(\rightarrow\) if an answer entity names that contain multi-token span, the query needs to be padded with the same amount of [MASK] token.
-
The answer may not be a valid identifier of an entity: the mask prediction or text generation approaches rely on the vocabulary to generate the answer in an unconstrained way \(\rightarrow\) the generated texts may not exist in the answer space. Furthermore, different LMs can have different vocabularies, leading to the vocabulary bias.
The paper introduces Contrastive-Probe to address two above issues by avoiding using the LM head for mask prediction or text generation. Similarly to sentence embedding approaches, Contrastive-Probe employs the LM to encode the prompt query \(q\)(e.g. “Elvitegravir may prevent [Mask]”, [Mask] can represent multiple tokens) into the embedding \(e_q\) and encode each answer (e.g. “Epistaxis”) in the complete answer space into another embeddings \(e^i_s, i=1..N\) where \(N\) is the size of answer space. The K-nearest neighbors \(e^k_s, k=1..K\) of \(e_q\) in the embedding space are considered as the answer of \(q\). Self-supervised contrastive learning is used to rewire the pretrained LM to this answer-retrieval task. Specifically, with infoNCE objective loss, the PLM is fine-tuned on {query, answer} pairs in order for the {query, correct answer} pairs (positive samples) stay close to each other and {query, other answer in the same batch} pairs (negative samples) are pulled far apart.
Testing on bio domain, Contrastive-Probe achieved several following results:
- Contrastive-Probe outperforms other probing baselines (mask prediction, text generation) ) regardless of the underlying PLM on MedLAMA benchmark for Bio domain.
- It is effective at predict long answer (aka. multi-token span)
- In phase with previous observation, no configuration fits all relations. Different relation require different underlying LM, different depth of tuning layer for the best performance.
- It is pretty stable in performance where training with different dataset results small deviation and similar trend.
-
-
Do Pre-trained Models Benefit Knowledge Graph Completion? A Reliable Evaluation and a Reasonable Approach (Lv et al., ACL-Findings 2022)
The paper demonstrates that PLM-based KGC models are still left quite behind the SOTA KGC models (e.g. KGE models) because the evaluation benchmark is conducted under the closed-world assumption (CWA) where any knowledge that does not exist in a given KG is said to be incorrect. Indeed, PLM is known to implicitly contain more open knowledge unseen in a KG. By manually verify the veracity of Top-1 prediction of KGC models, they show that PLM-based models outperforms SOTA KGE-based models for the link prediction and the triple classification tasks.
Likewise many other models, this work also make use of prompting method to elicit the knowledge from PLM. A hard prompting template is manually designed for a relation to represent the semantics of the associated triples. For example, relation <X, member of sport teams, Y> has the template X plays for Y. To further improve the expressivity of triple prompts, two other kinds of prompts are added into the triple prompt:
- Soft prompts (i.e. learnable sentinel tokens [SP]): play as separators to signal the position of template components and entity labels in the triple prompt. For example, the prompt X plays for Y after adding soft prompts becomes [SP1] X [SP2] [SP3] plays for [SP4] [SP5] Y [SP6]. Each relation has its own set of soft prompts \([SP]_i, i=1..6\) and they are all learnable via triple classification objective.
- Support prompts: entity definition and entity attribute are useful information that can help the KGC. Therefore, they are concatenated to the triple prompt through two templates: “[Entity]: [Entity_Definition]” and “The [Attribute] of [Entity] is [Value]”. As an entity has many attributes, only few attributes are randomly selected. The results reveal that the entity definition provides more gain than entity attributes.
Additionally, their analysis conveys two messages: (i) by counting number of sentences in the training that contain both the head and the tail of a triple, it indicates that PLM-based KGC still outperforms KGE-based KGC on the triples with zero co-occurrence of {head, tail} in the training set \(\rightarrow\) they argue PLMs, apart from seeing many facts in the massive text, have the ability to reason the knowledge. (i) PLM-based KGC models are less sensitive to the size of training dataset where reducing the training data size decreases slightly the prediction accuracy.
-
SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models (Wang et al. ACL 2022)
SimKGC: Promptless method for KGC based on sentence embedding
To predict an entity \(e_i \in KG \; \mathcal{E}\) for a triple \(<h, r, ?>\), SimKGC employs a PLM-based bi-encoder architecture where two encoders do not share parameters. One encoder computes the relation-aware embedding \(e_{hr}\) for the head entity \(h\) from the concatenation of the descriptions of the head entity and the relation: “[header_description] [SEP] [relation_description]”. Another encoder is leveraged to compute the embedding of the description of the candidate tail entity \(e_t\). Candidate tail entities \(e^i_t\) are ranked according to the cosine similarity between its embedding and the relation-aware embedding of the head entity \(e_{hr}\). The bi-encoder is trained to learn useful representation for head entity and tail entity in the triple using contrastive learning.
The paper argues that the reason why previous contrastive learning-based models are lag behind SOTA KGE-based models highly involves the ineffectiveness of training setting for contrastive learning where they use small negative sample size (\(\approx\) 1..5 due to computational complexity) and the margin loss. Indeed, by augmenting the number of negative sample per positive sample (e.g. 256) and changing the margin loss to InfoNCE loss, they obtain much better performance and outperform KGE-based models.
For further improvement, in addition to in-batch negative, SimKGC also combine two other strategies for generating negative samples:
- Pre-batch Negatives: sample batches at training step \(t-1\), \(t-2\)… can be considered as negative samples for current training batch at step \(t\).
- Self-Negatives: triple \(<h, r, h>\) (tail entity is predicted as head entity) is seen as a hard negative sample for the triple \(<h, r, ?>\) \(\rightarrow\) this makes the model rely less on the spurious text matching/overlapping to make the prediction.
Lastly, the work also stresses that predicting one-to-many, many-to-one, many-to-many relations is more difficult.
-
Task-specific Pre-training and Prompt Decomposition for Knowledge Graph Population with Language Models (Li et al., LM-KBC@ISWC 2022 Challenge)
This work continues to pre-train BERT with task-specific data to make it familiar with the task. How ? triples <sub, rel, obj> are verbalized into a sentence using a prompt template of rel. As the task is object prediction, the object or surround words in the sentence are masked and the LM is asked to predict them. Large dataset is necessary for pre-training, hence, they leverage Wikidata for data augmentation where they generate KG triples that have same relations as provided training relations). However, they discover later that the accuracy does not clearly relate to data size but the property of relation (see below).
- Prompt generation: they curate a set of prompts for a relation both in manual and automatic way. In manual way, they explicitly append the type of the subject into the prompt, such as “The musician [SUBJ] plays [OBJ]” for relation “PersonInstrument”. In automatic way, they employ two methods from How Can We Know What Language Models Know?. However, in contrast to How Can We Know What Language Models Know?, this paper shows that an ensemble of automatically-generated prompts is not better than a single manual-curated one.
- Prompt decomposition: a relation can have diverse domain and diverse range. For example, considering the relation “StateSharesBorderState”, its domain can include “Andalusia”-is a autonomous community or “Hebei” - a province. To better distinguish the type of the subject and probe more relevant knowledge from LM, two prompts are performed:
- ask for subject type: e.g. e “[SUBJ], as a place, is a [TYPE]”.
- inject the subject type into the prompt of the relation: e.g. “[SUBJ] [TYPE] shares border with [MASK] [TYPE]”.
2021
-
GENRE: Autoregressive Entity Retrieval (De Cao et al., ICLR 2021).
Very interesting entity retriever that casts the entity linking problem as a text-to-text problem and employs a seq2seq model (i.e. BART) to address it.
Example:
Encoder: In 1503, Leonardo began painting the Mona Lisa Decoder: In 1503, [Leonardo](Leonardo da Vinci) began painting the [Mona Lisa](Mona Lisa) where [X](Y) : X is the mention, and Y is the entity label (aka. entity identifier) that represents X.Importantly, they perform the inference with constrained beam search to force the decoder to generate the valid entity identifier. Specifically, at a decoding step \(t\), the generation of the next token \(x_t\) is conditioned on previous ones \(x_1,..., x_{t-1}\) such that \(x_1,..., x_{t-1}, x_{t}\) is a valid n-gram of an entity identifier.
-
Structured Prediction as Translation Between Augmented Natural Languages (Paolini et al., ICLR 2021)
Many knowledge extraction tasks such as NER, EL, Relation extraction, etc can be seen as structured prediction tasks where the output space consists of structured objects such as entities, relations.
Translation between Augmented Natural Languages (TANL) frames multiple prediction tasks as text-2-text problems and employs an unified architecture (e.g. BART, T5, etc) to solve all those tasks without task-specific designs. To this end, they propose informative templates (called augmented language) to encode structured input and decode output text into structured objects.
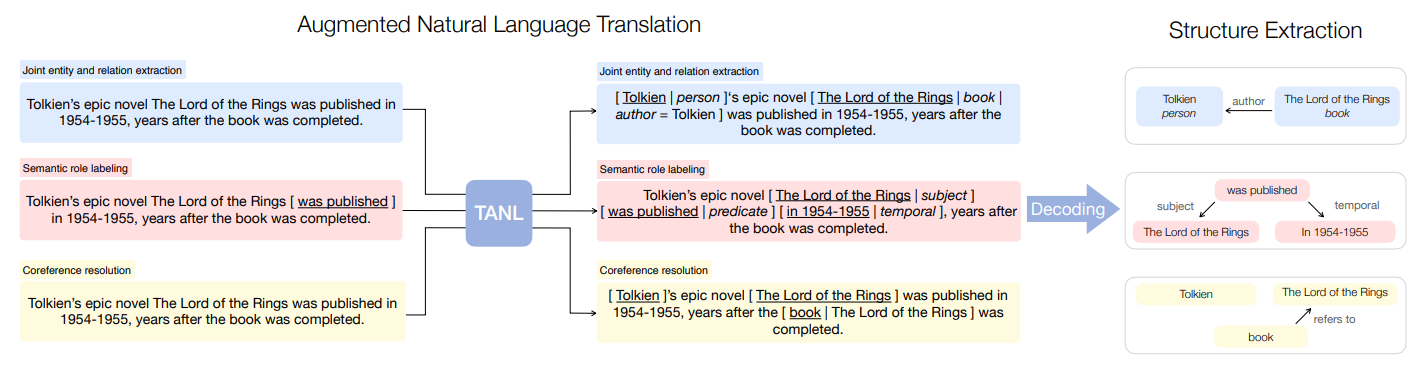
(source: copied from the paper)
One remarkable feature of TANL’s encode scheme is its ability to represent nested entities and multiple relations, as illustrated in example below:
Example Encoder: Six days after starting acyclovir she exhibited signs of lithium toxicity. Decoder: Six days after starting [ acyclovir | drug ] she exhibited signs of [ [ lithium | drug ] toxicity | disease | effect = acyclovir | effect = lithium ].To ensure the consistency and the relevance of decoder’s output text, TANL follows several post-processing steps including:
- Dynamic Programming to align generate output text with input text. This helps to tackle imperfect generation by the decoder (e.g. generated word is a mispelling version of input word).
- Verify if predicted tail entity of predicted relation extactly matches an entity in the input.
TANL is shown to be beneficial in multi-task learning in which a single model is trained on multiple different datasets for different structured prediction tasks and in low-data regime (few shot finetuning).
2020
-
How Can We Know What Language Models Know? (Jiang et al., TACL 2020)
Knowledge in LM can be probed by asking the LM fill in the blanks of prompts such as “CR7 plays for ___”. This prompt-based method can only measure the lower bound of amount of knowledge contained in LM as there is no single prompt that works best for all instances of a relation (depending on what LM sees during its pre-training). To predict a missing object in a KB triple \(tpl\): <sub, rel, ?>, \(tpl\) is converted into a cloze-style prompt \(t_r\) that semantically expresses the relation rel and let the LM predict the object by filling the blank in \(t_r\). No prompt fits all, they propose two ways to generate a set of prompts for each relation \(r\):
- Mining-based generation: (i) collecting sentences that contain both subject and object of a given relation \(r\), words between subject and object can be viewed as a representation of \(r\); (ii) if there is no meaningful middle words, sentence is analyzed syntactically, a prompt for \(r\) can be generated from the dependency tree.
- Paraphrasing-based generation: starting from an initial prompt \(p\) for \(r\), \(p\) is paraphrased into other \(p'\) semantically similar. For example, if \(r\) == “hasName” has a prompt \(p\) == “x is named as y” then \(p'\) could be “y is a name of x”. Back-translation is a prevailing method for paraphrasing.
Thoughts:- Blank in cloze-style prompt: how does LM know if ___ is single-token and multi-tokens (this work defaults single token).
- Domain and Range of a relation are ignored: a relation can appear under many different situations. A prompt is suitable for a situation but could turn out to be strange for other situations.
3. Prompting Methods
2023
-
Large Language Models as Optimizers (Yang, arxiv 2023)
(a)
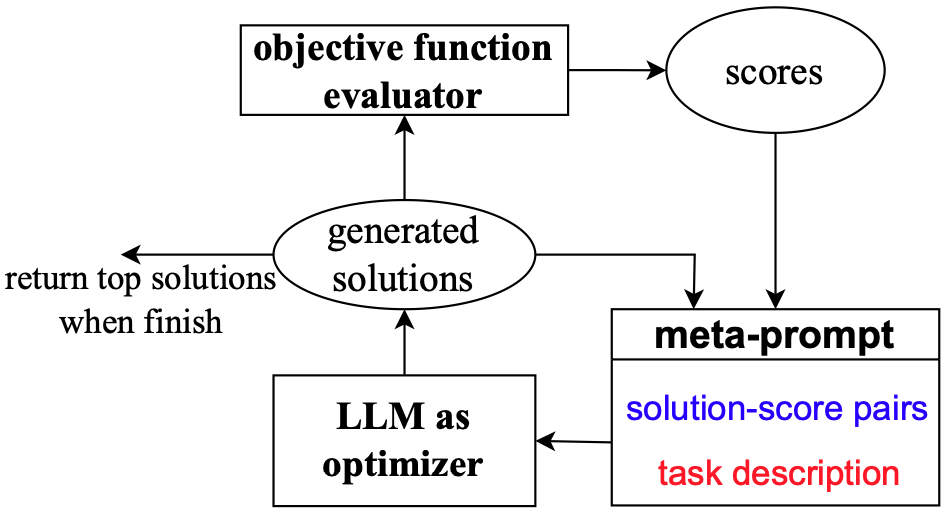 (b)
(b) 
(source: copied from the paper)
Prompting engineering is a non-trivial task as many works show that semantically similar instructions may cause significantly different accuracies. OPRO is a gradient-free LLM-based optimizer for searching instructions that maximizes the accuracy of given task within a few training samples. The optimization process consists of two (distinct or identical) models: scorer-LLM and optimizer-LLM and performs iteratively 2 steps:
- Given N instructions generated at step t, the scorer-LLM run the inference over the training samples. Top-k instruction yeilding the best accuracies are retrained.
- At step t+1, top-k instructions, along with its scores are then appended into the context containing a few training samples as demonstrations and a meta-instruction such as “write the new instruction that is different from the old ones and has a score as high as possible. The optimizer-LLM is then prompted to generate N instruction via sampling.
At each step, optimizer-LLM generates N instructions instead of a single instruction to improve the optimization stability as generated instruction can be very sensile to the demonstrations in the context.
In addition, sorting N instructions in ascending order and appending top-k ones into the context perfoms better and converges faster.
-
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources (Wang et al., arxiv 2023) + The Flan Collection: Designing Data and Methods for Effective Instruction Tuning (Longpre et al., ICML 2023)
Flan Collection and TuLu are two large, holistic collection of different instruction-tuning datasets in few-shot, zero-shot, chain-of-though styles. They have demonstrated that training with such mixed prompt and multi tasks settings help models (i.e. T5, LLaMa) generalize better unseen domains and uncover new skills.

(source: copied from the paper)
Several findings:
- There is no best instruction collection for all tasks.
- Base model used to instruct-tune is important (i.e. LLaMa > OPT, Pthia across sizes).
- Smaller models may benefit more from instruction tuning.
- Models fined-tuned on traditional NLP instruction datasets (e.g. CoT, FLAN, SuperNI) perform poorly on open-ended generation.
- In addition to benchmark-based evaluation, model-based evaluation (e.g. using GPT-4 to score the predictions) is necessary for the evalation of open-ended generation task. However, model-based evaluation should not be the sole metric as bias may occur when GPT-4 based evaluation prefers long and diverse generations.
-
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models (Zhou et al., ICLR 2023)
Least-to-Most few-shot prompting helps improve the solving capacity of reasoning problems that are harder than provided demonstrations (easy-to-hard generalization) by breaking down the problem into a series of subproblems and sequentially solving subproblems. The difference between Least-to-Most and CoT may be that CoT does not explicitly use command decomposition (e.g. “how long does each trip take ?”) and demonstrations in Least-to-Most are often subproblems of the target problem (i.e. recursive programming).
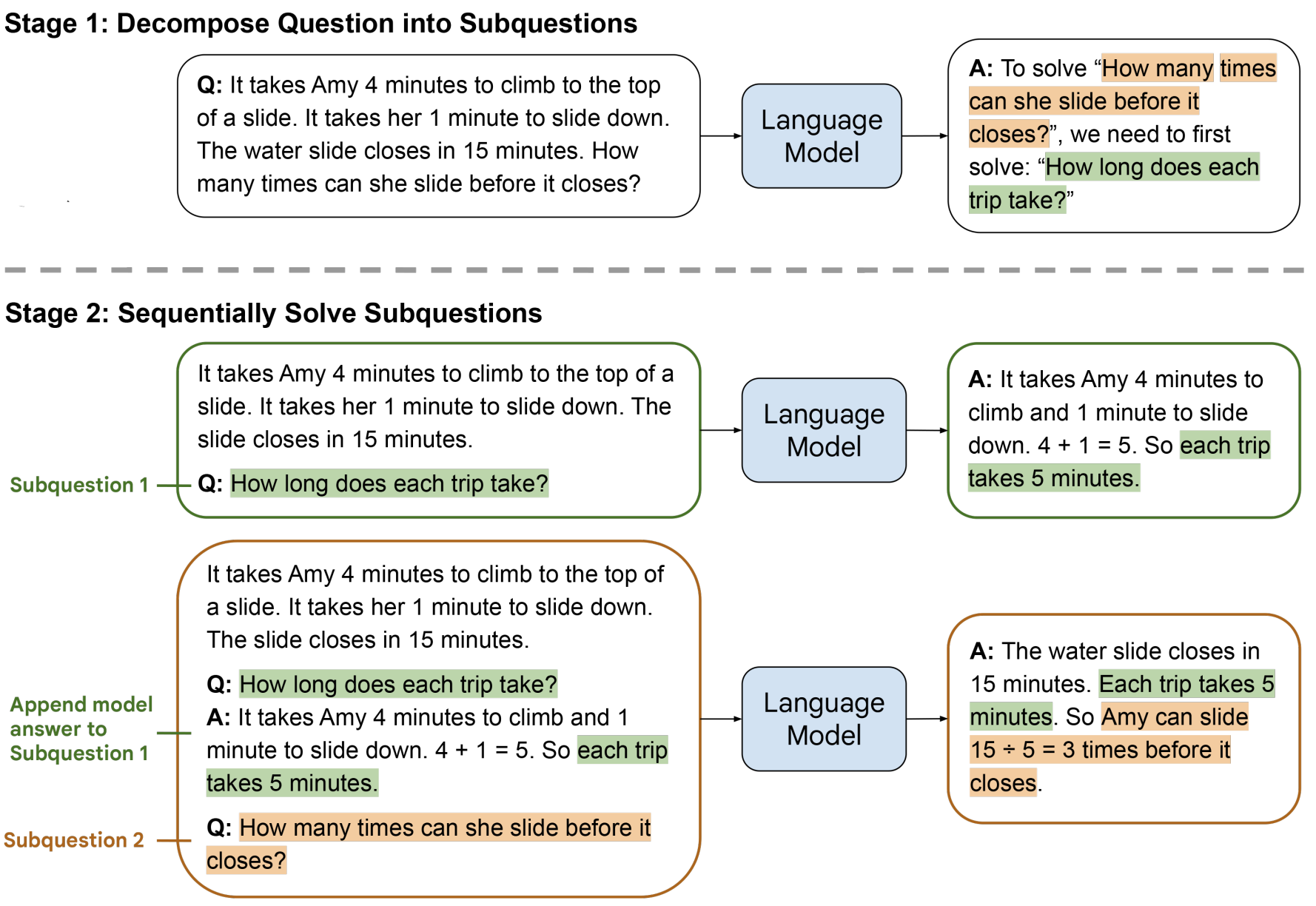
(source: copied from the paper)
Several findings:
- Generalize better to the length longer than those in the demonstrations.
- Better math reasoning for complex problems (i.g. those require many solving steps)
- Decomposition prompts don’t generalize well across different domains. A specific domain needs a specific decomposition template.
-
Multitask Prompt Tuning enables Parameter-Efficient Transfer Learning (Wang et al., ICLR 2023)
In the context of efficient multi-task learning, learning a single prompts for all training tasks, then adaptive fine-tuning it for downstream task may not be optimal as it fails to leverage the commonalities while minizing the interference among training tasks. To enable efficient knowledge sharing across tasks, this paper introduces multitask prompt tuning (MPT).
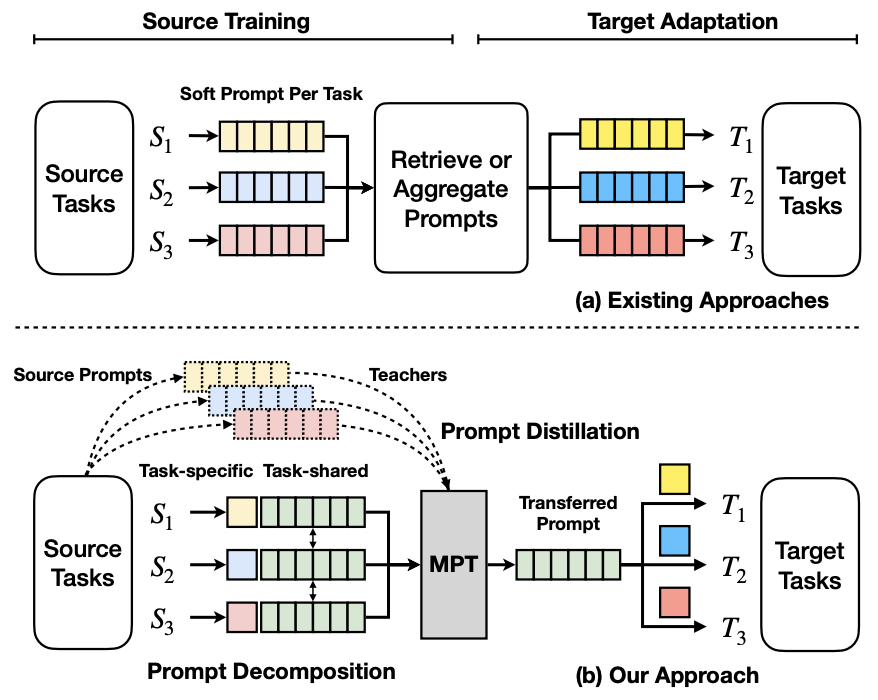
(source: copied from the paper)
Specifically, the prompt \(P_k\) for \(k\)-th task is a composition of two components:
\[P_k = P^* \circ (u_k \otimes v_k^T )\]where \(P^*\) is shared among tasks and \(W_k = (u_k \otimes v_k^T )\) is low-rank task-specific prompt for \(k\)-th task.
Learning the above prompt decomposition from multiple training tasks may cause the shared prompt \(P^*\) overfit to the large tasks. To mitigate this issue, (MPT) employs three loss functions:
- For \(k\)-th source task, teacher prompt \(P_k^{teacher}\) is obtained via conventional prompt tuning (independent of other tasks). Then, \(P_k\) is optimzed to match with \(P_k^{teacher}\):
- Hidden states of teacher model (\(P_k^{teacher}\)) and student model (\(P_k\)) shoule match.
- Total loss:
-
Grammar Prompting for Domain-Specific Language Generation with Large Language Models (Wang et al., arxiv 2023)
It is challenging to perform in-context learning with LLMs for the prediction of highly structured languages (e.g. semantic parsing or domain-specific language (DSL)). Effectively, DSLs are unlikely frequently seen during pretraining of LLM and it is not adequate for the model to uncover the complex task specification/requirement within a few demonstrations.
This paper introduces grammar prompting, which augments in-context demonstrations with domain-specific constraint, expressed under Backus–Naur Form (BNF) context-free grammar. BNF is a metasyntax notation provding a symbolic way to define the syntax of a language (e.g. see G[y] as a minimal BNF grammar specialized for a calendar DSL of which y is an example).
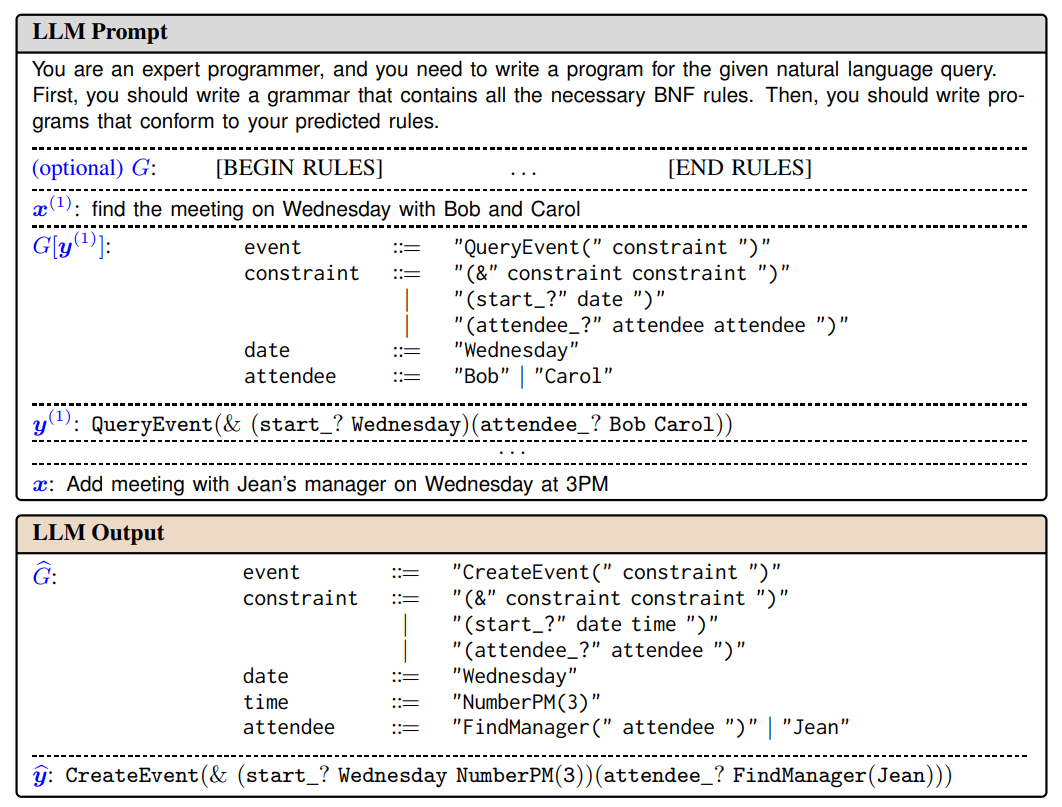
(source: copied from the paper)
While an instance of a DSL language like y is rare in the pre-training, author argues that the metalanguage used to describe the DSL language like BNF G[y] is, to some extent, more often. Consequently, like Chain-of-Thought prompting, grammar prompting suggests performing several intermediate reasoning step (i.e. generate automatically G[y]) before arriving at the final prediction (i.e. decoding G[y] to get y).
During in-context learning, author discovers that providing the full grammar G to the demonstrations is not effective. They proposes instead a minimal grammar G’ \(\subset\) G which is enough to constraint the generation of the corresponding demonstrations.
The generation of G’ is constrained by metalanguage (the grammar of G’) and the generation of y is constrained by G’ (the grammar of y). Instead of verifying the validity of generated token at each decoding step, grammar prompting first predicts the whole output (without constraint). If the output is legal, it is returned. Otherwise, an incremental parser is used to extract the longest valid prefix from the output. The prediction is continued from this prefix.
Tested on semantic parsing task, grammar prompting outperforms standard prompting without constrained decoding or with decoding constrained on full grammar G. However, it still lags behind the prompting with decoding constrained on the gold G’ (not predicted G’ as in grammar prompting), indicating room for future improvements.
-
Symbol Tuning Improves In-Context Learning In Language Models (Wei et al., arxiv 2023)
The paper relies on the intuitions related to in-context learning (ICL) for classification-type tasks:
- The model is not forced to learn to reason from provided demonstrations as it can sometimes understand the task by just reading the instruction and natural language labels.
- When the model can not rely on the instructions (e.g. empty instruction) or relevant natural language labels (e.g. random label) to figure out the task, it has to reason from and learn the input-label mapping to understand the task, as described in the image below:
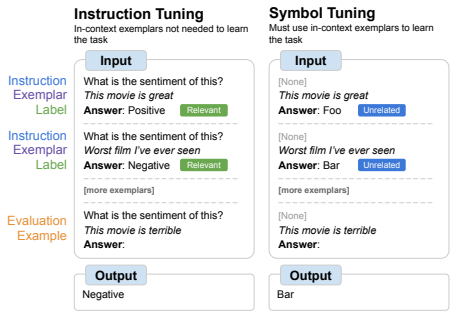
(source: copied from the paper).
Author proposes Symbol Tuning, a simple fine-tuning that forces the model to learn the input-label mapping in the demonstrations, by removing the instruction and replacing the natural language labels by random (semantically-unrelated) ones. By this way, the model could be endowed with better in-context learning.
Findings are:
- Symbol-tuning shows strong potential to improve the model performance when tasks are not clear, relevant labels are unavailable and require learning from demonstrations.
- Symbol-tuning may degrade the performance of smaller LM (8B) on tasks where task instructions and relevant labels are available. One solution to this is to mix instruction-tuning and symbol-tuning data during the tuning. The proportion of two components is not important.
- Symbol-tuning is efficient as it requires fewer steps to achieve stable performance.
- Symbol-tuned models can override what it has learnt before via flipped labels (e.g. 0 –> True, 1 –> False instead of 1 –> True, 0 –> False as usual). Indeed, symbol tuning forces the model to read the {input, flipped label} pairs in the demonstration, which should make it rely less on prior knowledge that may counter the flipped labels.
-
Selective Annotation Makes Language Models Better Few-Shot Learners (Su et al., ICLR 2023)
-
Learning to Reason and Memorize with Self-Notes (Lanchantin et al., arxiv 2023)

(source: copied from the paper).
Unlike Chain-of-Thought or Scratchpad prompting which generates a reasoning path to arrive at answer for a question after reading the entire context/demonstrations, Self-Notes allows the model to create reasoning tokens (aka. take notes) at any point while reading the context. This has two advantages:
- Faciliate the multi-step reasoning where partial reasonsing tokens can be deviated from the context on the fly.
- Act as working memory for tracking the state of model computation: while traversing the context, the model can explicitly write down the current state as new tokens. If the later reasonings need this state, the model can recall it without thinking again from scratch.
Self-Notes employs several special tokens {[start], [end]} to signal when to take a note and when to finish a note. Once the note ends, it is appended to the context and the model continues to process the rest of the context.
Self-Notes is fine-tuned with supervised dataset (training sample includes context, question, gold self-notes and answer) or unsupervised dataset (there is no gold self notes, from the context, the model learns to generate its own question and insert its answers as self-notes).
Trick: Self-Notes manually amplifies the probability of [start] token to favor the production of more notes.
-
Self-Consistency improves Chain Of Thought Reasoning in Language Models (Wang et al., ICLR 2023)
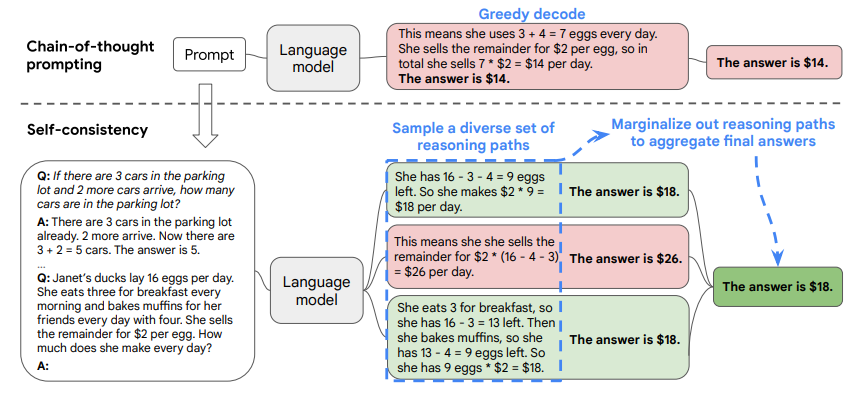
(source: copied from the paper).
While Chain of Thought (CoT) prompting generates only one reasoning path to arrive at an anwser for a question via greedy decoding, Self-consistency instead proposes to produce a diverse set of reasoning paths via sampling decoding methods (e.g. top-k, top-p or beamsearch), each reasoning path leads to an answer, the best answer is chosen using majority voting for example.
The rationale behind Self-consistency is that there could have different ways of thinking to solve a question. As the LM is not perfect reasoner, it may produce an incorret reasoning path or make mistakes in one of the reasoning steps (even though the reasoning path is relevant). Generating multiple diverse reasoning path can increase the likelihood of having a correct reasoning process, ratherthan relying solely on a single path.
Some benifits of Self-consistency:
-
While Single CoT could sometimes hurt the performance, Self-consistency helps to alleviate this issue.
-
Sampling decode outperforms beam search decoding in Self-consistency.
-
Self-Consistency can work with prompts that contain minor mistakes.
-
2022
-
Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations (Jung et al., EMNLP 2022):
LLM can generate inconsistent and unreliable explanation when a question and its negated version get the same answer (e.g. “One is a number that comes before zero ? … True” vs. “One is a number that comes after zero ? … True”). They introduce a novel prompting technique, Maieutic Prompting to improve the consistency in LLM’s generation. Inspired by Socratic style of conversation, the inference process exploits the depth of reasoning by asking recursively if a newly generated explanation is logically consistent with its parent (previous) explanation, as illustrated in the figure below:
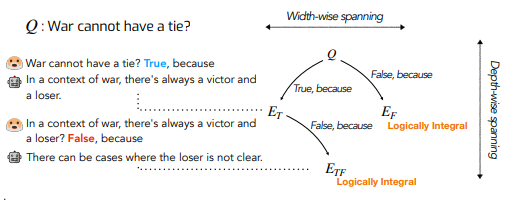 (source: copied from the paper).
(source: copied from the paper). -
MetaICL: Learning to Learn In Context (Min et al., NAACL 2022)
MetaICL is a meta-training framework where the model is fine-tuned with in-context demonstrations on a large set of training tasks. MetaICL improves in-context learning for new unseen task at inference time.

(source: copied from the paper).
MetaICL is meta-trained on a collection of > 30 tasks including text classification, QA, NLI, etc. The input context for each task has 4-32 demonstrations. MetaICL demonstrates significant gains for low-resource tasks or tasks whose data distribution is different from training data (unseen domain). It matches or sometimes outperforms models fine-tuned on target data. Furthermore, fine-tuning a meta-trained model on target data achieves the best performance.
Ablation study suggests MetaICL tends to saturate when number of demonstrations reaches 16 and more diverse meta-training tasks results in better performance.
-
Self-Instruct: Aligning LM with Self Generated Instructions (Wang et al., arxiv 2022)
In line with FLAN, TO, Self-Instruct continues to showcase the impressive ability of “instruction-tuned” LM to generalize to new tasks via zero-shot learning. FLAN, TO use instruction data manually created by human which is limited in quantity, diversity and creativity. This may impact the generality of the tuned model. Alternatively, Self-Instruct relies on the model itself (i.e. GPT3) to create automatically new instruction/input/output samples from a seed set of initial instruction/input/output samples through in-context learning. The new instruction data is then used to fine-tune the original model. Some post-preprocessing steps are also applied to filter low-quality data: (i) only retain new instructions that are low-overlap with existing instructions, (ii) discard new instructions that contain some specific keywords (e.g. images, graphs), (iii) discard instances that have different outputs for the same input.
The instruction/instance samples generated by Self-Instruct shows good diversity. Most of the instructions are meaningful while instances may contain noise (to a reasonable extent).
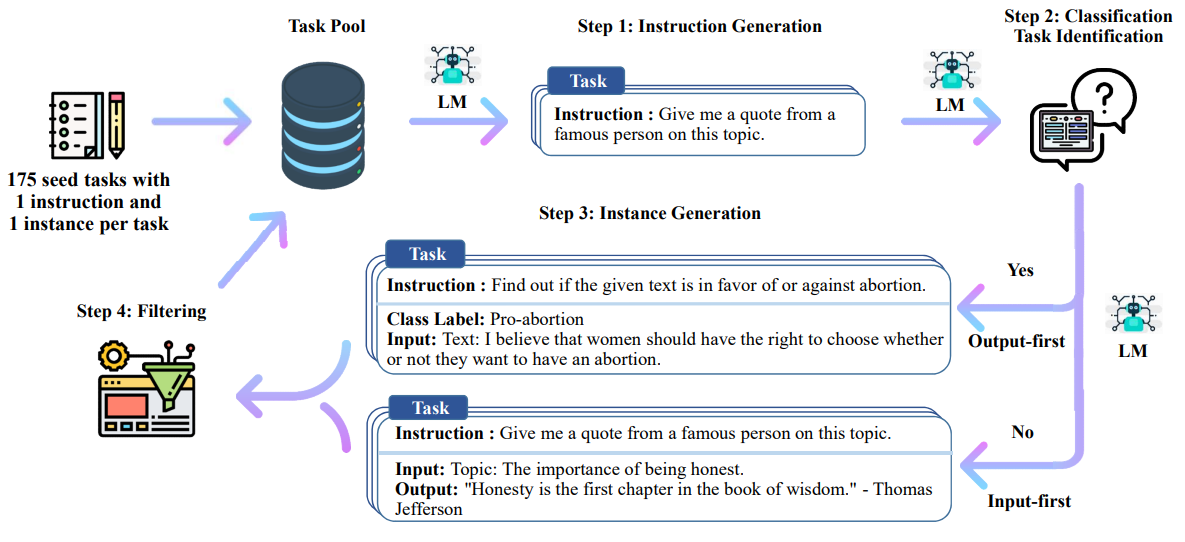
(source: copied from the paper)
P/s: Self-Instruct was used to generate 52K instruction-following samples (Alpaca) to fine-tune LLaMA 7B model, resulting ChatGPT-like Alpaca 7B
-
Finetuned Language Models are Zero-Shot Learners (Wei et al., ICLR 2022)
The paper shows that finetuning language models on a collection of datasets via instructions (aka. Instruction tuning, e.g. “Translate this sentence to French:…”) can considerably improve zero-shot performance on unseen tasks. The rationale behind instruction tuning is that the format of pre-training data of a LM is not similar to the format of prompts, making zero-shot inference hard. To bridge this gap, they introduce FLAN, a LaMDA-PT (137B parameters) fine-tuned on a mixture of NLP datasets expressed under natural language instructions. FLAN zero-shot(ly) outperforms others LLMs of similar number of parameters (LaMDA-PT 137B , GPT-3 173B) on wide range of NLP tasks.
Importantly, ablation studies shows that fine-tuning with instruction is a key factor for zero-shot performance on unseen tasks. For example, while fine-tuning LMs with translation task, instead of using input-output pair (“how are you ?”, “comment vas tu ?”), it’s better using (“translate this sentence to french: how are you ?”, “comment vas tu ?”).
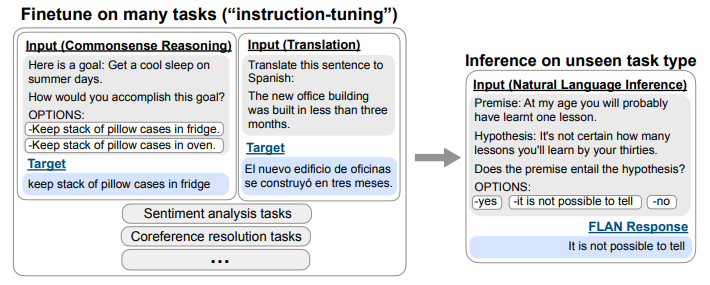
(source: copied from the paper)
-
Multitask Prompted Training Enables Zero-Shot Task Generalization (Sanh et al., ICLR 2022)
Similar to FLAN, Sanh et al. introduces T0, a LM-adapted T5 3B (Lester et al. 2021) fine-tuned on mixture of NLP datasets via natural language instructions, to improve zero-shot performance on unseen tasks. T0 and its variants achieved similar performance w.r.t FLAN despite being much smaller.
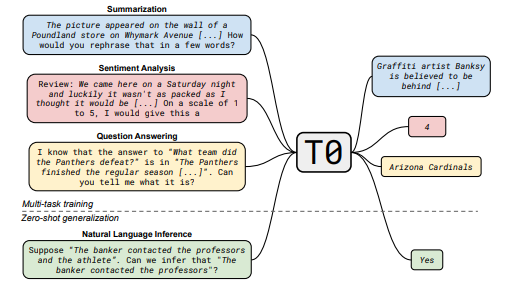
(source: copied from the paper)
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., Neurips 2022)
While scaling up a LM is not sufficient for improve the performance of LM on reasoning tasks, the paper presents Chain-of-Thought prompting to unlock the reasoning ability of large language models (yes, only large LMs, mentionned by the author) by decomposing the initial task into intermediate steps and solving each steps before outputing the final answer, just emulate the way human processes a complicated reasoning problem. Instead of finetuning or rationale-augmented training a LM which requires a larget dataset of {question, intermediate step, answer}, Chain-of-Thought Prompting is only performed on large language models (e.g GPT3, PALM) via in-context few-shot learning learning.
An example:

(source: copied from the paper)
-
Do Prompt-Based Models Really Understand the Meaning of Their Prompts? (Webson et al., NAACL 2022)
Under the \(k\)-shot scenerios (\(k=0..256\)) for NLI task, the paper finds that LMs learn irrelevant prompts, misleading prompts as fast as instructive prompts, and this is consistent across various models (GPT, BERT, T0, T5). This questions whether the models understand the semantics of the prompts or they are too robust to prompt semantics, making them distinguish proper instructions from pathological ones.
They also shows that LMs are more sensitive to the semantics of prediction labels. Learning to predict arbitrary labels (e.g. 1 for Yes, 2 for No) or reversed labels (e.g. No for Yes, Yes for No) is much slower than predicting directly the original labels (Yes/No). The choice of prediction labels can contaminate the semantics of prompt template. Proper prompt associated with arbitrary labels (e.g. 1 for Yes, 2 for No) underperformed irrelevant prompts associated with direct label (Yes/No). Intuitively, given a few samples, human can easily learn the mapping Yes \(\rightarrow\) 1, No \(\rightarrow\) 2.
2021
-
Prefix-Tuning: Optimizing Continuous Prompts for Generation (Li et al., ACL 2021)
Traditional fine-tuning of a LM model for a downstream task involves modifying all the model parameters, consequently, a single set of parameters can just work best for a single task. Inspired by prompting, prefix-tuning freezes the LM parameters and instead prepend to it a sequence of task-specific vectors \(P_{\theta}\) (aka. prefix): \([P_{\theta}; LM_{\phi}]\) that represent the downstream task, we optimize solely the prefix \(P_{\theta}\) using the task’s data to steer the LM to the task.
Prefix-tuning brings some advantages:
- A single LM is reused across different downstream tasks since its parameters are kept intact \(\rightarrow\) efficient storage.
- Only the prefix vector corresponding to the downstream task need to be optimized \(\rightarrow\) lightweight fine-tuning: much fewer parameters w.r.t. LM.
- Prefix-tuning can outperform full fine-tuning in low-data setting and have better generalization.
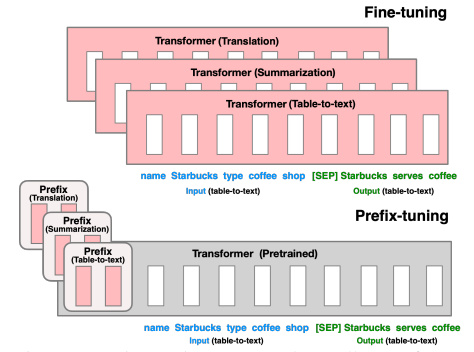
(source: copied from the paper)
-
The Power of Scale for Parameter-Efficient Prompt Tuning (Lester et al., EMNLP 2021)
Similarly to Prefix-Tuning, prompt-tuning learns task-specific “soft-prompts” (embedding) prepended to task-input (prefix) to steer the LM to perform the task without changing its parameters. While Prefix-Tuning prepends prefix activations to every layers in the encoder, prompt-tuning simplifies this by only adding k tunable tokens per downstream task to the input text at the input layer (without further interventions in intermediate layers) \(\rightarrow\) prompt-tuning has less parameters than Prefix-Tuning.
In addition, prompt-tuning is based on T5 that they found that prompt-tuning with T5 off-the-shelf as the frozen model is inefficient. T5 is pre-trained exclusively on span corruption marked with unique sentinel tokens. As prompt-tuning does not modify the model parameters, it risks to produce unnaturally sentinel tokens in the output. This issue is easily overcome by full fine-tuning. For this reason, before performing prompt-tuning, they continue to pre-train T5 with LM objective in order for the model to produce natural text output.
Other features of prompt-tuning:
- Performance scales with model size: the larger, the better.
- May improve the robustness to domain shifts: outperform in-domain fine-tuning on out-of-domain datasets.
- Efficient prompt ensemble: better than single prompt and parameter-efficient as the core LM is freezed and shared.
4. Tools-Augmented Language Model
2023
-
Toolformer: Language Models Can Teach Themselves to Use Tools (Schick et al., arxiv 2023)
Toolformer, a fine-tuned LM, is capable of deciding when to call APIS, which APIs to call, what arguments to pass, how to leverage API’s results in next token prediction.

(source: copied from the paper)
The key idea lies at self-supervised training where LM is first used to generate a dataset augmented with API calls via promting (Figure a) and filtering (Figure b). It is then fine-tuned on this dataset with regular LM objective.
(a)
 (b)
(b) 
(source: copied from the paper)
The generation of API-augmented dataset is illustrated in three steps:
- Sampling API calls (Fig. a): write prompt (with a few demonstrations) to ask the model to select k positions in the input text and add up to m API calls (e.g. Q/A API, calculator API, calendar API) at each position that are possible relevant for the prediction of next tokens.
- Executing API calls (Fig. b): independently execute API calls and get the results.
- Filtering API calls (Fig .c): as not all API calls generated by prompting are useful, this step filters out API calls whose results that do not improve the perplexity of future predicted tokens.
After filtering, remaining API calls (together with its results) are merged into the original dataset, resulting tool-augmented dataset, used to teach LM how and when to call external APIs.
-
React: Synergizing Reasoning and Acting in Language Models (Yao et al., ICLR 2023)

(source: copied from the paper)
React is a prompting method that combine Chain-of-thought (Re in React stands for Reasoning) and interfacing with external-API (act in React stands for action) to reduce the hallucination as well as to improve interpretability and trustworthiness of LLMs. The external API considered in this work is Wikipedia API, supporting 3 actions: (i) search[entity] return the first 5 sentences of the entity’s wiki page; (ii) lookup[string] return the sentence containg the string; (iii) finish[entity] finishes the task and return the answer. It should be noted that the first two actions are based on simple exact matching.
React outperforms CoT on Fever task and slightly lags behind CoT on HotpotQA task. With much fewer demonstrations (3-5 samples), React + CoT + Self-consistency (SC) performs best across tasks and reach the CoT-SC (with 21 samples) performance.
In addition, on HotpotQA task, React does not work well with smaller pretrained-model (i.e. PaLM-8/62B). However, it gives the best performance with the fine-tuned PaLM-8/62B, even compared with the larger freezed PaLM-540b.
-
Binding Language Models in Symbolic Languages (Cheng et al., ICLR 2023)
5. Misc
2023
-
Task-Specific Skill Localization in Fine-tuned Language Models (Panigrahi et al., ICML 2023)
-
Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models (Liu et al., ICML 2023)
-
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining (Xie et al., arxiv 2023)
-
Data Selection for Language Models via Importance Resampling (Xie et al., arxiv 2023)
The paper presents DSIR, an efficient and scalable for selecting additional relevant data from a large raw unlabeled dataset (e.g. the Pile) that match
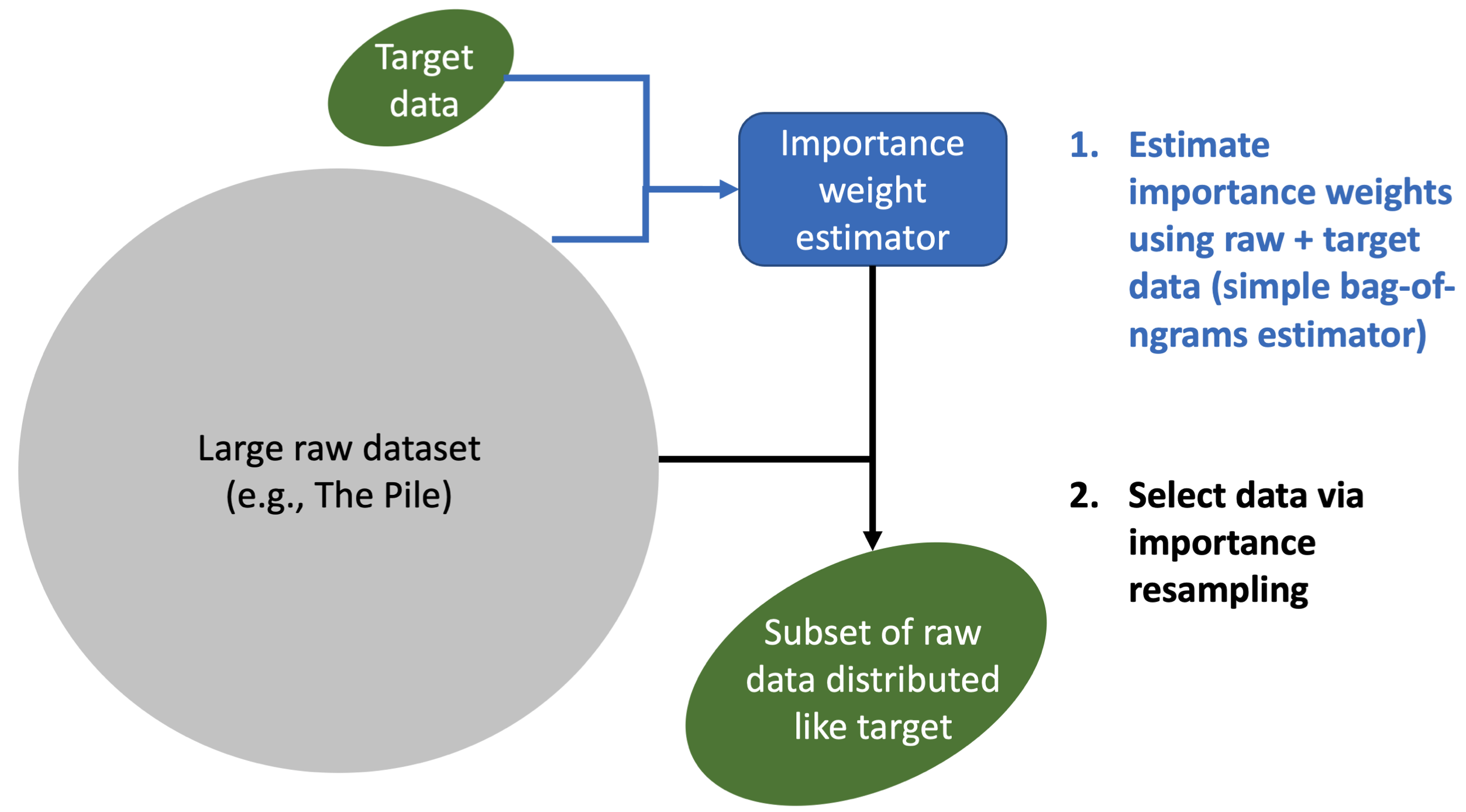
(source: copied from the paper)
-
Language Models represent Space and Time (Gurnee et al., arxiv 2023)
In line with Emergent World Representations - Exploring a Sequence Model Trained on a Synthetic Task, this paper discovers that LLMs learn latent representations that are relevant to the input fed to it. Specifically, when feeding the names of locations in the world (e.g. cities, countries) into LLM, the spatial information (i.e. longitude and lattitude) of the locations are encoded in internal neurons. In other words, the coordianates of locations can be linearly recovered from the activations of the mid-to-late layers of LLMs.
-
Can Foundation Models Wrangle Your Data? (Narayan et al., VLDB 2023)
The paper investigates the capability of generative LLMs (i.e. GPT3) on data wrangling tasks: entity matching, data imputation, error detection:
- Generative LLM benefits unifed framework for multi-task learning (task-agnostic architecture).
- Select a subset of entity’s attribute for entity matching is non-trivial.
- Performance is sensible to prompt formatting (even with minor modification in prompt) and demonstrations.
-
Ranking and Tuning Pre-trained Models: A New Paradigm for Exploiting Model Hubs (You et al., JMLR 2023) + LogME: Practical Assessment of Pre-trained Models for Transfer Learning (You et al., ICML 2021)
Given the deluge of available pre-tranined models \(\{\phi_m\}_{m=1}^{M}\), it is challenging to pick the model that can yeild the best transfer learning on target down-stream dataset \(\mathcal{D} = \{(x_i, y_i)\}_{i=1}^n\).
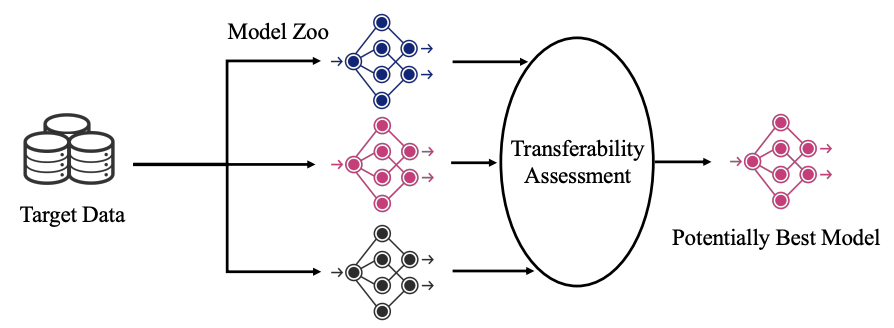
(source: copied from the paper)
Formally, each pretrain-model \(\{\phi_m\}\) fine-tuned on \(\mathcal{D}\) has ground-truth transfer performance \(T_m\) (e.g. accuracy, MAP, MSE, etc). As computing all \(T_m\) for all models is prohibitively expensive as \(M\) grows, it is more relevant to have a score \(S_m\) for model \(\{\phi_m\}\) without fine-tuning it on \(\mathcal{D}\) in such a way that \(S_m\) should well correlate with \(T_m\). Thereby, the ranking of pre-trained model w.r.t. \(\mathcal{D}\) can be based on \(S_m\), instead of \(T_m\). The correlation between \(S_m\) and \(T_m\) is measured by Kendall’s \(\tau\) coefficient:
\[\tau = \frac{2}{M(M-1)} \sum_{1 <=i < j <= M} sign(T_i - T_j) sign(S_i - S_j)\]The larger \(\tau\), the better the ranking of \(\{\phi_m\}_{m=1}^{M}\) models.
\(S_m\) is computed as the probability \(p(y \vert F)\) where \(y \in R^n\) is the label vector of \(n\) (i.e. scalar label) samples, \(F = \{ f_i = \phi_m(x_i) \}_{i=1}^n \in R^{n \times D}\) is feature vectors extracted by \(\phi_m\). Common solution to estimate \(p(y \vert F\) is to train a regression model \(w\) (similar to apply a linear layer on top of neural model for transfer learning) on \((F, y)\) maximizing the likelihood \(p(y \vert F, w)\). However, this approach has shown to be prone to over-fitting. Alternatively, these papers propose LogME which marginalizes \(p(y \vert F, w)\) over all values of \(w\): \(p(y \vert F) = \int p(w) \times p (y \vert F, w)\). To make it tractable, both prior \(p(w)\) and likelihod \(p(y \vert F, w)\) are assumed to have normal distribution parameterized by \(\alpha\) and \(\beta\): \(p(w) = \mathcal{N} (0, \alpha^{-1}I)\), \(p (y_i \vert f_i, w) = \mathcal{N}(y_i \vert w^Tf_i, \beta^-1)\).
\(\alpha\) and \(\beta\) are estimated by an iterative algorithm (see section 4.2)
(source: copied from the paper)
Experimented on GLUE benchmark with 8 popular pre-trained LMs, the result shows that \(S_m\) represented by LogME well correlates with ground-truth fine-tuned accuracy \(T_m\).

(source: copied from the paper)
-
On Exploring the Reasoning Capability of Large Language Models with Knowledge Graphs (Lo et al., GenIR@SIGIR 2023)
The paper investigates the zero-shot performance of LLMs (particularly text-davinci-003, ChatGPT and GPT4) in infering missing entities/relations in KG or predicting a predicate path between two given entities. Specifically, they seek to see whether LLMs are capable of recalling their internal knowledge graph that supposed to be learnt during the pre-training and reason with it to solve the tasks.
Results: while text-davinci-003, ChatGPT struggles, GPT-4 shows pretty impressive accuracy for 1-hop entity/relation prediction, and especially for multi-hop relation (predicate path) prediction given the context document without instruction/task decomposition (see below).

(source: copied from the paper)
-
Towards Robust and Efficient Continual Language Learning (Fisch et al., arxiv 2023)
Given the availability of numerous model checkpoints fine-tuned on different previous task \(\{t_1,.., t_n\}\), this paper introduces an approach to learn a checkpoint selector that help to pick the most relevant checkpoint of a previous task \(t_i\) as base model to fine-tune the new task \(t_{n+1}\) if exist, otherwise, it’s better to start off with the pretrained model rather than with a random checkpoint that could yield negative impact.
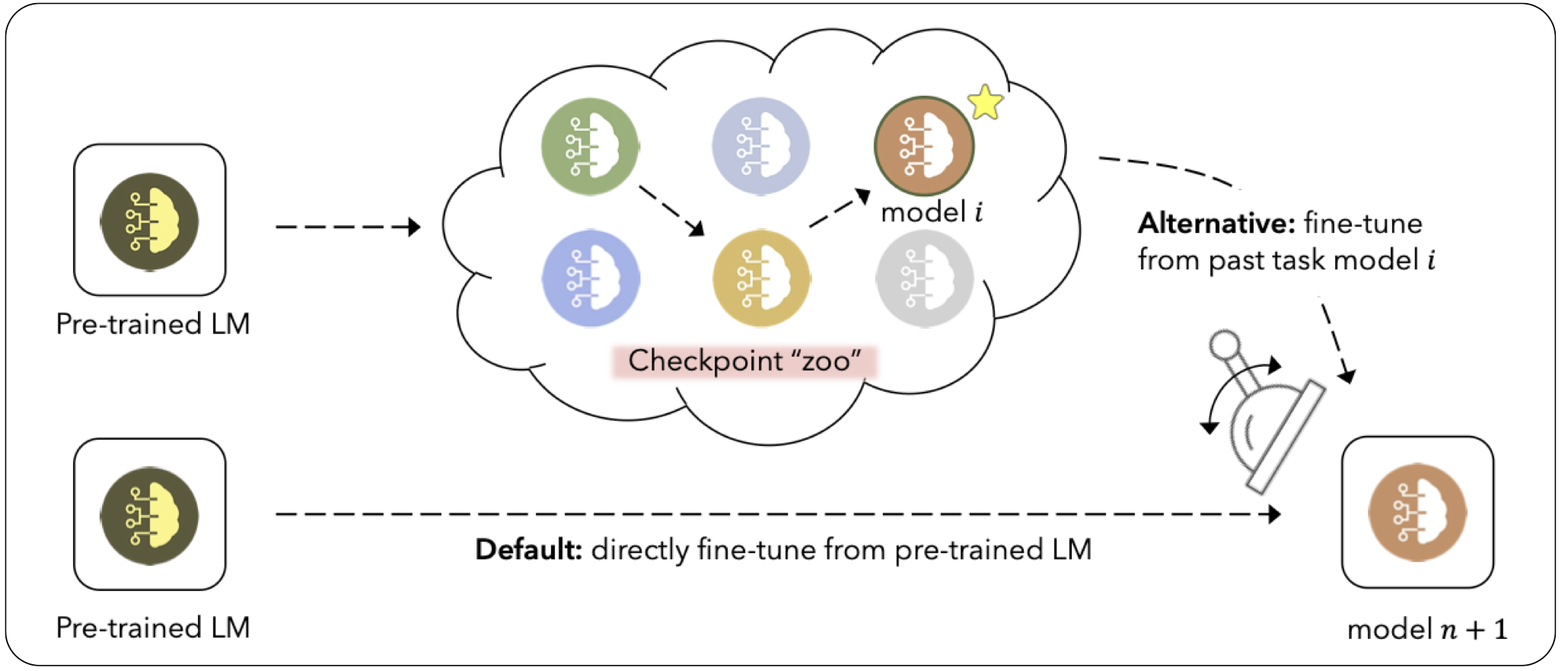
(source: copied from the paper).
The checkpoint selector is a simple binary gradient boosted decision tree (GBDT) applied on the features \(\phi(t_i, t_{n+1})\) between previous task \(t_i\) and target task \(t_{n+1}\) to determine whether model’s parameters fine-tuned for \(t_i\) is a good initialization for \(t_{n+1}\). Specifically, features include:
- task metadata: 1 if \(t_i\) and \(t_{n+1}\) belongs to the same pre-defined task family, 0 otherwise.
- relative performance: relative 0-shot and 5-shot performance of model fine-tuned on \(t_i\), then \(t_{n+1}\) w.r.t. model fine-tuned uniquely on \(t_{n+1}\).
- gradient-update similarity: similarity between average magnitude of weight change of model fine-tuned on \(t_i\), then \(t_{n+1}\) and model fine-tuned uniquely on \(t_{n+1}\).
-
Beyond Scale: the Diversity Coefficient as a Data Quality Metric Demonstrates LLMs are Pre-trained on Formally Diverse Data (Lee et al., ICML 2023)
-
Textbooks Are All You Need (Gunsasekar et al., arxiv 2023)
The paper introduces pi-1, a 1B decoder-only LLM trained of high-quality code book that competes with many much larger sized models. The recipe for success comes from the careful selection of data for training and fine-tuning. Author inspects the popular datasets used to train sota Code-LLMs (e.g. The Stack) and discovers several drawbacks that may hindle model from effective learning:
- Many codes are not self-contained. They depend on extenal moduls or files.
- Many codes do not contain meaningful semantics, but trivial texts.
- Many codes are not well documents, making them difficult to learn from.
- Skewed distribution of topics/concepts in the dataset.
From those intuitions, authors propose to select and generate a much smaller but higher quality corpus:
- A filter code-language dataset (6B tokens) filterd from The Stack and StackOverflow. How the filterd is built ? First, GPT-4 is used to annotae ~100K code-examples with two labels: high education value and low educational value. Then, a random forest classifier is trained on the embeddings retrieved from a pretrained codegen model of those 100K examples to predict the label.
- A synthetic textbook dataset consists of <1B tokens, generated by GPT-3.5. The diversity of generated text book is controlled by constraining the topics and target audiences in the prompt.
- A smal synthetic Python exercises dataset of ~180M tokens is used to further fine-tune the model, playing the same role as instruction-tuning, making model better align with natural language instructions.
The last fine-tuning step is proved to be important, that leads to subtaintial improvement in generalizing to new tasks. Indeed, the fine-tuned model is capable of distilling easier seen tasks from pretraining (e.g. calling external libraries more logically). An example is illustrated below (phi-1 and phi-1-small are models fine-tuned with synthetic Python exercises while phi-1-base is not.)

(source: copied from the paper).
-
Evaluating and Enhancing Structural Understanding Capabilities of Large Language Models on Tables via Input Designs (Sui et al., arxiv 2023)
This work introduces Structural Understanding Capabilities (SUC) benchmark to assess whether LLMs can truly understand structured tabular data. The benchmark includes 5 tasks: table partition (detect the location of table in the context), table size detection, merged cell detection, cell lookup (return the mention given its row/column index), column&row retrieval (return the column values given its index). They discovered that LLMs have some basic understading of structural tabular data, but are still far from being good.
Experimented with GPT-3 family, results demonstrate that:
- Use markup language such as HTML rather than NL to represent table gives significant gain.
- In-context learning with one demonstration outperforms zero-shot, suggestings that model needs examplars to understand the structural information.
- Additional information (e.g. table formation explaination) shoud be placed ahead the table in the context
- Adding table format explaination to the context (e.g. “Each table cell is defined by a <td> and a </td> tag” ) is generally helpful.
- Self-augmented prompting (see figure below): similarly to CoT, before tackling the target task, several intermediate steps are performed to elicit the structural knowledge learned by LLMs during pretraining, such as asking LLM to identify critical elements in the table.
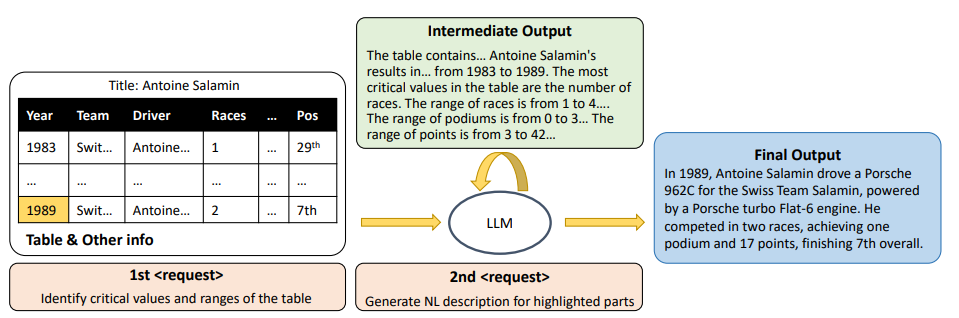
(source: copied from the paper).
-
Benchmarking Large Language Model Capabilities for Conditional Generation (Joshua et al., ACL 2023)
Similar to HELM benchmark, this paper introduces a holistic benchmark to evaluate the generation quality of autoregressive LLMs via automatic metrics. The benchmark collects data-to-text and text-to-text datasets (27 in total).
Observations:
- Few-shot learning falls behind full finetuning. However, multiple tasks have finetuning performance saturated, suggesting there is no clear trend when scaling the models.
- Finetuned decoder-only LLM can match encoder-decoder LLM when scaling to large size.
- Overlap-based metrics is not suitable for evaluating few-shot learning as it is sensitive to generation length and LLMs struggle to predict output length properly given the demonstrations in the context.
- The model ranking can still be reliable when considering a small random subset of the test set (to mitigate the computational cost while performing inference with LLMs). Specifically, (1) randomly sampling n samples and recording the scores of models on those samples, then ranking them based on the scores; (2) perform Wilcoxon Rank Sum test on every pair of models to assess if two models yeilds the same ranking according to a p-value; (3) repeate (1) and (2) k times and count number of times that any pair of models results inditinguisable ranking (according to step (2)).
-
Lost in the Middle: How Language Models Use Long Contexts (Nelson et al., arxiv 2023)
This work empirically analyzes how well LLMs use longer context through two tasks: open-domain QA and key-value retrieval (i.e. the context contains a dictionary of {UUID_key: UUID_value} and model is asked to return the value of a specific key).
They observe an U-shaped performance curve as a function of the position of relevant information in the context. In other words, the models perform best when relevant information is located at the beginning or the end of the context. Even for key-value retrieval task, if requested key is in the middle of the dictionary, several models still struggle to get the correct value. Additionally, model performance substaintially decreases as input contexts grow longer.
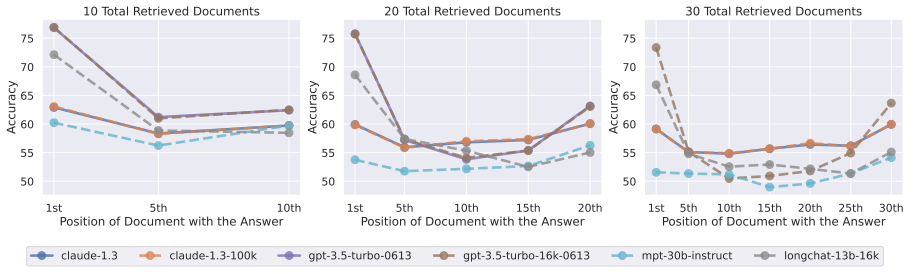
(source: copied from the paper).
Ablation study suggests that encoder-decoder models may exploit better the longer context due to their bidirectional encoders. Placing the query ahead of the context or using instruction-tuning still exhibits the U-trend performance. Finally, for open-domain QA, it is still questioning whether using more context leads to sigificant improvement. Indeed, the performance undergoes a statureation zone as the context grows.
-
Faith and Fate: Limits of Transformers on Compositionality (Dziri et al., arxiv 2023)
Transformers, on the one hand, can perform impressively on complex task. On the other hand, it can fail suprisingly on trivial tasks. This paper attemps to understand whether this paradox is incidental or substantial limitations of transformer. They investigates three compositional tasks including multi-digit multiplication and dynamic programming. A compositional task can be decomposed into multiple sub-tasks which can be representad as a computation graph and requires cohenrent step-by-step reasoning to arrive at the correct answer. An example of multi-digit multiplication is illustrated as below:
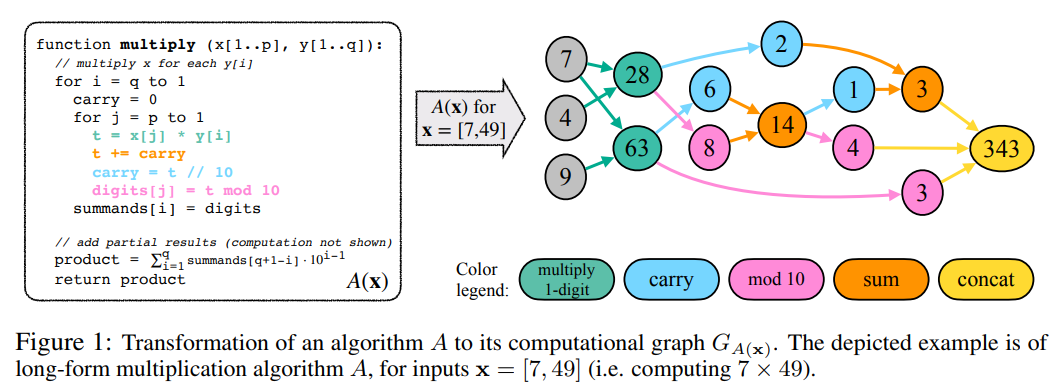
(source: copied from the paper).
Author quantifies the performance of transformer as a function of:
- reasoning depth: the length of the longest path from answer node to input node.
- reasoning width: (TBD: unclear for me at the time of writing)
- relative Information Gain: quantify the (normalized) gain of input nodes contributed to output nodes.
Considering multi-digit multiplication tasks, the paper shows several empirical evidences on the limit of Transformer:
- All settings (zero-shot, in-contexts with and without scratchpad, full finetuning) yield poor OOD generalization (i.e. model trained on {1,2,3}-digit multiplication and tested on {4,5}-digit multiplication which requires wider and deeper computation graph. Full fine-tuning is better than other settings.
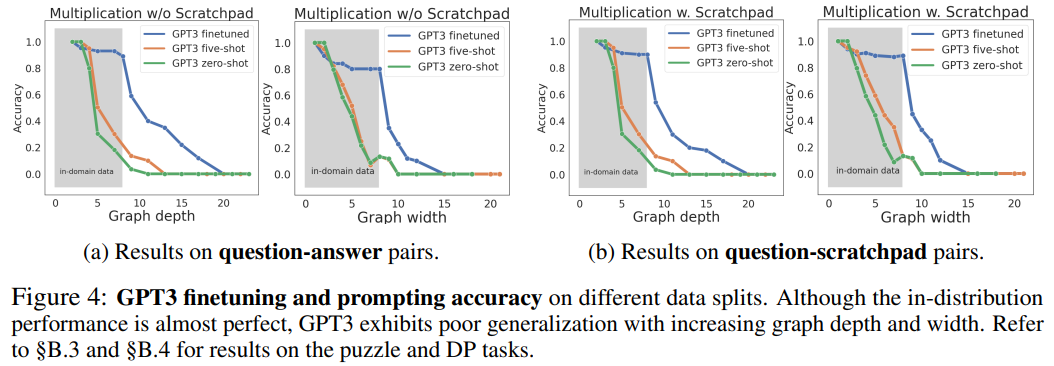
(source: copied from the paper).
-
Relative information gains reveal that several (spurious) correlations between input and output (e.g. first digit of output highly correlates with first digit of input) are learned. Hence, to some extent, the input is mapped directly to the output without actually executing the multi-hop reasoning over the computation graph.
-
Even though a full computation graph in test set is unseen in training set, its subgraphs do appear in the training set. Consequently, the model can memorize or matches patterns, helping it make correct predictions. However, this does not imply that model has learned a generalized reasoning capabilitities.
-
A large propotion of error is propagation error and restoration error, suggesting: (i) model can perform correct single-step intermediate reasoning, but fail to compose the whole reasoning pipeline, (ii) due to memorization, output can have precise value but the computation steps are incorrect.
-
Improving Representational Continuity with Supervised Continued Pretraining (Sun et al., arxiv 2023) + Fine-tuning can distort pretrained features and underperform out-of-distribution (Kumar et al., ICLR 2022)
The paper title says it all. In the pretraining-then-finetuning paradigm, if the pre-trained features are good and the distribution shift between the fine-tuning data (in-domain) and the testing data (out-domain OOD) for downstream task is large, then fine-tuning outperforms (resp. underperforms) linear probing (only update the last linear layer) on in-domain test data (resp. OOD test data).
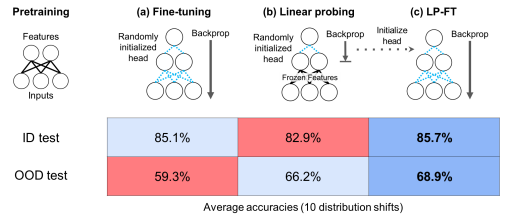
(source: copied from the paper).
Author employs a toy example (\(output = w_{*} x\)) to illustrate this issue.
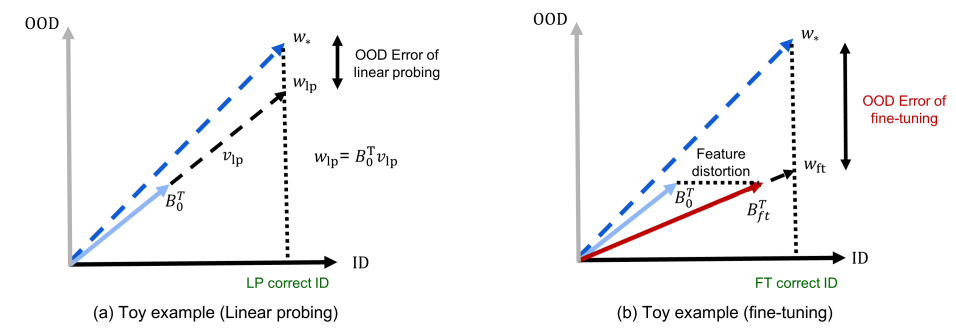
(source: copied from the paper).
\(B_0\) is the pretrained feature. \(w\) is learned weights mapping input \(x\) to output \(y\). For fine-tuning, both \(B_0\) and head layer \(v\) needs to be updated. Assuming the subspace spanning in-domain data (horizontal axis \(x_1\)) is orthogonal to the subspace spanning OOD data (vertical axis \(x_2\)), then fine-tuning with in-domain data only modifies \(B_{x_1}\) while \(B_{x_2}\) keeps unchanged (vector in red color). They say pretrained features are distorted. Consequently, fine-tuning pushes the learned \(w_{ft}\) far away from the true \(w_{*}\) despite that \(w_{ft}\) still yields good performance on in-domain data, but worse performance on out-domain data.
To mitigate this distribution shift, author proposes a simple strategy: linear probing then fine-tuning. Linear probing is performed first to get a better initialization of the head layer, then, the whole model parameters are updated with fine-tuning.
This paradigm is also beneficial for continual learning to help the model forget less the old tasks. Specifically, for each new task, the head layer is updated first by linear probing while others layers are freezed. Then, the fine-tuning updates all layer’s parameters.
-
Can Language Models Solve Graph Problems in Natural Language? (Wang et al., arxiv 2023)
LLMs are more and more adopted for tasks involving graphical structures. can LLMs reason with graphs?. The paper introduces the Natural Language Graph (NLGraph) benchmark including 29370 problems encompassing 8 graph reasoning tasks of different complexity. The graph in each problem is generated with controlled complexity level: number of edges, nodes, paths.
(source: copied from the paper)
Observations:
- LLms have prilimiary ability to handle simple graph reasoning task like connectivity, cycle and shorted path task. However, they tend to rely on, to some extent, the spurious correlation (e.g. node frequency vs. node connectivity) to make prediction.
- In-Context Learning with demonstrations underperforms zero-shot learning for complex structured reasoning tasks: hamilton path, bipartie graph matching.
- Two prompting methods are proposed to improve the graph reasoning: (i) build-a-Graph prompting: append the instructionn: “Let’s construct a graph with the nodes and edges first” to the task description; (ii) algorithmic prompting: append the description of an algorithm that could be employed to reason the graph, such as depth-first-search for the shortest path task.
Above all, the performance of LLM for complex graph structured task remains unsolved.
-
Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning (Creswell et al., ICLR 2023)
-
Trusting Your Evidence: Hallucinate Less with Context-aware Decoding (Shi et al., arxiv 2023)
LMs sometiems do not pay enough attention to the context given to it and over-rely on prior knowledge it learned in the pretraining. This could be an issue in case there is factual contradict between the prior knowledge and the context.
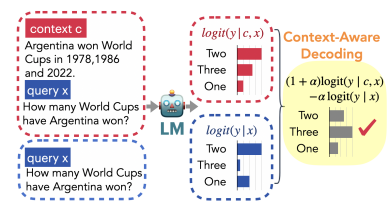
(source: copied from the paper)
This paper proposes context-aware decoding that integrates into the original output distribution with the pointwise mutual information (PMI) between the context \(c\) and the output \(y\) factoring out the contribution of prior knowledge:
\[y_t \sim softmax[(1+\alpha) \, logit_{\theta} (y | c, x) - \alpha \, logit_{\theta} (y | x)]\]where large \(\alpha\) means more attention to the context \(c\). (\(\alpha\) is empirically determined at 0.5)
context-aware decoding consistenly improve the performance of various LLMs (e.g. LLaMa, FLAN, OPT) on summarization tasks and knowledge conflict related task such as MemoTrap.
-
CodeT5+: Open Code Large Language Models for Code Understanding and Generation (Wang et al., arxiv 2023)
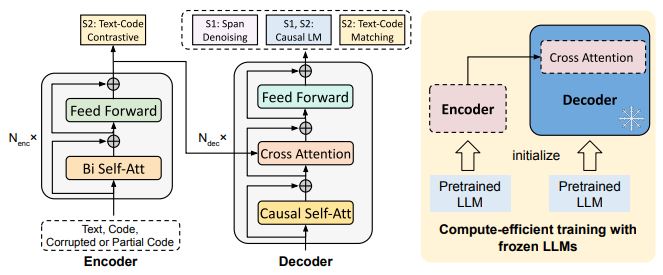
(source: copied from the paper)
CodeT5+, an enhanced version of code language model CodeT5. Through a mixture of pre-training objectives as well as using both unimodal (only code) and bimodal (code-text) corpora, the encoder and decoder have strong representation capability that mitigate the pretrain-finetune discrepancy. Specifically, the pre-training objectives are:
- Span Denoising: similar to T5
- Causal language modeling: (i) generate the second part of a code function given the first part, (ii) generate the whole code function given a special token [CLM]
- Text-Code Contrastive Learning: to align the representation space of code and text, the encoder is trained with contrastive learning where positive code-text pairs are pulled together and negative ones are pulled apart. [CLS] is appended to the input sequence (code or text) and regarded as the representation of the input.
- Text-Code Matching: the encoder takes in a text, the decoder takes in a code, a special token [EOS] is appended to the end of the code and its embedding is used to train a binary classifier, predicting whether the text matches (or unmatches) the code
- Text-Code Causal LM: the encoder takes a text (resp. a code) and the decoder generates the corresponding the code (reps. text).
- Instruction tuning: to align the model with natural language instructions.
With the intuition that the generation in the decoder may have a higher degree of complexity than the encoding in the encoder, CodeT5+ employs “shallow encoder and deep decoder” architecture. Furthermore, for an efficient pretraining, only the encoder’s layers and cross-attention layers are trainable, while the decoder is freezed.
-
Emergent World Representations: Exploring a Sequence Model Trained On a Synthetic Task (Li et al., ICLR 2023).
refer to blog
-
Quantifying Memorization Across Neural Language Models (Carlini et al., ICLR 2023)
Definition of memorization in this paper:
A training sample s is extractable with k tokens of context from a model f if the model can produce exactly s[k:] using greedy decoding when prompted with s[:k].Several key observations:
- Bigger models memorize more. By comparing with a baseline model which has not seen the test data before, they conclude that the model actually memorizes data.
- It is easier to memorize repeated data.
- Longer prompt (large k) invoke more memorized data.
2022
-
I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation (Bhagavatula et al.):
while common sense statements are simple, clear and short, text generated by small LM can be often trivially long or repetitive. To improve the generation quality, NeuroLogic Decoding enforces logical constraints at decoding time (e.g. limiting number of function words such as “in”, “on”, or excluding connective words such as “although”, “since”, or a given word must be generated).
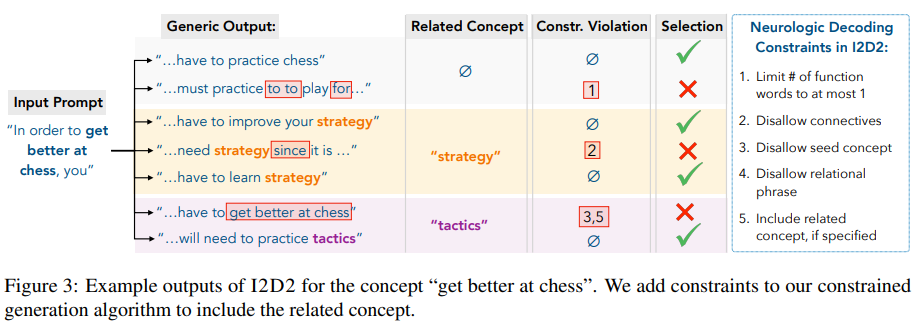 (source: copied from the paper). (source: copied from the paper).
(source: copied from the paper). (source: copied from the paper). -
Symbolic Knowledge Distillation: from General Language Models to Commonsense Models (West et al., NAACL 2022)
Manually crafting a high-quality common sense knowledge graph to teach a common sense model is expensive, hard to scale, hence, resulting a knowledge repository with limited coverage. Based on the intuition that a LLM (e.g. GPT-3) contains a vast amount of knowledge, but may be noisy and not fully exploitable, authors propose to distill high-quality commonsense knowledge from this LLM (referred to as the teacher model) through prompting (e.g. “X goes jogging. Prerequisites: For this to happen,__”) and filtering the prompt’s results by a small critic model. The critic model is fine-tuned on a set of correct vs. incorrect human judgements on a randomly sampled set of knowledge extracted (but unfiltered) from GPT-3. As a result, for the first time, they obtain ATOMIC, a commonsense KG, automatically distilled from GPT-3, outperforms human-curated KG in three criteria: quantity, quality and diversity.
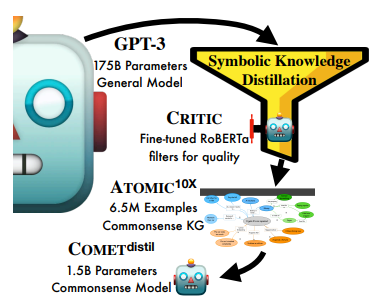 (source: copied from the paper).
(source: copied from the paper).Subsequently, the distilled commensense KG is employed to train a much smaller model (GPT-2 XL), resulting a knowledge model, COMET_DISTIL, surpassing the commonsense of GPT-3.
-
Efficient Training of Language Models to Fill in the Middle (Bavarian et al., arxiv 2022).
Casual decoder-only LLMs (AR) are overwhelming thanks to their superiority in open-ended text generation, in-context learning and pre-training computational efficiency. Unlike encoder-only or encoder-decoder models, AR models are pre-tranined in left-to-right fashion, hindering them from infilling tasks that needs to condition on both prefix and suffix. This paper proposes Fill in the Midle (FIM) pretraining for AR models that improve its infilling capability without compromising its left-to-right generative capability. It is performed by simply breaking the training sample into three pieces, seperated by sentinel token, then concatenate them and feed into the model:
\(\textsf{document} \rightarrow \textsf{[PRE] Enc(prefix) [SUF] Enc(suffix)} [MID] Enc(middle) [EOT]\) (PSM style) or \(\textsf{document} \rightarrow \textsf{[SUF] Enc(suffix) [PRE] Enc(prefix)} [MID] Enc(middle) [EOT]\) (SPM style). Token [EOT] is important as it marks a sucessful join of middle span to the suffix/prefix. Fill in the Midle (FIM) is particularly useful for code domain, in applications such as docstring or function argument generation, where the model need to look before and after the point of generation.

(source: copied from the paper)
-
Language Models of Code are Few-Shot Commonsense Learners (Madaan et al., EMNLP 2022).
CoCoGen shows that Code-LLMs outperforms natural-LLMs for structured data-related tasks or structured commonsense reasoning tasks such as graph generation, graph reasoning.
(source: copied from the paper)
The intuition is that it is easier and more informative to convert structured data into code rather than serializing it into plain-text. Consequently, this helps to narrow the gap between fine-tuning data and pre-training data in Code-LLMs.
Through experiments on script generation task (PROSCRIPT: generate a graph [nodes, edges] given a goal or predict the edge set given the goal and the node set) and entity state tracking task (PROPARA: predict the state of an entity after an action), CoCoGen achieve several remarks:
- Few-shot Code-LLMs outperform few-shot NL-LLMs of similar size or fine-tuned-LLMs in all semantic and structural metrics.
- Impressive performance of Code-LLms in edge-genration task suggest that Code-LLMs are highly capable of capturing structure.
- Code-LLMs reasons better than NL-LLMs, via tracking better the state of entitiy after a series of actions.
- Both code-like prompts and Code-LLMs are important for the performance improvement of structured-related task.
- Prompts that are more similar to the conventions of typical code may benefit more gains.
- Automatic metrics proposed in CoCoGen (i.e. semantic and structural metrics correlates) with human evaluation.
-
Fast Model Editing at Scale (Mitchell et al., ICLR 2022).
-
Locating and Editing Factual Associations in GPT (Meng et al., Neurips 2022).
-
Understanding Dataset Difficulty with V-Usable Information (Ethayarajh et al., ICML 2022).
refer to blog
-
A Contrastive Framework for Neural Text Generation (Su et al., NeurIPS 2022).
Aiming at avoiding repetition patterns while maintaining semantic coherence in generated text, constrastive search introduces a degeneration penalty into the decoding objective. This degeneration penalty compares the cosine similarity between a token at current decoding step and all generated tokens at previous decoding steps. The closer the token is to precedent decoded text (more likely leading to repetition), the larger the penalty it receives.
-
The Trade-offs of Domain Adaptation for Neural Language Models (Grangier et al., ACL 2022)
This paper provides some evidences using concepts of machine learning theory to support past prevailing empirical practices/observations for domain adaption of LM.
1. In-domain training
The loss of fitting a LM to a domain \(\mathcal{D}\) is decomposed as 3 components: \(\mathcal{L} (\theta_D, \mathcal{D}) = \mathcal{L}_H(\mathcal{D}) + \mathcal{L}_{app} (\mathcal{D}, \Theta) + \mathcal{L}_{est} (\mathcal{D}, \Theta, D)\) where
- \(\mathcal{L}_H(\mathcal{D})\) is the intrinsic uncertainty of the domain \(\mathcal{D}\) itself.
- \(\mathcal{L}_{app} (\mathcal{D}, \Theta)\) is the approximation error of using a LM parameterized by \(\theta \in \Theta\) to approximate the true distribution \(P( \bullet \mid \mathcal{D})\) over domain \(\mathcal{D}\): \(\mathcal{L}_{app} (\mathcal{D}, \Theta) = \min_{\theta \in \Theta} \mathcal{L}(\theta; \mathcal{D}) - H(P( \bullet \mid \mathcal{D}))\) where \(\mathcal{L}(\theta; \mathcal{D})\) is the expectation of risk of using LM \(P(\bullet \mid \theta)\) to approximate true distribution \(P(\bullet \mid \mathcal{D})\): \(\mathcal{L}(\theta; \mathcal{D}) = -\sum_{y \in \mathcal{D}} log \; P(y \mid \theta) P(y \mid \mathcal{D})\). Larger model with deeper, wider layers has more capacity, consequently, can reduce this error.
- \(\mathcal{L}_{est} (\mathcal{D}, \Theta, D)\) is the error of using the LM parameters empirically estimated from a subset \(D \subset \mathcal{D}\) to represent the true distribution \(P(\bullet \mid \mathcal{D})\): \(\mathcal{L}_{est} (\mathcal{D}, \Theta, D) = \mathcal{L} (\theta_D, \mathcal{D}) - \min_{\theta} \mathcal{L}(\theta; \mathcal{D})\) where \(\theta_D = arg \min_{\theta \in \Theta} \mathcal{L} (\theta, D)\).
For a given training set size, increasing the size of the model can decrease \(\mathcal{L}_{app} (\mathcal{D}, \Theta)\) but can increase \(\mathcal{L}_{est} (\mathcal{D}, \Theta, D)\) due to overfiting \(\rightarrow\) \(\mathcal{L}_{app} \; vs. \; \mathcal{L}_{est}\) trade-off or VC-dimension trade-off.
2. Out-of-domain training
Given two LMs pretrained on two generic domaines \(\mathcal{D}\) and \(\mathcal{D'}\), which one we should choose to adapt it to a target domain \(\mathcal{T}\) ?. Intuitively, we choose the one whose distribution is closer to the target distribution \(\mathcal{T}\) or KL divergence between two distributions is smaller as the generalization loss of adapting LM parameters \(\theta_D\) estimated from generic domain \(\mathcal{D}\) for \(\mathcal{T}\) is upper-bounded by the KL divergence \(KL(\mathcal{D}, \mathcal{T})\)
\[\forall \epsilon, \exists D \subset \mathcal{D}, \mathcal{L}(\theta_D; \mathcal{T}) \leqslant H(\mathcal{T}) + KL(\mathcal{D}, \mathcal{T}) + \epsilon\]3. Fine-Tuning & Multitask Learning
Pre-training a LM on a large out-of-domain corpus \(D\) then fine-tuning it on a small in-domain corpus \(T\) implicitly involves the trade-off between empirical losses over \(T\) and \(D\). This trade-off is controlled by the number of fine-tuning steps \(n_{ft}\): \(\parallel \theta_{ft} - \theta_D \parallel_2 \;\leqslant \lambda n_{ft} g_{max}\) where \(\lambda\) is maximum learning rate, \(g_{max}\) is upper bound of update norm. More fine-tuning steps \(n_{ft}\), larger possible distance between \(\theta_{ft}\) and \(\theta_D\) is, meaning that \(\theta_{ft}\) could be no longer optimal for \(D\) where \(\mathcal{L}(\theta_{ft}; D)\) may be far from the optimum \(\mathcal{L}(\theta_{D}; D)\). For this reason, fine-tuning is also considered as a regularization technique.
-
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models (Tirumala et al., Neurips 2022)
The paper presents a large-scale study of the dynamics of memorization over LM training. The metric exact memorization \(M(f)\) of a LM \(f\) is defined as the proportion of times the LM \(f\) predicts the gold token for the masked token in training dataset. Given a threshold \(\tau\), \(T(f, \tau)\) is the minimal number of times (i.e. training epoches) the model \(f\) needs to see each training sample in order to satisfy \(M(f) \geq \tau\).
Some empirical findings about \(M(f)\) and \(T(f, \tau)\) are:
- Larger causal LMs memorize faster. Smaller masked LMs memorize quicker initially (lower \(\tau\)) and slower in the long run (larger \(\tau\)).
- The studied memorization occurs before overfitting \(\rightarrow\) overfitting cannot explain why larger models memorize faster.
- Learning ability of large LMs are less sensitive to learning rate.
- Prepending a unique identifer to every traing samples leads to faster memorization.
- LMs memorize nouns, proper nouns, numeral values earlier than adjectives, verbs.
- The forgetting curve has a lower bound and this value increases as the model become bigger \(\rightarrow\) large models forget less.
-
From zero-shot to few-shot Text Classification with SetFit (Tunstall et al., ENLSP at Neurips 2022)
SetFit is a few-shot text classifier (e.g. sentiment analysis) based on Sentence Transformer. Speaking of its performance,
With only 8 labeled examples per class on the Customer Reviews (CR) sentiment dataset, SetFit\(_{MPNET}\) (110M parameters) is competitive with fine-tuning RoBERTa Large (355M parameters) on the full training set of 3k examples 🤯. (Source: https://huggingface.co/blog/setfit)
In zero-shot setting, we can generate some very simple samples for each classification label (e.g. 8 samples per label) to make it a few-shot learning problem. For example, in the sentiment analysis task, using template “This sentence is about {}”, a positive sample for label “joy” can be “This sentence is about joy”, for label “sadness” can be “This sentence is about sadness”, etc.
-
Improving Language Models by Retrieving from Trillions of Token (Borgeaud et al., ICML 2022)
2021
-
Adapt-and-Distill: Developing Small, Fast and Effective Pretrained Language Models for Domains (Yao et al., ACL Findings 2021)
To adapt a general domain LM to a specific domain, it is necessary to augment the original vocabulary with domain-specific subwords or terms (original vocabulary is kept intact). The paper proposes a simple method to determine domain-specific tokens to add to the vocabulary.
It assumes that each subword \(x_i\) is independent of another and it is assigned a probability \(p(x_i)\) equal to its frequency in the corpus:
\(\forall i \; x_i \in \mathcal{V}, \; \sum_{x_i \in \mathcal{V}} p(x_i) = 1\) where \(\mathcal{V}\) is the vocabulary.
and the log probability of a sentence \(x\) consisting of a subword sequence \(x = (x_1,...,x_M)\) is given by: \(P(x) = log \prod_{i=1}^{M} p(x_i) = \sum_{i=1}^{M} log \; p(x_i)\)
Given a domain-specific corpus D consisting of \(\mid\)D\(\mid\) sentences, the likelihood of D is calculated as: \(P(D) = \sum_{x \in D} log \; P(x)\).
The original vocabulary is iteratively enriched with subwords taken from domain corpus D. At the time step \(i\), a subset of subwords with highest frequency in D is added to the vocabulary, which helps to improve the likelihood \(P(D)\). The procedure continues if the likelihood gain w.r.t. previous time step \(i-1\) is higher than a threshold \(\delta\): \(\frac{P_{i} (D) - P_{i-1} (D)}{P_{i-1} (D)} > \delta\)
-
UDALM: Unsupervised Domain Adaptation through Language Modeling (Karouzos et al., NAACL 2021)
This method adapts a general pretrained LM to the target domain distribution in a simple strategy consisting of three steps:
- Pre-training LM on general corpus using MLM objective.
- Continue the pre-trainining on target domain corpus using MLM objective
-
Perform simultaneously/interleavely two supervised fine-tuning task: (i) a supervised task on labelled source domain data (e.g. classification) (ii) MLM task on target domain data. The idea is to avoid the catastrophic forgetting while adapting the general LM to target domain:
\(Loss = \lambda Loss_{classification \; task} + (1-\lambda) Loss_{MLM \; task}\).
During this process, the samples from two tasks are interleaved in a batch and are fed to the BERT encoder. The value of \(\lambda\) is determined by the proportion of samples of the classification task (i) in the batch.
-
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers (Pillutla et al., NeurIPS 2021).
Measuring the “true” closeness between the distribution of text generated by a LM and the “true” distribution of human-written text is computationally intractable. Instead, it is approximated by samples from each distribution.
\(\textsf{MAUVE}\) measurement metric, based on the KL divergences, quantifies two types of errors (as illustrated in the figure below):
- Type I error (False Positive): the model (Q) assigns high probability to texts that are unlikely written by human (P)
- Type II error (False Negative): the model (Q) can not generate texts (assign low probability) that are likely under human-written text distribution (P).
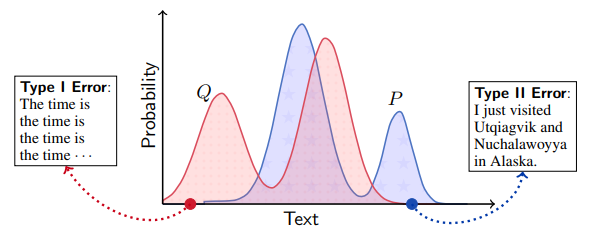
(source: copied from the paper)
Theoretically, the Type I error can be represented by the KL divergence between Q and P: KL(Q | P). A text \(x\) receives large penalty if Q(\(x\)) is large but P(\(x\)) is small. Similarly, the Type II error can be represented by the KL divergence between P and Q: KL(P | Q). A text \(x\) receives large penalty if P(\(x\)) is large but Q(\(x\)) is small. However, these two quantity risk to be infinite if the support of P and Q are not identical which is often the case in practice. To overcome this issue, \(\textsf{MAUVE}\) introduces soft measures for the two errors using the mixture distribution: R\(_{\lambda}\) = \(\lambda\) P + \((1-\lambda)\) Q, \(\lambda = (0..1)\), leading to KL(Q | R\(_{\lambda}\)) as soft Type I error at level \(\lambda\) and KL(P | R\(_{\lambda}\)) as soft Type II error at level \(\lambda\). By varying \(\lambda\), we obtain a divergence curve \(\mathcal{C}\)(P, Q) which amounts to the trade-off between Type I error and Type II error:
\(\mathcal{C}(P, Q) = \{(exp(-cKL(Q \mid R_{\lambda})), exp(-cKL(P \mid R_{\lambda}))): R_{\lambda} = \lambda P + (1-\lambda) Q, \lambda \in (0,1) \}\) where \(c\) is scaling factor.
Likewise the AUROC (area under the receiver operating characteristic) concept in classification problem, \(\textsf{MAUVE}\) metric is the area under the divergence curve.
How to tractably compute \(KL(Q \mid R_{\lambda})\) and \(KL(P \mid R_{\lambda})\)
\(N\) samples \(\{x_i\}_{i=1}^N\) are sampled from LM’s distribution Q and \(M\) samples \(\{x'_i\}_{i=1}^M\) are sampled from human text P. Each sample \(x_i\) is encoded by an external LM, yielding its embedding \(LM(x_i)\). Then, \(M+N\) embeddings are jointly quantized into \(k\) histogram bins using \(k\)-mean clustering algorithm, for example. The two distribution P and Q are merely approximated by multinomial distribution of k constant probabilities \(p_1,..,p_k\) where \(p_k (Q) = \frac{\sum_1^{N} \mathbb{I} (\phi(x_i) = k)}{N}\) and \(p_k (P) = \frac{\sum_1^{M} \mathbb{I} (\phi(x'_i) = k)}{M}\), \(\phi(x_i)\) is the bin assignment of the sample \(x_i\).
Through thorough experimentations, \(\textsf{MAUVE}\) proves to meet expected behavior of a good measure for open-ended text generation:
- Generation length: as the generation length increases, the quality of generated text decreases.
- Model size: larger model has higher generation quality.
- Decoding algorithm: consistent with prevail conclusion: greedy \(\prec\) ancestral \(\prec\) nucleus.
- Embedding scheme and Quantization scheme: robust to different embedding models and quantization algorithms, yielding consistent results.
- High correlation with human evaluation.
-
SimCSE: Simple Contrastive Learning of Sentence Embeddings (Gao et al., EMNLP 2021).
Contrastive learning is employed to learn the sentence embedding with a single encoder in unsupervised manner. They use dropout for the generation of positive samples. Specifically, an input sentence is fed to the LM twice with two different dropout masks that will generate a positive pair of sentence representations for the training.
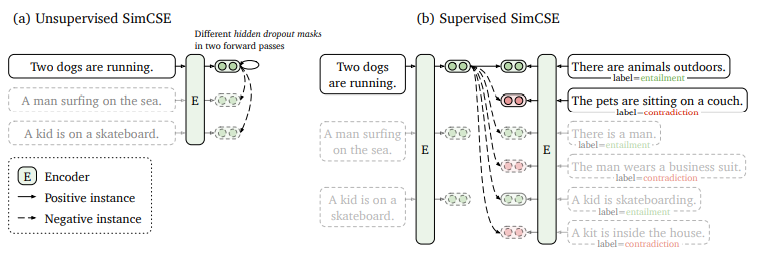
(source: copied from the paper)
Two take-away messages:
- dropout as data augmentation for text. Defaut dropout (0.1) from Transformer works best.
- contrastive learning + dropout helps to evenly distribute learned representations in the embedding space (isotropy or uniformity) and align better embeddings of positive sentence pairs (alignment).
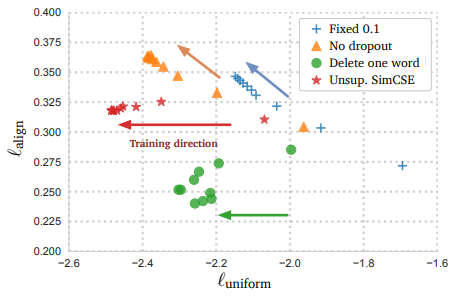
(source: copied from the paper)
-
Surface Form Competition: Why the Highest Probability Answer Isn’t Always Right (Holtzman et al., EMNLP 2021)
The likelihood of a text \(y=y_1, y_2,...,y_n\) (where \(y_i\) is a token in the vocabulary) of length \(n\) given an input text \(x\), is given by a LM:
\[p(y \mid x) = \prod_{i=1}^{n} p(y_i \mid x, y_{i-1}...y_1)\]However, in the context of scoring function, the likelihood \(p(y \mid x)\) is not widely used to compare the text \(y\) with other texts \(y'\) given \(x\). Instead, the length-normalized log-likelihood has been standard for this end.
\[score \; (y \mid x) = \frac{log \; p(y \mid x)}{n} = \frac{\sum_{i=1}^{n} log \; p(y_i \mid x, y_{i-1}...y_1) }{n}\]This paper investigates an very interesting problem of text scoring function used to determine a prediction \(y\) for an input \(x\) with LM: surface form competition . Specifically, given \(x\), there could be many relevant \(y\)(s) that differ from their surface forms but share the same underlying concept in the context of \(x\). For example, if \(x\) is “Which is the richest country in the world”, then \(y\) could be “USA”, “United States”, “U.S.A” or even “U.S of A”. All those answers should receive high score, however, since they come from the same finite probability mass function \(p(y \mid x)\), they compete each other for how much probability they could get. Due to the different level of popularity of each answer \(y\) in the training corpus, the model tends to allocate much more probability mass to popular “United States” or “USA”, which consequently decrease the amount for rare “U.S of A”.
Solution Rather than calculating the ranking score \(score \; (y \mid x)\) via \(p(y \mid x)\) which make solutions \(y\) compete each other, the Pointwise Mutual Information (PMI) is leveraged to evaluate the relevance between the input \(x\) and the output \(y\):
\[score \; (y \mid x) = \text{PMI}(x, y) = log \frac{p(x,y)}{p(x) \times p(y)} = log \frac{p (x \mid y)}{p(x)}\]While \(p (x)\) is constant w.r.t \(y\) and the probability of surface form \(p (y)\) is factored out in \(\text{PMI}(x, y)\), the ranking of a solution \(y\) relies solely on \(p (x \mid y)\) that does not cause the competition between different \(y\).
-
Prefix-Tuning: Optimizing Continuous Prompts for Generation (Li et al., ACL 2021)
Traditional fine-tuning of a LM model for a downstream task involves modifying all the model parameters, consequently, a single set of parameters can just work best for a single task. Inspired by prompting, prefix-tuning freezes the LM parameters and instead prepend to it a sequence of task-specific vectors \(P_{\theta}\) (aka. prefix): \([P_{\theta}; LM_{\phi}]\) that represent the downstream task, we optimize solely the prefix \(P_{\theta}\) using the task’s data to steer the LM to the task.
Prefix-tuning brings some advantages:
- A single LM is reused across different downstream tasks since its parameters are kept intact \(\rightarrow\) efficient storage.
- Only the prefix vector corresponding to the downstream task need to be optimized \(\rightarrow\) lightweight fine-tuning: much fewer parameters w.r.t. LM.
- Prefix-tuning can outperform full fine-tuning in low-data setting and have better generalization.
(source: copied from the paper)
-
The Power of Scale for Parameter-Efficient Prompt Tuning (Lester et al., EMNLP 2021)
Similarly to Prefix-Tuning, prompt-tuning learns task-specific “soft-prompts” (embedding) prepended to task-input (prefix) to steer the LM to perform the task without changing its parameters. While Prefix-Tuning prepends prefix activations to every layers in the encoder, prompt-tuning simplifies this by only adding k tunable tokens per downstream task to the input text at the input layer (without further interventions in intermediate layers) \(\rightarrow\) prompt-tuning has less parameters than Prefix-Tuning.
In addition, prompt-tuning is based on T5 that they found that prompt-tuning with T5 off-the-shelf as the frozen model is inefficient. T5 is pre-trained exclusively on span corruption marked with unique sentinel tokens. As prompt-tuning does not modify the model parameters, it risks to produce unnaturally sentinel tokens in the output. This issue is easily overcomed by full fine-tuning. For this reason, before performing prompt-tuning, they continue to pre-train T5 with LM objective in order for the model to produce natural text output.
Other features of prompt-tuning:
- Performance scales with model size: the larger, the better.
- May improve the roburstness to domain shifts: outperform in-domain fine-tuning on out-of-domain datasets.
- Efficient prompt ensemble: better than single prompt and parameter-efficient as the core LM is freezed and shared.
2020
-
BioMegatron: Larger Biomedical Domain Language Model (Shin et al., EMNLP 2020)
BioMegatron is a Megatron-LM pretrained on PubMed dataset and/or others general corpus for Biomedical domain.
The paper studies the impact of several factors on the performance of both general LM and domain-adapted LM on 3 applications: NER, RE and Q/A in Biomedical domain.
- Domain-specific vocabulary is important for NER and RE task as general-vocabulary breaks domain named-entities into sub-words.
- Q/A: (i) BioMegatron with Bio-vocab finetuned on general SQUAD then on BioASQ results poor results on BioASQ. (ii) larger models tend to perform better.
- Domain Transfer & Generalization: (i) NER: general LLM with general vocabulary if pre-trained sufficiently on domain-specific corpus can be as good as a LM pre-trained only domain corpus only with general vocabulary. (ii) Q/A: large general LM fine-tuned on BioASQ does not mean better performance. (iii) General-domain Q/A: large BioMegatron performs better than small general LM on general-domain Q/A.
-
Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (Gururangan et al., ACL 2020):
Before fine-tuning, continue pre-training a general pretrained language model (PLM) on in-domain unlabeled data (domain-adaptive pretraining DAPT) or task-specific unlabeled data (task-adaptive pretraining TAPT) can improve the performance of downstream tasks.
Some findings from a thorough analysis of domain- and task- adaptive pretraining across 4 domains and 8 downstream task involving both high- and low- resource settings:
- Target domain which is more dissimilar to the source domain benefits more the DAPT. The domain dissimilarity can be quantified by the vocabulary overlap.
- Combined DAPT, then TAPT setting achieves the best performance on all tasks.
- TAPT could be harmful when applied across tasks (i.e. pretrain the LM with unlabeled data of a task, then fine-tune it with data of another task within the same given domain can degrade the performance of later task).
- In low-resource scenario, augmenting the unlabeled data that aligns with the task distribution is beneficial. One data augmentation approach is to employ an external LM to encode task’s data and in-domain corpus into a shared embedding space, then for each sample in the task’s data, \(k\) candidate samples are selected from the in-domain corpus using k-nearest neighbor search.
-
Generalization through Memorization: Nearest Neighbor Language Models (Khandelwal et al., ICLR 2020):
The paper hypothesizes that the representation learning problem may be easier than the prediction problem. For example, two sentences Dickens is the author of and Dickens wrote will essentially have the same distribution over the next word, even if they do not know what that distribution is. Given a sequence of tokens \(x = (w_1,...,w_{t-1})\), \(k\) nearest neighbors \(\mathcal{N}\) of \(x\) is retrieved from a pre-built catalog \(\mathcal{C}\) by comparing the sentence embedding of each sequence in Eclidean space. Each nearest neighbor \(x_i\) of \(x\) has a next token \(y_i\): \((x_i, y_i) \in \mathcal{N}\). The distribution of the next token \(y\) of \(x\) can be estimated via a simple linear regression: \(p_{kNN} (y \mid x) = \sum_{(x_i, y_i) \in \mathcal{N}} softmax (\mathbb{1}_{y=y_i} exp (-d (\textsf{Emb}(x), \textsf{Emb}(x_i))))\).
The LM distribution of a token \(y\) \(p_{LM} (y \mid x)\) given \(x\) is then updated by the nearest neighbor distribution \(p_{kNN} (y \mid x)\): \(p (y \mid x) = \lambda p_{kNN} (y \mid x) + (1-\lambda) p_{LM} (y \mid x)\).
Several advantages of nearest neighbor LM:
- No additional training required.
- Long-tail patterns can be explicitly memorized in the pre-built catalog \(\mathcal{C}\) instead of encoded implicitly in model parameters. New domain can be adapted to LM by creating a new catalog for the target domain dataset.
- \(k\) nearest neighbor search in the embedding space of word sequences can be efficiently done using FAISS index.
2019
-
When does label smoothing help?. (Müller et al., NeurIPS 2019).
Optimizing cross entropy loss with hard targets (i.e. one-hot encoding labels) can make the model predict a training sample too confidently where the logit predicted for true label is very large comparing with ones predicted for other labels, as a consequence, the softmax function will generate probabilities with huge gap (e.g. 0.99 for target label and ~0.0 for other labels). To alleviate this issue, one solution is to increase the temperature T to smooth out soft-max probabilities. Another solution is: instead of training with one-hot encoded label (e.g. [1, 0, 0]), we use soft label (e.g. [0.9, 0.05, 0.05]) by re-weighing labels with a small added value playing as noise. Note: we shoud not distill knowledge from a teacher model which is trained with label smoothing since it cause accuracy degradation.
2016
-
Back Translation Improving Neural Machine Translation Models with Monolingual Data (Sennrich et al., ACL 2016)
Given a text in a known language, we translate it into some other languages and then translate it back to the original language. This will generate synthetic texts that syntactically differ from the input text but have similar semantics. For example, the English sentence “I love watching move” is translated into French: “J’aime regarder un film” then mapped back to English: “I like to watch a movie”.