Table Representation Learning with Transformer
Tabular data (aka. table) is one of the most prevalent data structures used to store and present information on the web or in industry. Table contains rich and meaningful structural and semantc information. Making table machine-understandable is necessary to facilitate a wide range of applications related to table such as table-based question answering (an example shown below), fact-checking, table indexing/search/retrieval or table content imputation.

(source: TAPAS (ACL 2020)).
The emergence of Transformer-based Large Language Models (LLM) has revolutionized various natural language understanding tasks. As the massive corpora used to pre-train LLMs contains most of free-form text, or programming code, many works investigate and extents the applicability of LLMs to structured data like table. This post gathers prominent transformer models for learning the neural representation of tabular data.
A survey on this emerging topic can be found at Transformers for Tabular Data Representation: A Survey of Models and Applications, TACL 2022.
Table of Contents
- Large Language Models are Versatile Decomposers: Decomposing Evidence and Questions for Table-based Reasoning (Ye, SIGIR 2023)
- Large Language Models are few(1)-shot Table Reasoners (Chen, Findings of EACL 2023)
- TABLEFORMER: Robust Transformer Modeling for Table-Text Encoding (Yang, ACL 2022)
- REASTAP: Injecting Table Reasoning Skills During Pre-training via Synthetic Reasoning Examples (Zhao, EMNLP 2022)
- TAPEX: Table Pre-training via Learning a Neural SQL Executor (Liu, ICLR 2022)
- TABBIE: Pretrained Representations of Tabular Data (Lida, NAACL 2021)
- GRAPPA: Grammar-Augmented Pre-Training For Table Semantic Parsing (Yu, ICLR 2021)
- TABERT: Pretraining for Joint Understanding of Textual and Tabular Data (Yin, ACL 2020)
- TAPAS: Weakly Supervised Table Parsing via Pre-training (Herzig, ACL 2020)
- TURL: Table Understanding through Representation Learning (Deng, VLDB 2020)
Large Language Models are Versatile Decomposers: Decomposing Evidence and Questions for Table-based Reasoning (Ye, SIGIR 2023)
DATER employs LLM to tackle table-related tasks with in-context learning in two steps:
- Evidence decomposition (sub-table extraction): use prompts to ask LLM to extract a small part in the table (set of rows/columns) that is relevant to the question.
- Question decomposition: decompose the input question into sub-questions in chain-of-though style. First, mask numerical values in question, next convert into SQL queries. The SQL queries are then executed using any SQL engine, the output will be backfilled into placeholders of mask tokens, yeilding sub-questions for the initial question.
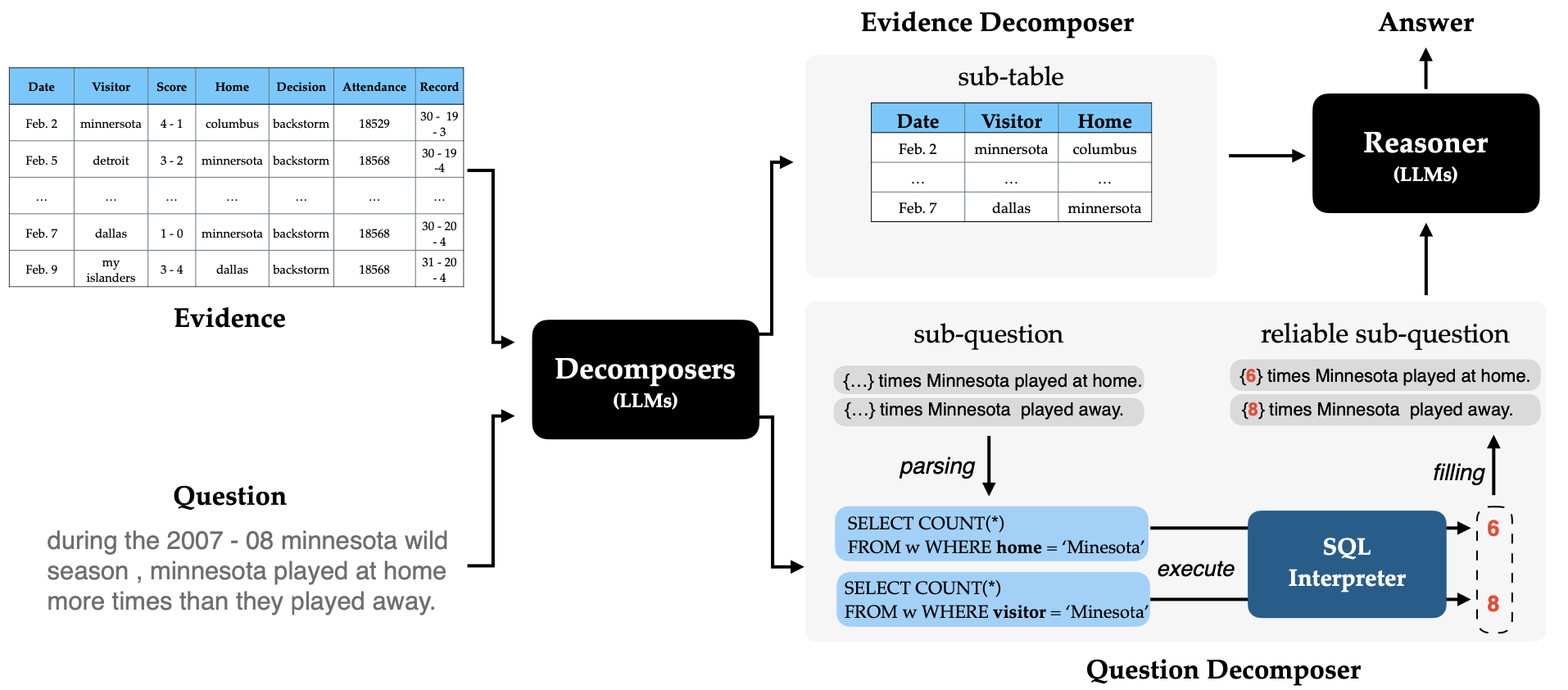
(source: copied from the paper).
Large Language Models are few(1)-shot Table Reasoners (Chen, Findings of EACL 2023)
Although not explicitly pre-trained to encode tabular data, LLM may have seen many tables in the pre-training corpus. The paper demonstrates that LLM (i.e. GPT-3) has strong 1-shot performance (comparable to smaller fine-tuned models) on several table-related tasks (i.e. table-based QA, table-based fact checking).
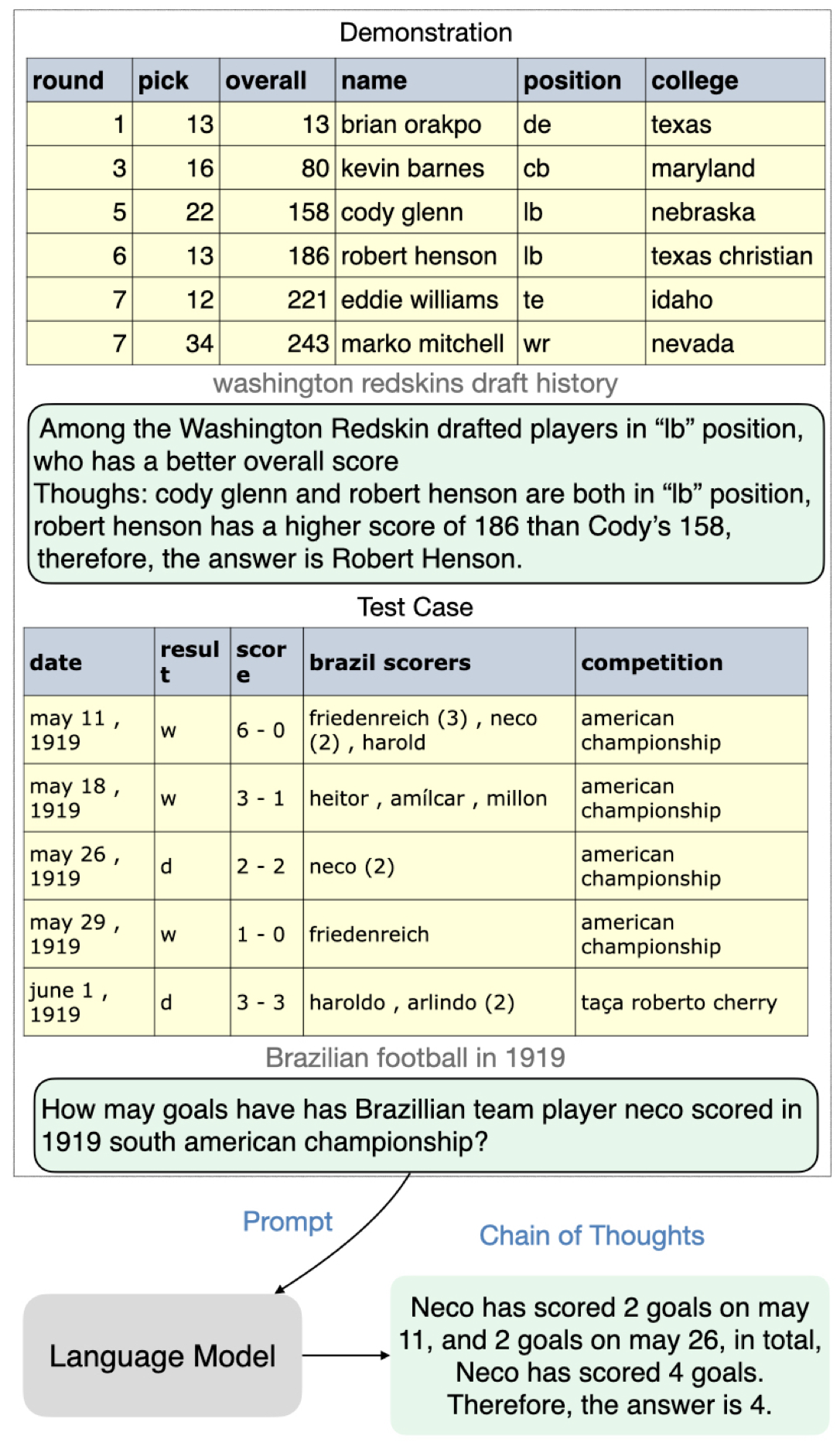
(source: copied from the paper).
TABLEFORMER: Robust Transformer Modeling for Table-Text Encoding (Yang, ACL 2022)
Many previous LMs for table representation learning encodes row/column indices via sentinel tokens appended to the linearized input. This causes unwanted attention bias. For example, the model may favor the last row to make prediction as it observed frequently the spurious correlation between the last row and the label during the pretraining. Consequently, when the table rows are shuffled, models make wrong prediction although this operation does not change the overall semantics of the table. TableFormer alleviates this issue by removing absolute row_id and column_id embeddings, instead, it relies on relative positional embeddings to model intra/inter-cell, header-cell, utterance-cell interaction in text-table pairs such as: whether two cells are in same row, or in same column, whether a header and a cell are in same column, etc.
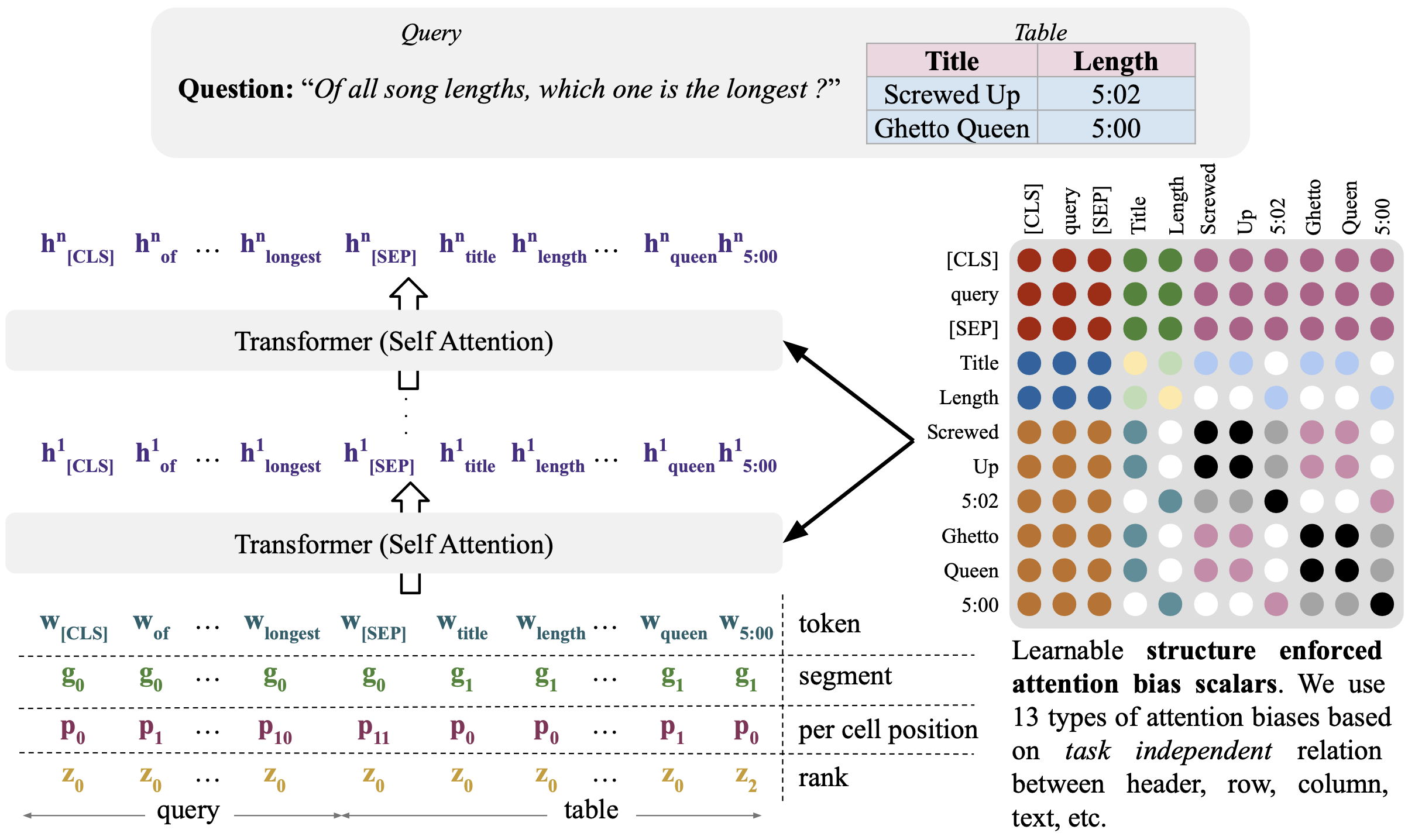
(source: copied from the paper).
REASTAP: Injecting Table Reasoning Skills During Pre-training via Synthetic Reasoning Examples (Zhao, EMNLP 2022)
Similar to TAPEX, REASTAP demonstrates that LM can perform reasoning skills over tables without the need of a complex table-specific architecture design (e.g. no need to add a bunch of sentinel tokens to identify table’s components, or modify the original attention mechanism). To this end, REASTAP pre-trains an autoregressive model (i.e. BART) on 7 basic table pre-train tasks. All the tasks are framed flexibly as text-2-text problems. For each task, several templates are predefined and used to genetate synthetic training samples:
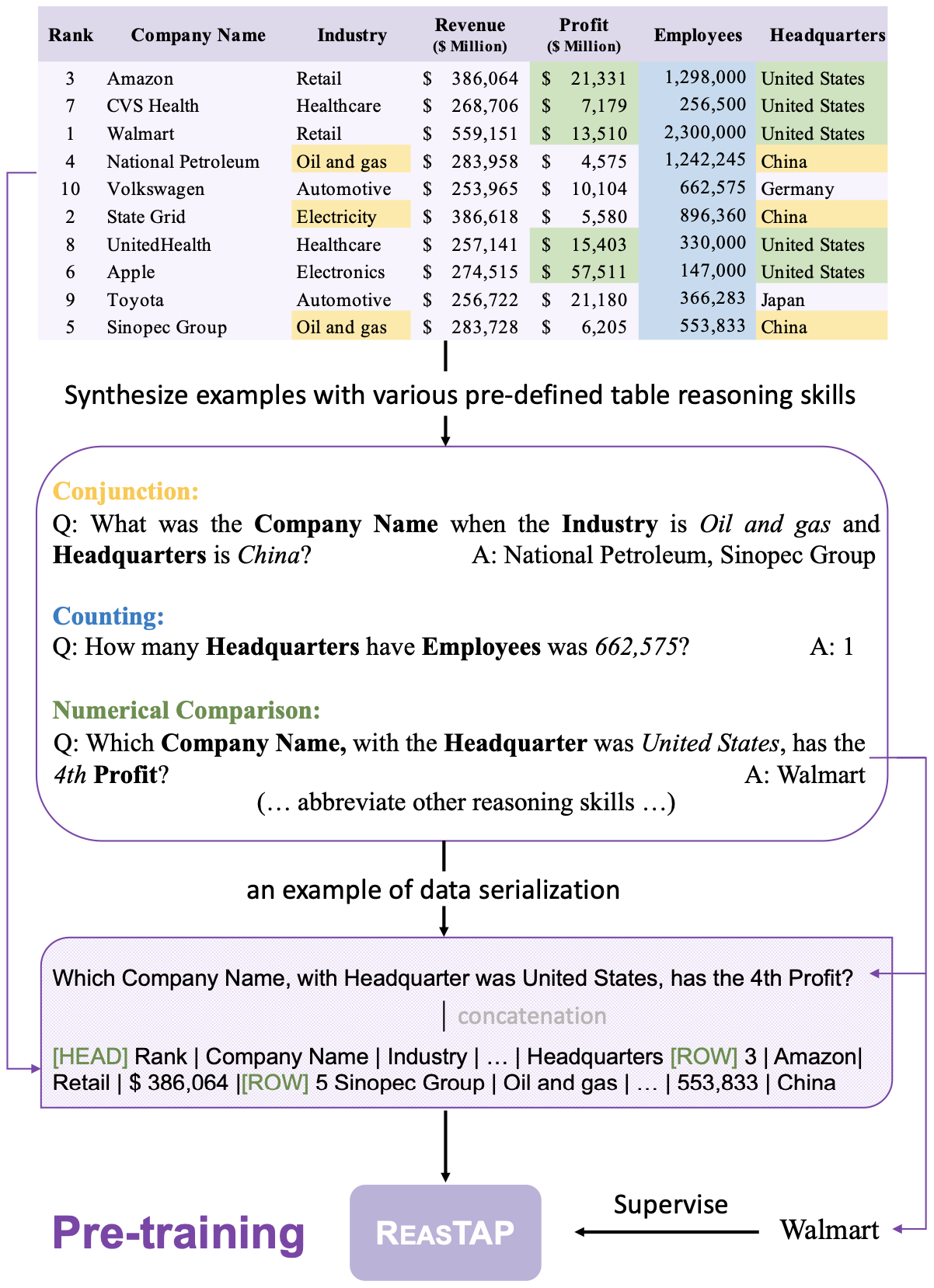
(source: copied from the paper).
TAPEX: Table Pre-training via Learning a Neural SQL Executor (Liu, ICLR 2022)
The intuition of TAPEX is that if a LM can perform reasoning over a table via SQL queries, then it should have deep understanding of the table. To this end, TAPEX continue to pre-train a encoder-decoder LM (i.e. BART) on synthetic SQL-table queries with controlled quality/diversity, following the prevalent text-to-text framework:
- input: linearized SQL queries + linearized table (\([HEAD], header_1,...,header_N, [ROW], 1, cell_{11},..., cell_{1N}\))
- output: answer for the input query.
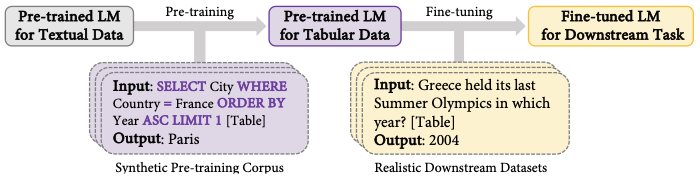
(source: copied from the paper).
With the versatile encoder-decoder architecture, TAPEX is easily fine-tuned to adapt to numerous downstream tasks by framing the tasks as text-to-text problems.
TABBIE: Pretrained Representations of Tabular Data (Lida, NAACL 2021)
TABBIE hypothizes that if a LM can detect a corrupted cell text, it may have the capacity to understand table structure: row/column seperators or cell boundaries. Without assuming the existence of other information than the table itself, TABBIE corrupts several cells in the table and train the LM to classifier whether every cell has been corrupted or not (similar to ELECTRA’s discriminator). TABBIE employs two seperate Transformer to encode rows (row transformer) and columns (column transformer). The representation of cell \(c_{i,j}\) is an average of the row \(i\) embedding and column \(j\) embedding. The cell embedding is initialized by the embedding of the cell text produced by a freezed BERT, added to two learnable positional embeddings (row and column).
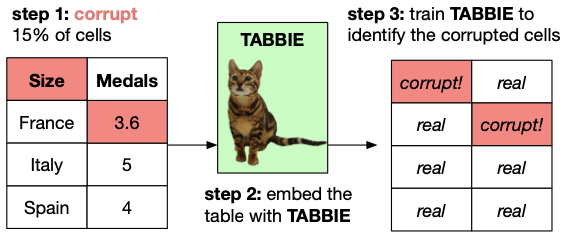
(source: copied from the paper).
GRAPPA: Grammar-Augmented Pre-Training For Table Semantic Parsing (Yu, ICLR 2021)
GRAPPA induces context-free templates from annotated text-to SQL examples, such as \(\textsf{Show the COLUMN0 that have the OPO VALUE0 TABLE0, SELECT COLUMN0 FROM TABLE0 GROUPBY... OPO \in \{>, <, >=\}}\), then uses such templates to genetate synthetic SQL query from table lake, such as \(\textsf{Show the studient_id have more than 6 class SELECT student_id...}\). This synthetic query is concatenated with the headers of correponding table, used to pretrain a RoBERTa with SQL semantic loss: predict whether a column appears in the SQL query and involves what operations. Additional, GRAPPA also pre-trains the model on joint text-table datasets with MLM loss.
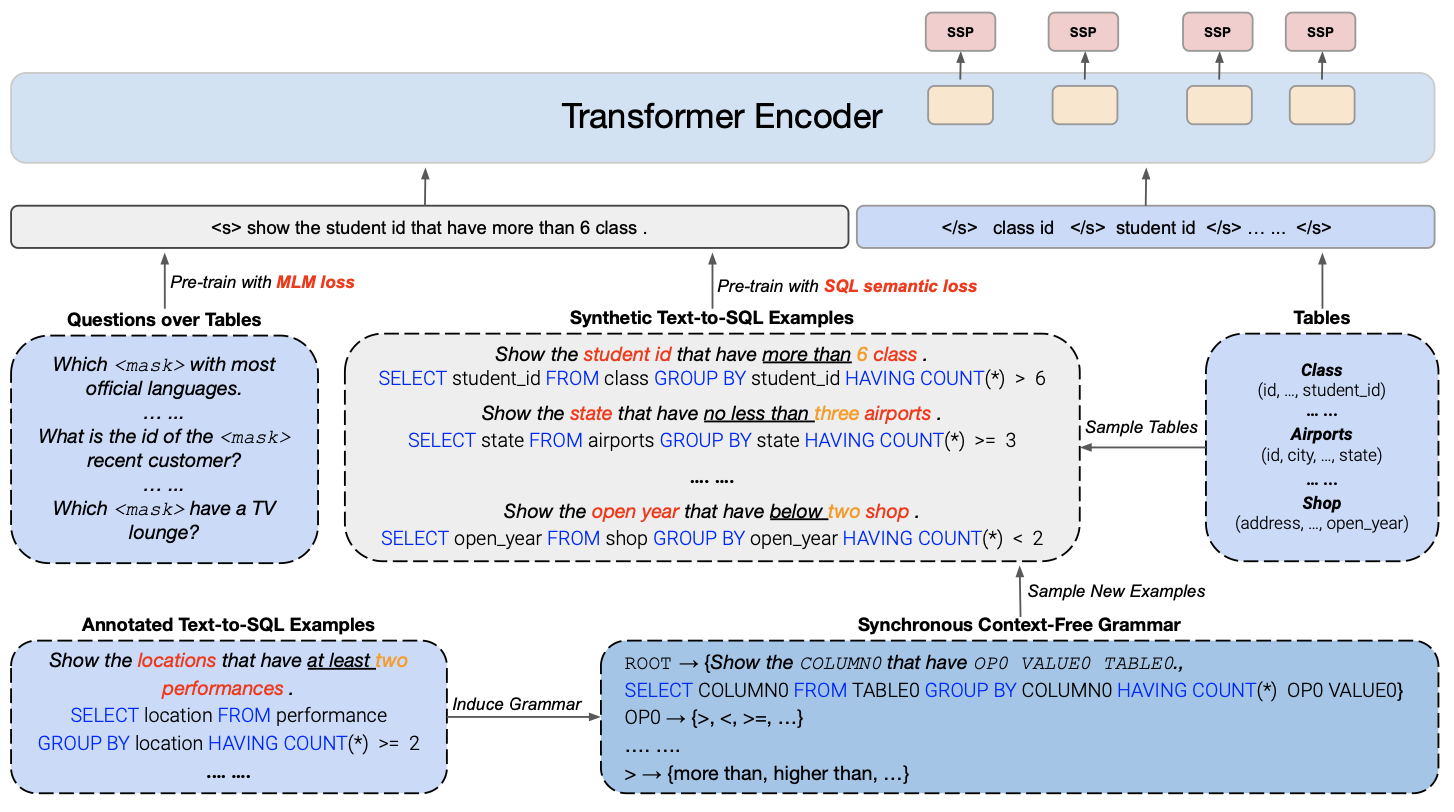
(source: copied from the paper).
TABERT: Pretraining for Joint Understanding of Textual and Tabular Data (Yin, ACL 2020)
TABERT creates a dataset including tables and surrounding text from Wikipedia pages, then jointly pre-train a LM on this mix of free-from text and structured tabular data. Due to limited input length, the table is cut off, only keep rows that are most relevant to the surrounding text (aka. utterance). Each table row is linearized (i.e. a cell is reprensented by \(Column\_Name \; \vert \; Column\_Type \; \vert \; Cell\_Value\)) and concatenated with the utterance, then is fed into BERT to yeild row-level embeddings of cell tokens and utterance tokens. Cell embeddings in the same column are aligned by vertical self-attention layers to allow for information flow across cell representations of different rows. The column representation is the average of embeddings of belonging cells.
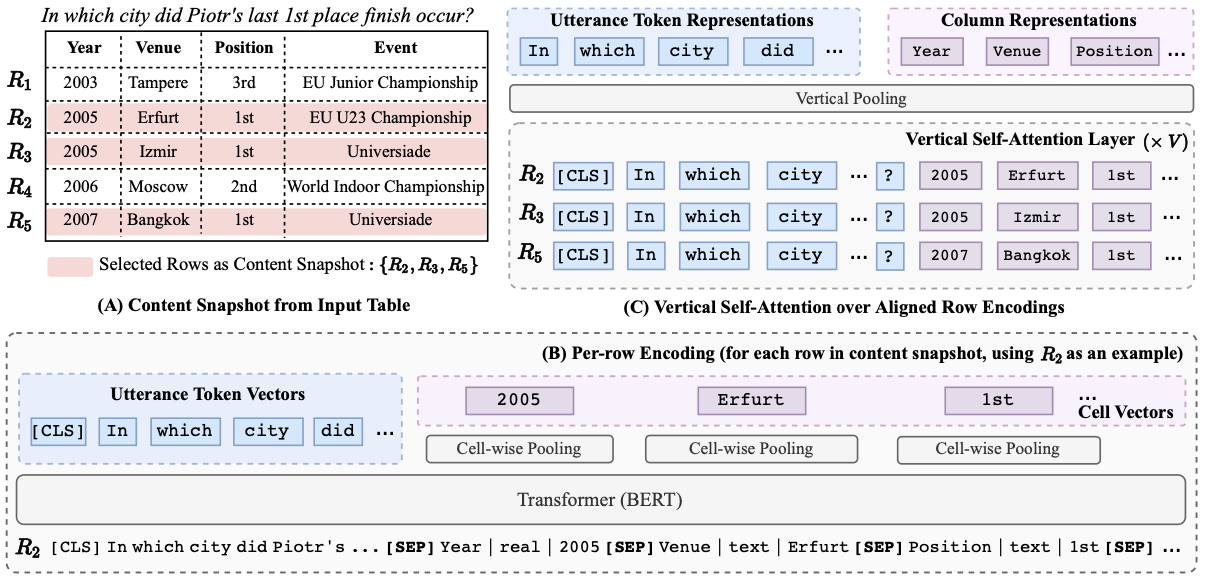
(source: copied from the paper).
TABERT employs two unsupervised learning objectives:
- Masked Column Prediction: mask and predict column header and data type of the belonging cells.
- Cell Value Recovery: mask and predict the cell text.
TAPAS: Weakly Supervised Table Parsing via Pre-training (Herzig, ACL 2020)
TAPAS linearizes the concatenation of the utterance (e.g. query/question) and the table, then feeds it into a BERT model, performing unsupervised pre-training with typical masked LM objective. Each token embedding in the input is appended with additional special embedding: position emb, segment emb (whether token is within the utterance or table), column/row emb, rank emb (whether the cell text is string or float, if float, this emb encodes its order).
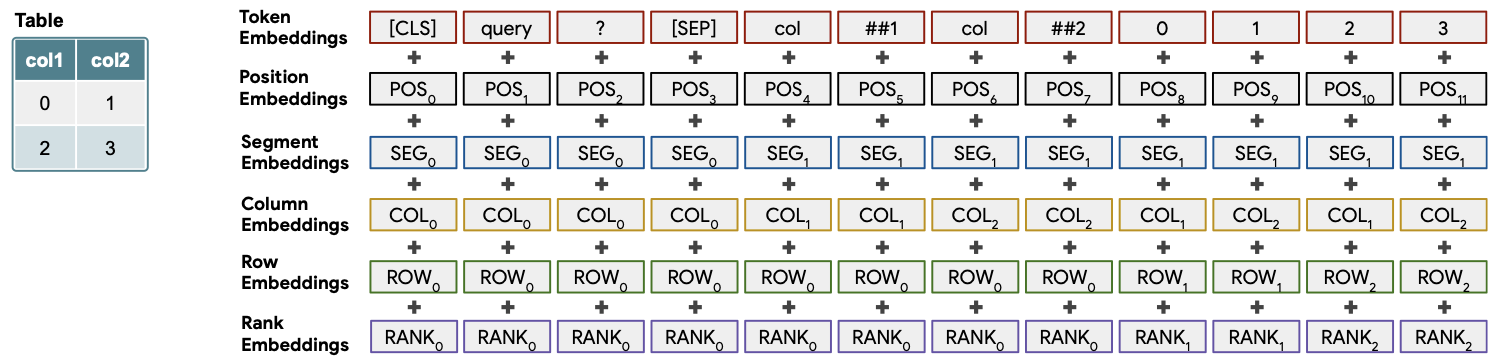
(source: copied from the paper).
TURL: Table Understanding through Representation Learning (Deng, VLDB 2020)
TURL continues to pre-train a Tiny-BERT on the linearization of [table caption, table topic, table headers, table cells]. Tabel cells are represented by a fusion of token embeddings of cell text and the learnable embedding of the associated entity. Positional embeddings are added to tokens in the caption and the header. Additional type embeddings are used to indicate whether a token is within the caption, the header or is a subject cell or object cell. The attention meachnism is modified in the way that not all tokens in the input are visible to each other (e.g. two tokens residing in different rows and different columns can not see each other). This design models the row-column interaction in the table.
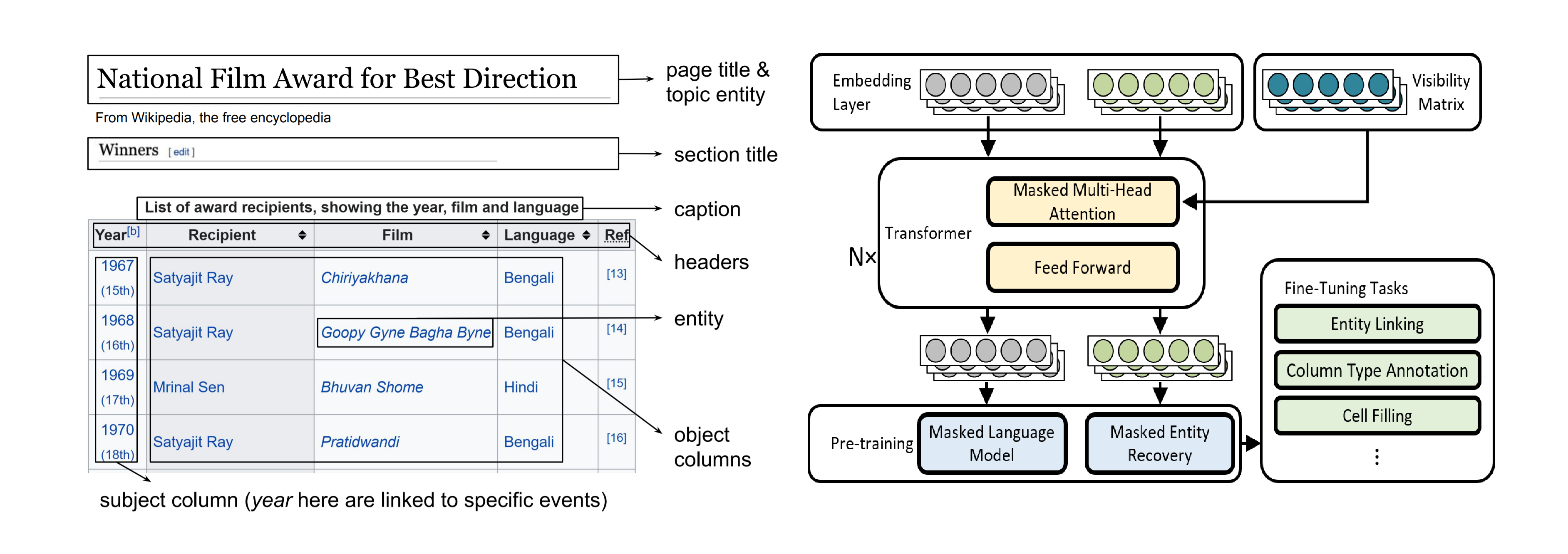
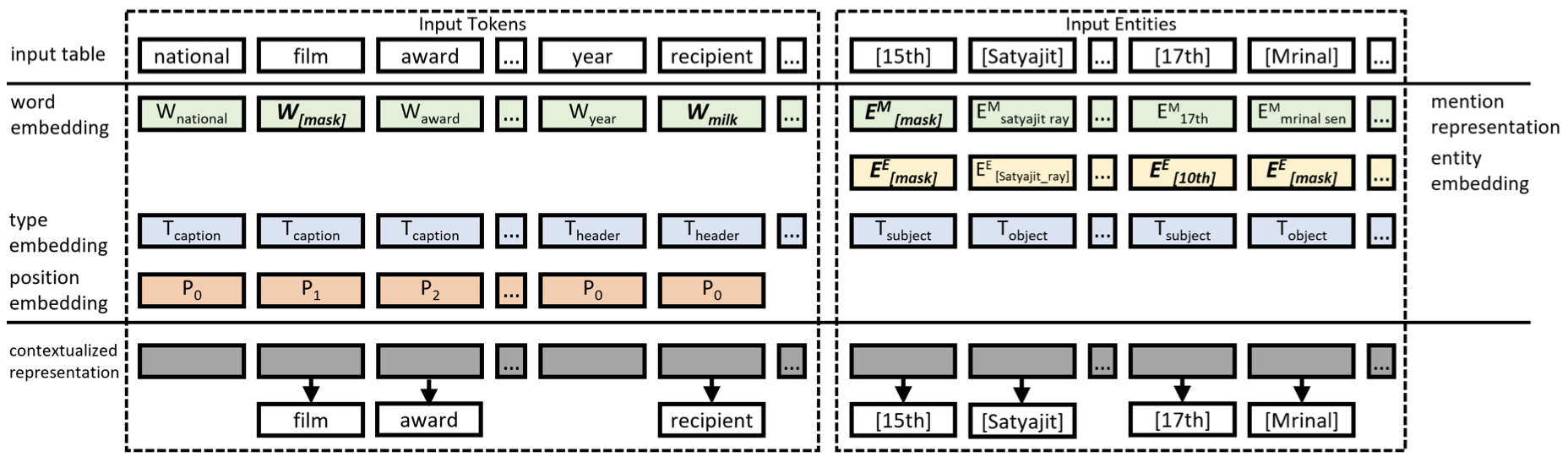
(source: copied from the paper).
Two unsupervised learning objectives in TURL:
- MLM: mask and predict a token in caption or header.
- Masked Entity Recovery: mask a cell and predict the entity representing it (i.e. entity classification).