Recap of The Very Large Database (VLDB) Conference 2023
 (photo taken from Capilano Regional Park, North Vancouver, a highly recommended destination for nature lover)
(photo taken from Capilano Regional Park, North Vancouver, a highly recommended destination for nature lover)
Last week, I had the opportunity to attend in-person The Very Large Data Base (VLDB) conference, held in Vancouver, Canada, from 28 August to 1 September. This year, the conference brought together over 1000 researchers, practitioners from the Database and NLP communities. With the rapid adoption of Large Language Model (LLM) in multiple fields, discussions on LLM, applications and impacts of LLM on data management drew a substantial audience. This post is a recap of presentation/discussion sessions that I was able to attend, focusing on topics that align with my research interests.
Table of Contents
- VLDB by numbers
- NLP community meets Database community
- Database Community in the era of LLM
- Tabular Data (table) is gaining attention
VLDB by numbers
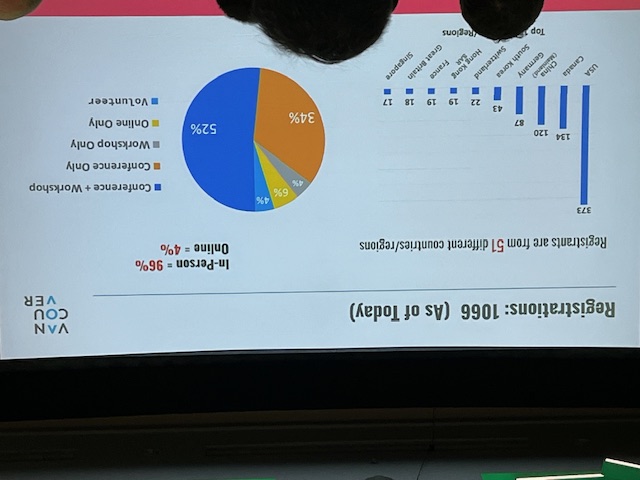

- 1066 attendees, half of them are from USA/Canada.
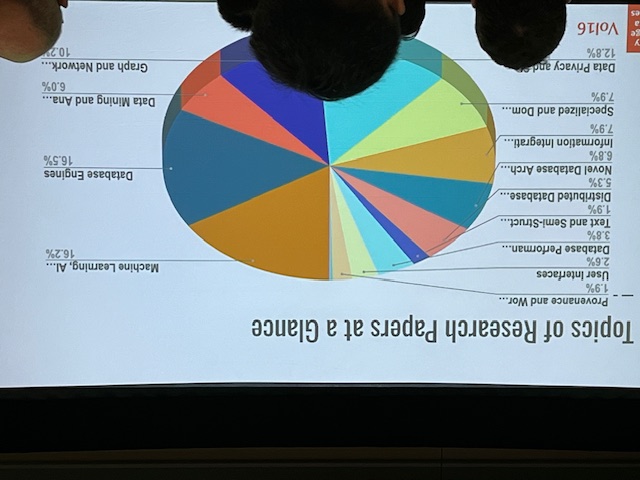
- 1074 papers submitted to the main research track. 266 accepted paper.
- 16.2% of papers are on Machine Learning, AI. (one of two hottest topics, together with Database Engines)
- 3 keynotes, one from a NLP rockstar Yejin Choi from AI2 (personally, I refresh her scholar profile once per month and read many of her papers).
- 15 workshops, one focused on LLM + Database, one focused on Tabular data.
- Google, Microsoft, Amazon, Salesforce, Huawei, etc have stands at the conference, to showcase their products as well as present job opportunities.
NLP community meets Database community
Common Sense: the Dark Matter of Language and Intelligence - Yejin Choi’s keynote.
She gave an insightful talk on the subject: LLMs (e.g. ChatGPT, GPT4) are incredibly powerful, yet surprisingly brittle, makes nonsensical errors or inconsistent answers (e.g. question + negated question get the same answer). She argues this is due to the lack of common sense knowledge (examples of common sense: bird can fly or it’s not ok to keep the fridge door open). While scale people believes this issue could be (easily) fixed when model gets bigger and bigger and consumes more similar training data, she questions why we even need to take that approach when children can naturally acquire such common sense knowledge without reading trillion words. During the keynote, she presented methods/algorithms (as described below) that help build smaller but competitive models, powered with knowledge (“knowledge model”), compared to extreme-scale language models:
-
Symbolic Knowledge Distillation: manually crafting a high-quality common sense knowledge graph to teach a common sense model is expensive, hard to scale, hence, resulting a knowledge repository with limited coverage. Based on the intuition that a LLM (e.g. GPT-3) contains a vast amount of knowledge, but may be noisy and not fully exploitable, West et al propose to distill high-quality commonsense knowledge from this LLM (referred to as the teacher model) through prompting (e.g. “X goes jogging. Prerequisites: For this to happen,__”) and filtering the prompt’s results by a small critic model. The critic model is fine-tuned on a set of correct vs. incorrect human judgements on a randomly sampled set of knowledge extracted (but unfiltered) from GPT-3. As a result, for the first time, they obtain ATOMIC, a commonsense KG, automatically distilled from GPT-3, outperforms human-curated KG in three criteria: quantity, quality and diversity.
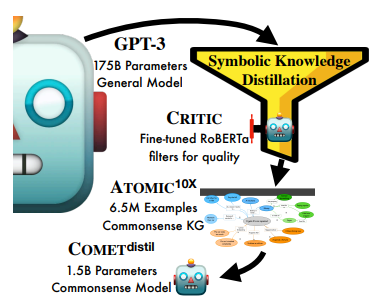 (source: copied from the paper).
(source: copied from the paper).Subsequently, the distilled commensense KG is employed to train a much smaller model (GPT-2 XL), resulting a knowledge model, COMET_DISTIL, surpassing the commonsense of GPT-3.
-
Inference-time algorithms: enhancing the common sense capability of LM at inference-time by improving prompting technique or decoding technique, requiring no further fine-tuning.
-
Constrained NeuroLogic decoding: while common sense statements are simple, clear and short, text generated by small LM can be often trivially long or repetitive. To improve the generation quality, NeuroLogic Decoding enforces logical constraints at decoding time (e.g. limiting number of function words such as “in”, “on”, or excluding connective words such as “although”, “since”, or a given word must be generated).
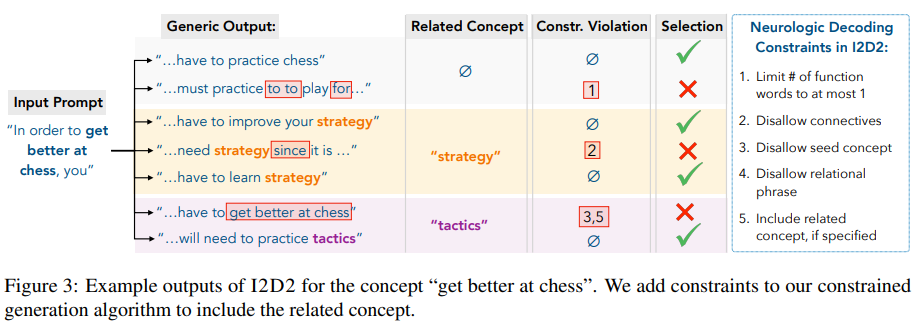 (source: copied from the paper).
(source: copied from the paper). -
Maieutic Prompting: LLM can generate inconsistent and unreliable explanation when a question and its negated version get the same answer (e.g. “One is a number that comes before zero ? … True” vs. “One is a number that comes after zero ? … True”). They introduce a novel prompting technique, Maieutic Prompting to improve the consistency in LLM’s generation. Inspired by Socratic style of conversation, the inference process exploits the depth of reasoning by asking recursively if a newly generated explanation is logically consistent with its parent (previous) explanation, as illustrated in the figure below:
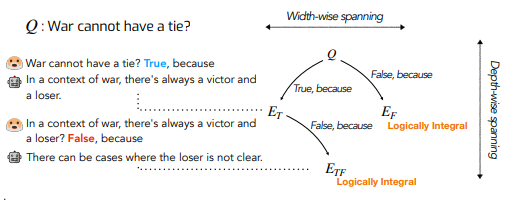 (source: copied from the paper).
(source: copied from the paper).
-
Language Model Agents for Building Natural Language Interfaces to Data - Tao Yu’s keynote, XLANG NLP Lab, University of Hong Kong, in Databases and Large Language Models (LLMDB) workshop.
Teaching LLM to use tools (Tools-Augmented LLM) is probably one of the most exciting capabilities of LLM, enabling it to interact with the real world and address some of limitations:
- Math capabilities (by calling a calculator).
- Keep LLM up-to-date with the latest information of real world (by coupling with a search engine).
-
Enhance Interoperability and Trustworthiness (by tracing tool’s operations, or citing sources).
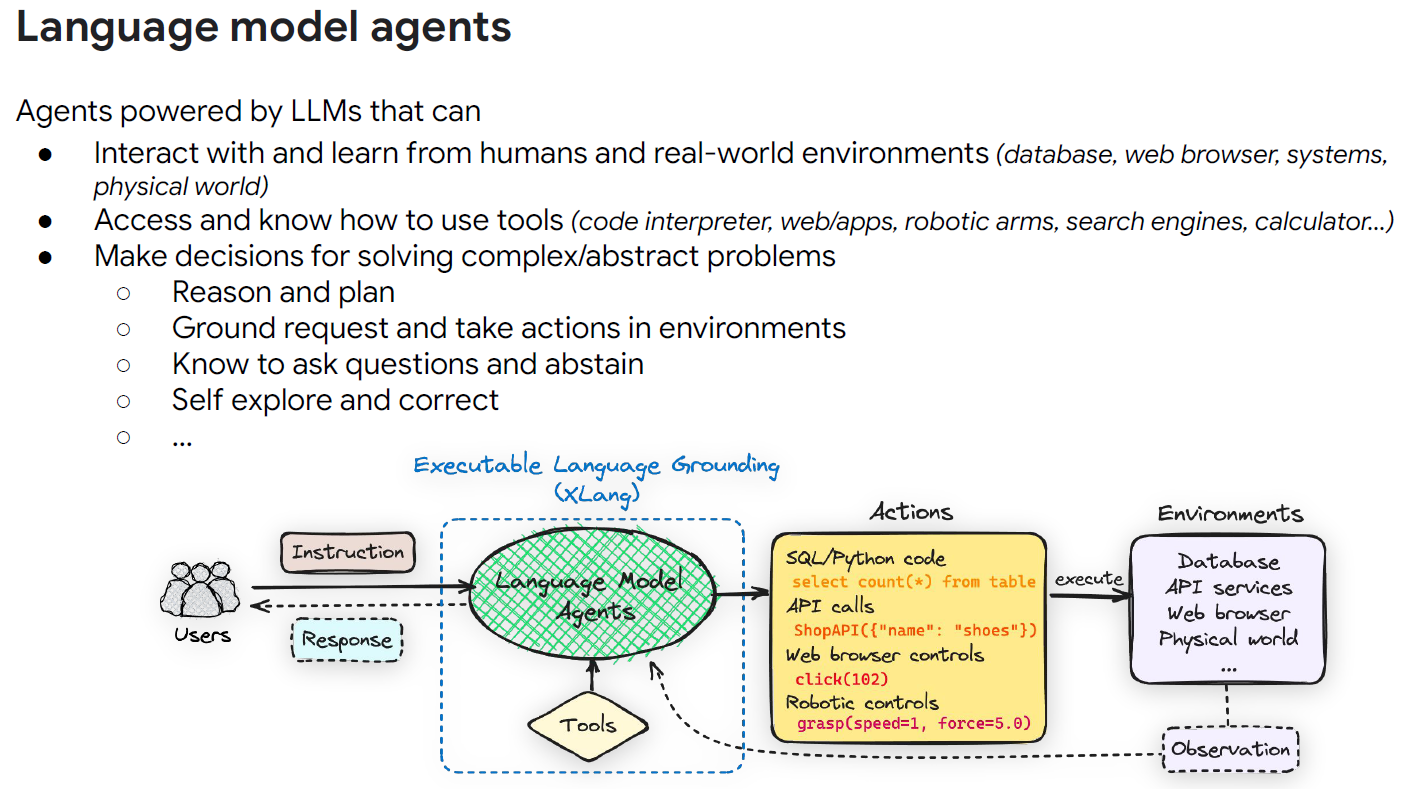 (source: copied from author’s slides).
(source: copied from author’s slides).
XLANG Lab is building such LM Agent, supporting a wide range of data-related tools (Python, SQL, Plot tools, Kaggle tools…). Additionally, as tools involve both text and code, they introduces Lemur-70B, built on top of LLaMa-2, balancing text and code capabilities.
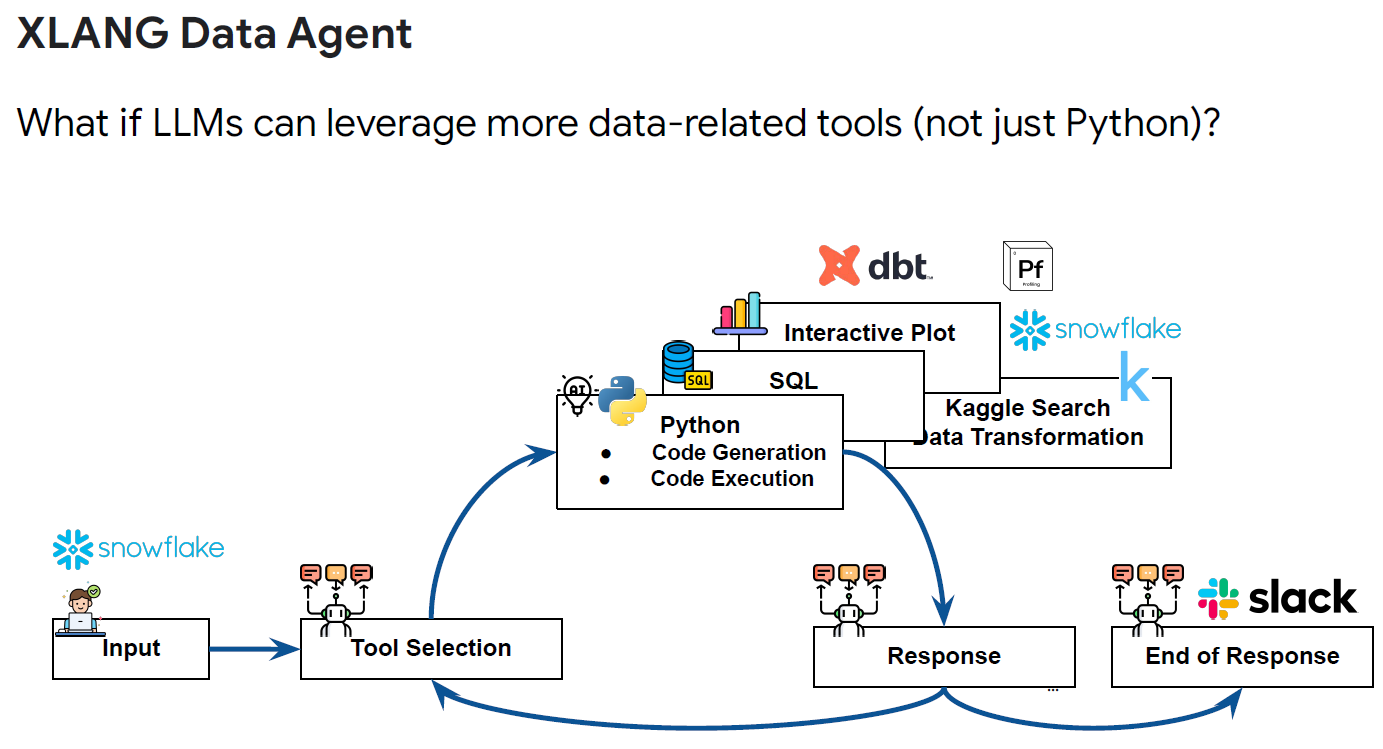
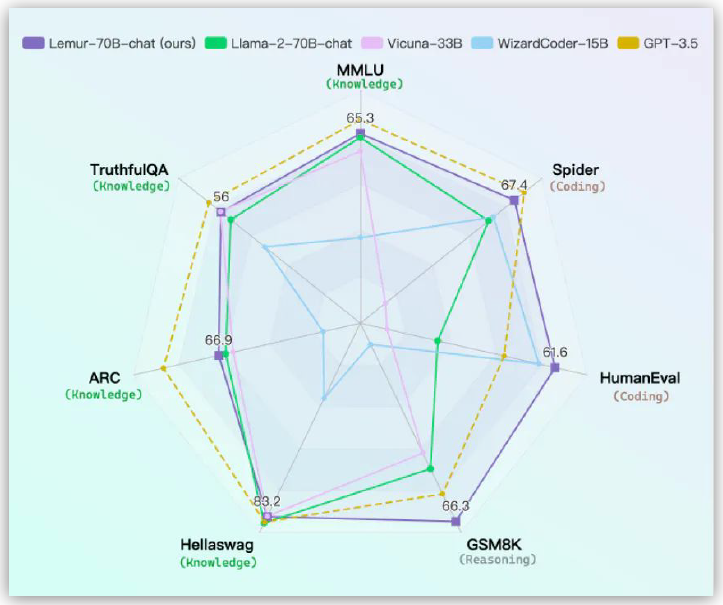 (source: copied from author’s slides).
(source: copied from author’s slides).
Database Community in the era of LLM
Panel: Will LLMs reshape, supercharge, or kill data science ?
The panel, moderated by Alon Halevey (Meta), featured Yejin Choi (University of Washington and AI2), Avrilia Floratou (Microsoft), Michael Franklin (University of Chicago), Natasha Noy (Google) and Haixun Wang (Instacart).
To kick off the discussion, Alon Halevey showcased two examples that GPT-4 performs very well:
- He asks GPT-4 to read an uploaded .csv file containing the books that he has ever read and perform several tasks such as: count number of books, deduplicate entries, plot a histogram. He then asks if GPT-4 can suggest some creative new tasks based on that .csv file. GPT-4 did well (although I don’t recall the details)
- He extracted posts from his friend on facebook over a span of 2 months. He asks GPT-4 to summarize these posts in a structured way by defining a schema and generating attribute values. The results provided by GPT-4 were awesome.
Given the fact that LLMs has been significantly advancing several long-standing challenges that the database community has ben tackling for decades, Alon asks the panel following questions:
 (from Halevy)
(from Halevy)  (from Floratou)
(from Floratou)
Several thoughts from the panel list:
- Writing manually SQL stuffs will go way.
- LLM changes remarkably the search engine (understand the intent and give good answer). Past trends go from unstructured data to structured data via ETL, Wrangling. Present trends: structured data –> un-structured data with LLM.
- LLM has issue with latency, data freshness.
- LLM has no exact durable memory, while database does.
- Replacing .csv, .yaml by .txt is challenging.
- Add whole database on-the-fly is expensive –> Tools-Augmented LLMs.
The first edition of Databases and Large Language Models workshop
This workshop has emerged to meet the “urgent and exiting” need of integrating the impressive capabilities of LLMs into the real-world data management applications.
-
Wang-Chiew Tan (Meta)’s keynote: Using LLMs to Query Unstructured and Structured Data (similar to Alon Halevey (Meta)’s keynote at Tabular Data Analysis Workshop)
Personal data records valuable information (e.g. health, activities, hobby, etc) throughout one’s life.

(source: copied from the slides).
This talk presents interesting opportunities of leveraging LLMs to interact with our personal timeline data (whether structured or not), thereby providing new user experience. As LLMs know nothing about us, there are two ways to query timeline data in natural language using LLMs:
-
Retrieval Augmented LM (RAG) (Figure a): LM consults an external repository that stores personal data to answer the question. The speaker argues that this scheme does not work well on complex/multi-hop questions.
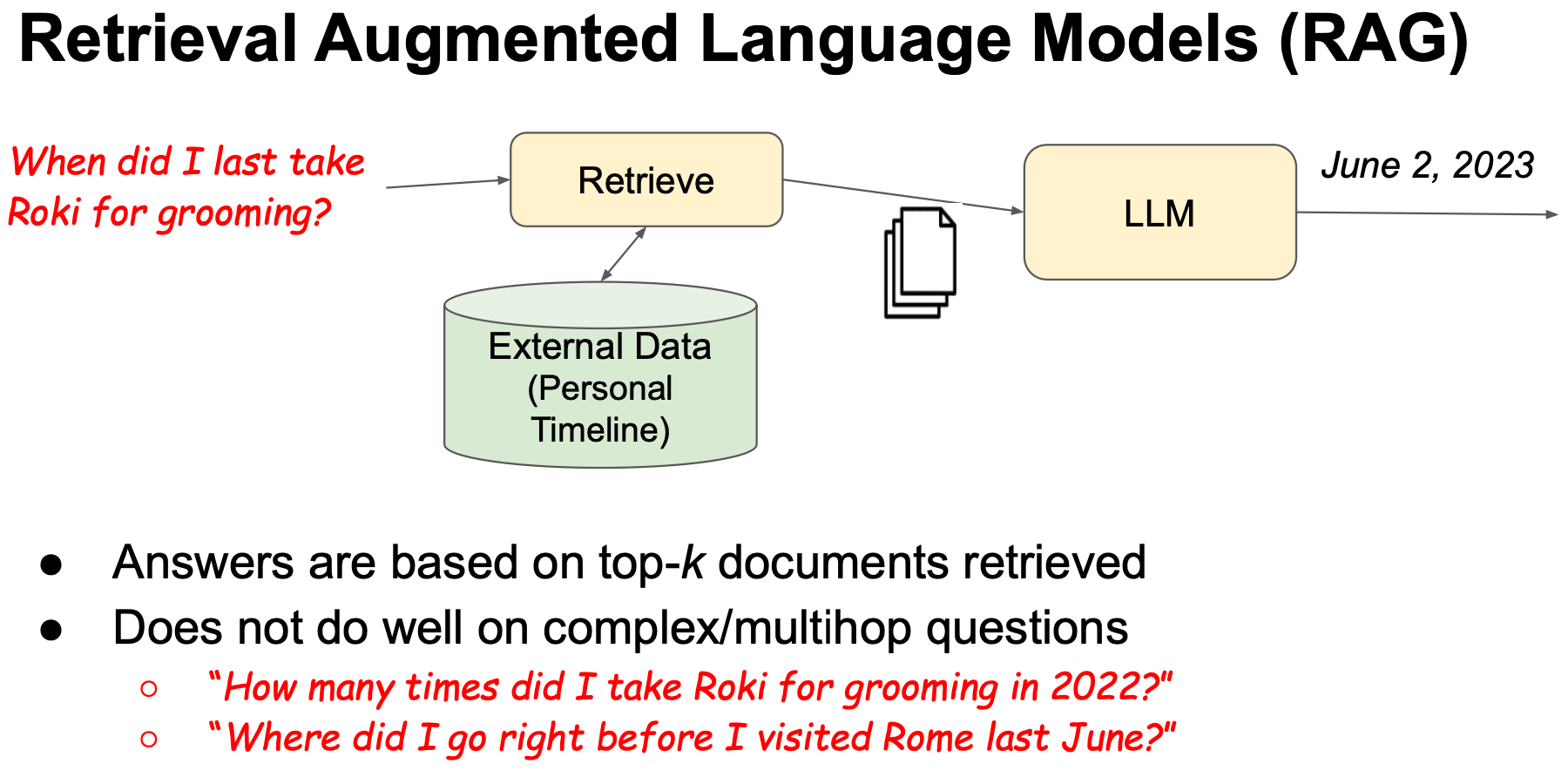 (source: copied from the slides).
(source: copied from the slides). -
Tool Augmented LM (Figure b): LM converts the question into SQL and call a SQl-engine to execute the SQL over database of personal data.
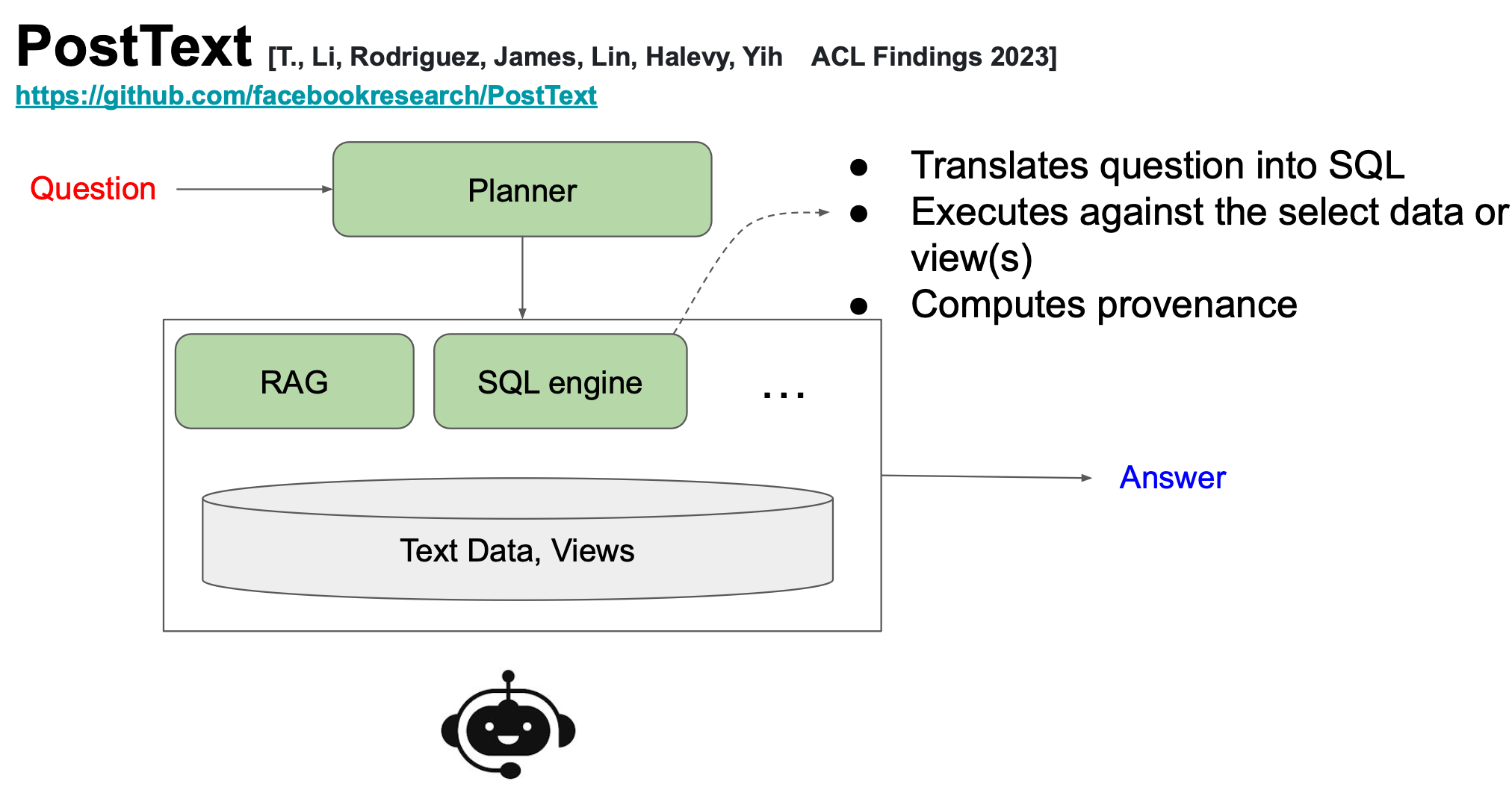
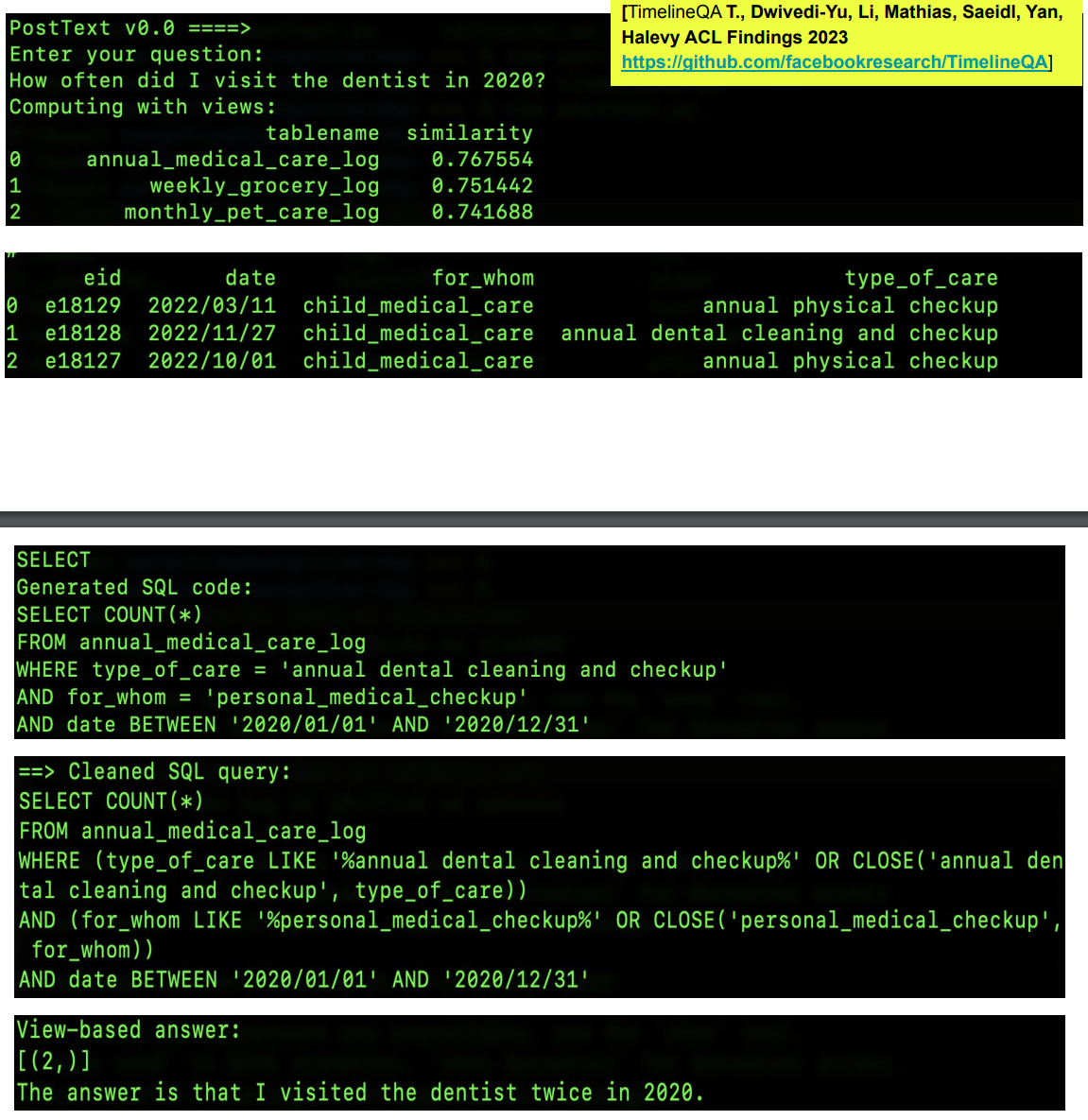 (source: copied from the slides).
(source: copied from the slides).
-
-
Laurel Orr (Numbers Station)’s keynote: Deploying LLMs on Structured Data Tasks: Lessons from the Trenches
She talked about her experiences when it comes to deploying LLMs applications for Structured data Wrangling in production, at Numbers Station.
 (source: copied from the slides).
(source: copied from the slides).In a nutshell, she frames “LLMs for Data Wrangling in Production” as: “Possible, Exciting, Not Easy”, illustrated by three challenges:
- (a) - High Cost: real relational database is huge, put it all in the context is tricky. Solution: Tools-augmented LLMs use tools to interact with database.
- (b) - Lacking Personalization: General LLMs lack required enterprise knowledge. Solution: fine-tune LLMs with enterprise data.
-
(c) - Not enough context.
(a)
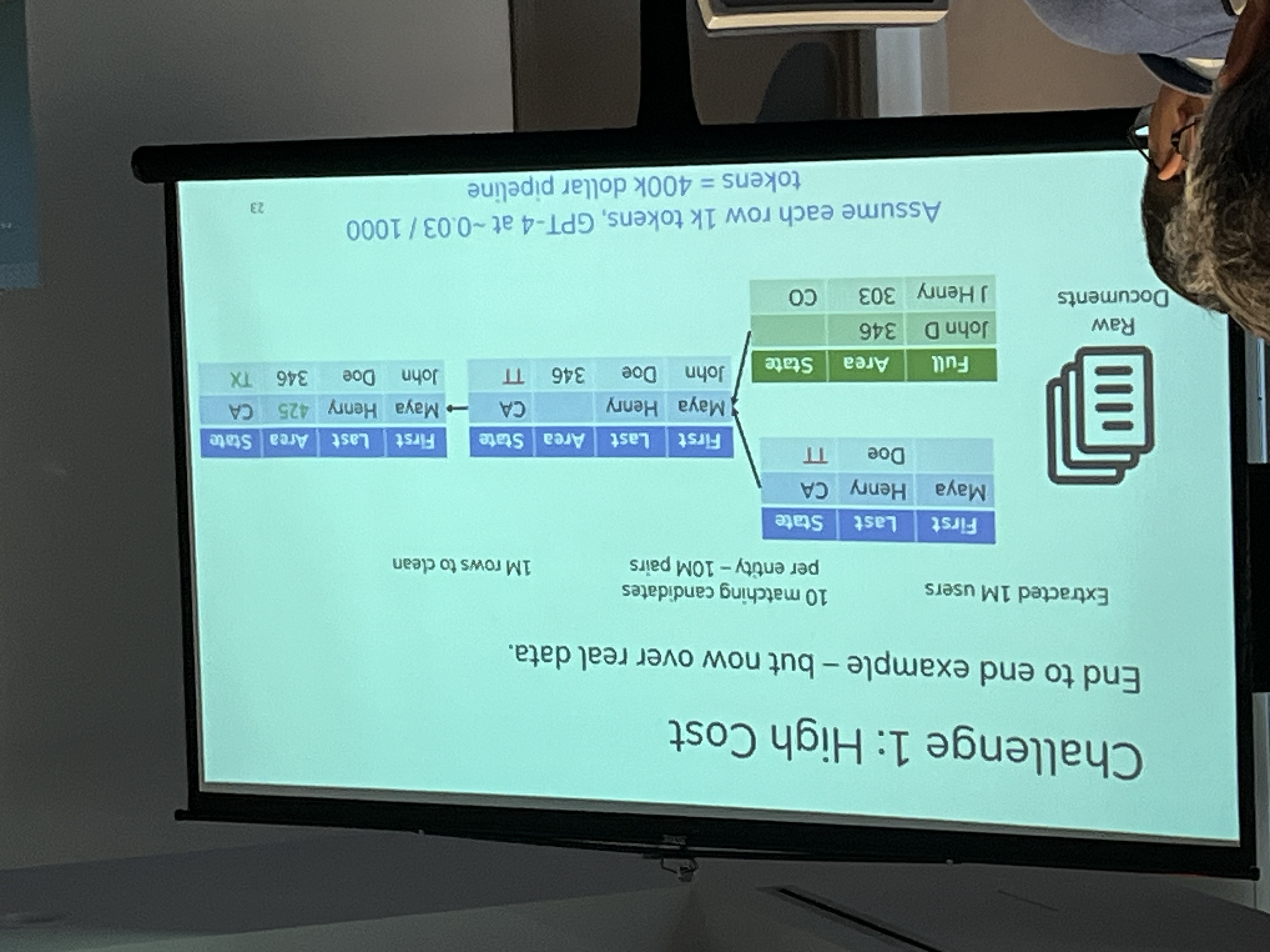 (b)
(b)  (c)
(c) 
(source: copied from the slides).
Knowledge Graph in the era of LLM
Xin Luna Dong (Meta) was awarded the 2023 VLDB Women in Database Research Award for her significant contributions to knowledge graph construction and data integration. You can refer to her vision on the next generations of KG, leveraging the recent big success of LLMs.
Several paper sessions
-
How Large Language Models Will Disrupt Data Management (University of Chicago):
 (source: copied from the slides).
(source: copied from the slides). - Can Foundation Models Wrangle Your Data? (Stanford): LLMs show strong zero-shot and few-shot capability in data wrangling tasks such as entity matching, error detection and data imputation. A benchmark for this topic will soon be integrated into the famous LLM HELM benchmark.
- CatSQL: Towards Real World Natural Language to SQL Applications (Alibaba Group): new state-of-the-art natural language to SQL converter on Spider benchmark.
Tabular Data (table) is gaining attention
-
Together with Table Representation Learning Workshop, co-located with Neurips 2023 and Semantic Web Challenge on Tabular data to Knowledge KG Matching, co-located with ISWC 2023, this year’s VLDB conference organized Tabular Data Analysis Workshop. The workshop featured two keynote speakers: (i) Renée Miller (Northeastern University) on Table Discovery and Integration from Data Lake of tables and (ii) Alon Halevey (Meta) on the potential of LLM of interfacing a database with natural language query.
- As part of Renée Miller’s keynote, she presented two papers accepted at VLDB:
- Semantics-aware Dataset Discovery from Data Lakes with Contextualized Column-based Representation Learning: table union search involves searching for tables in a data lake that are semantically close to a given table by evaluating the similarity between column embeddings in two tables. They employ the popular contrastive self-supervised training to learn the embeddings of table columns. The key point lies in data augmentation for the training: given a input table \(x\), applying transformation operators \(f\) such as cell dropping, cell swapping, row shuffling to \(x\) yields a positive training sample (\(x\), \(f(x)\)).
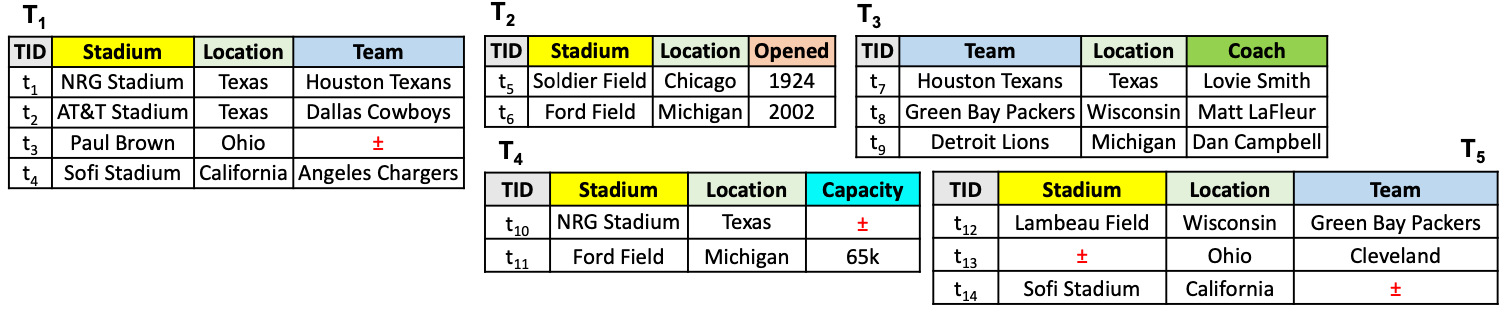
(source: copied from the paper).
- Integrating Data Lake Tables: presents different techniques for integrating relevant tables discovered from data lake into a single table.
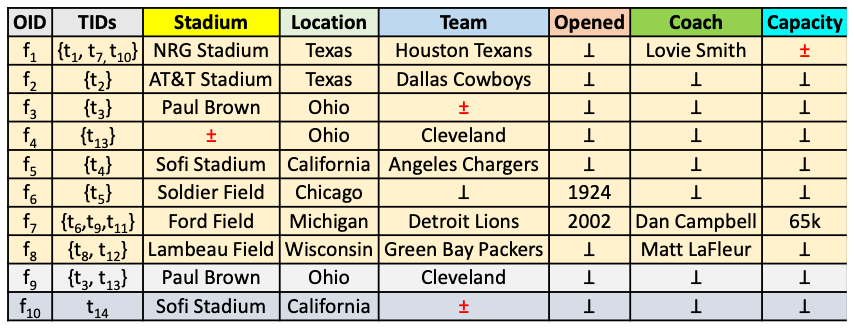
(source: copied from the paper).
Her talks attracted a lot of discussion among researchers in the Semantic Web community. They agreed that adding a semantic layer on top of table (via Semantic Table Interpretation) would facilitate and improve the discovery and integration of data lake tables. Several related papers have been presented during the conference:
- RECA: Related Tables Enhanced Column Semantic Type Annotation Framework (The University of Hong Kong).
- Column Type Annotation using ChatGPT (University of Mannheim).
- Towards Generative Semantic Table Interpretation (Orange + EURECOM).
-
VLDB Best paper award: Auto-Tables: Synthesizing Multi-Step Transformations to Relationalize Tables without Using Examples (Georgia Tech & Microsoft):
Non-relational tables, despite of being overwhelming on the wild web, are not easy to be queried using SQL-based tools. Transforming non-relational tables into standard relational table (Figure b) is a non-trivial task and has been a longstanding challenge in the database community (Figure a).
(a)
 (b)
(b) 
(source: copied from the paper).
This work proposes Auto-Tables, a pipeline for transforming non-relational tables into standard relational table automatically. The process involves the use table transformation operators such as transpose, stacking, splitting, etc to generate a self-supervised training dataset which will be used to train a deep neural network.