Experimental benchmarks on the GPU requirements for the training/fine-tuning of LLMs.
This post gathers experimental setups on the GPU usage for the training/fine-tuning of LLMs in the wild.
Table of Contents
Fine-tuning with DeepSpeed
-
My own experience:
Model Context length DS Zero offload GPU precision batch_size_per_GPU gradient_accumulation CodeT5+ 2B 1024 Yes (50G CPU) 2x A100 40G bf16 1 4 FLANT5-XL 3B 1024 Yes (50G CPU) 2x RTX 4090 24G bf16 1 4
-
FLAN-XL (3B) + FLAN-XL (11B)
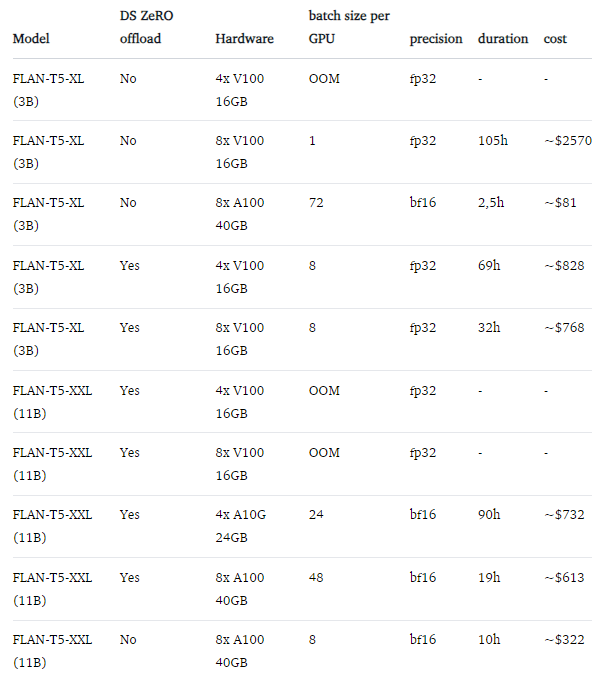 (Source: https://www.philschmid.de/fine-tune-flan-t5-deepspeed)
(Source: https://www.philschmid.de/fine-tune-flan-t5-deepspeed)
Fine-tuning with FSDP
-
My own experience:
Model Context length Full_shard GPU precision batch_size_per_GPU gradient_accumulation Llama-Alpaca 6B 512 Yes 6x A100 40G bf16 1 4 -
GPT-2 XL (1.5B)
2x24GB NVIDIA RTX
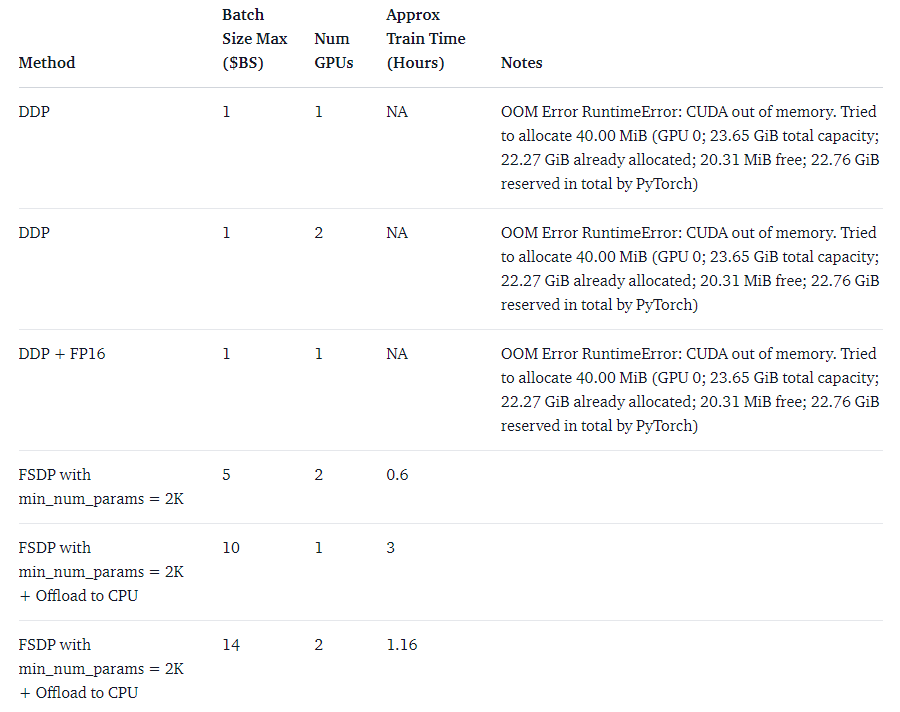 (Source: https://huggingface.co/blog/pytorch-fsdp)
(Source: https://huggingface.co/blog/pytorch-fsdp)
Fine-tuning with LoRA
-
My own experience:
Model Context length GPU precision batch_size_per_GPU gradient_accumulation CodeT5+ 2B 1024 1x RTX 4090 24G fp16 1 8
-
TO (3B) + mTO (12B) + BLOOMZ (7B) (7B)
 (Source: https://github.com/huggingface/peft
(Source: https://github.com/huggingface/peft