What I've learned from finding ways to accelerate the inference of a Transformer model.
Table of Contents
Introduction
When it comes to deploying a machine learning/deep learning model in production environments, there are many factors that need to be worked out. In this post, I would like to outline 2 aspects:
-
(1) The compatibility between the development environment you use to train your model and the production environment.
As nowadays’s AI ecosystem is considerably fragmented from software-level to hardware-level. A lot of ML/DL training frameworks are at hand for us to build our model such as PyTorch, Tensorflow or scikit-learn. We can get our jobs done on Windows or Linux with Intel GPUs and Python runtime, but later on, we want to deploy the product on cloud or edge devices with another runtime (e.g. C++) and another sort of GPUs (e.g. NVIDIA). Facing this cross-platform deployment challenge, a classic strategy is to build a specific model for a specific platform, as illustrated in the figure below. This means that developer is required to pick developing tools corresponding to targeted environments which may not be the ones they love to use. Also, they need to ensure that there is no accuracy gap between different model versions.
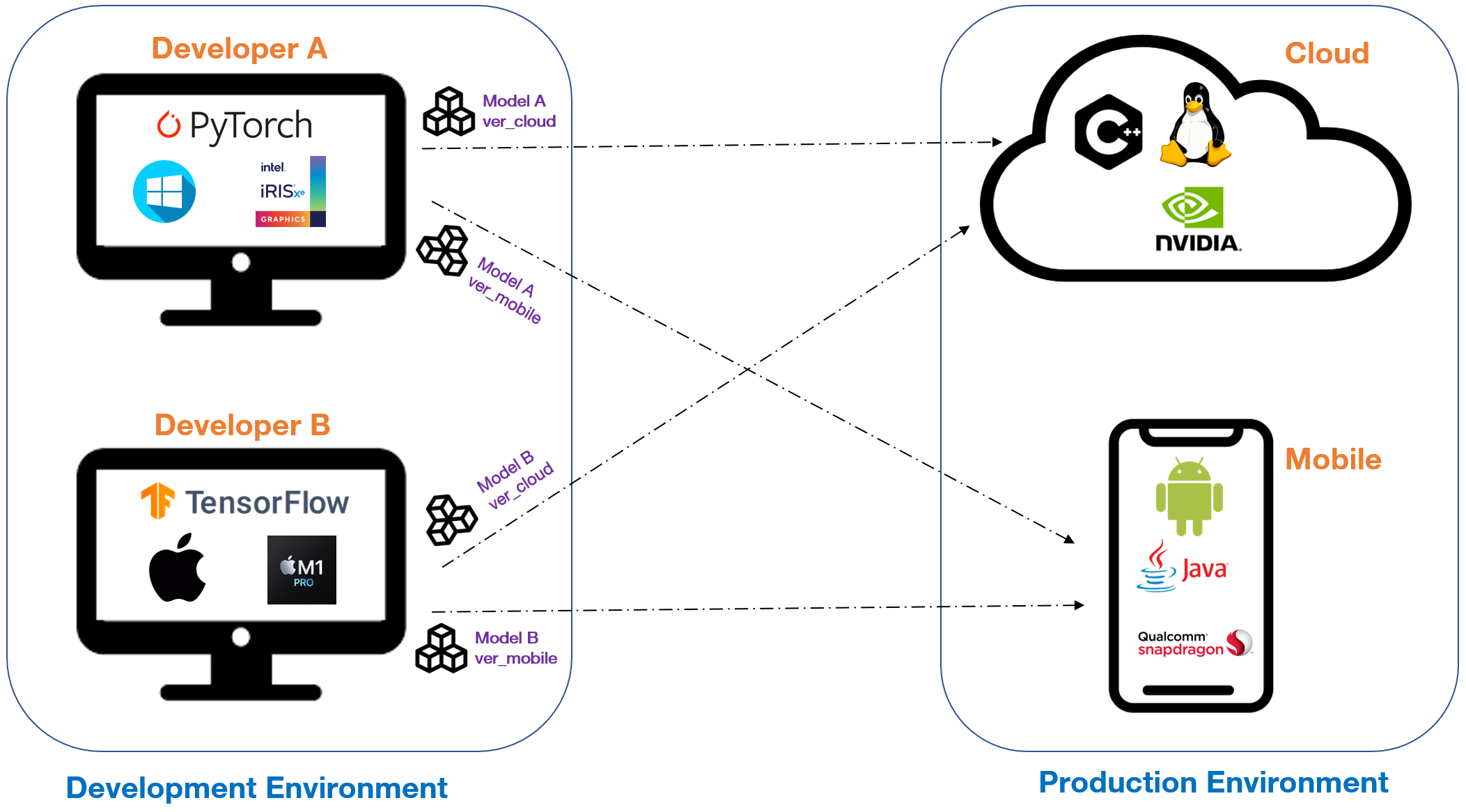
-
(2) Optimizing model inference for an efficient user experience.
In production, together with accuracy, scalability and high performance become crucial concerns. To deal with that, there could be two strategies:
- Using smaller models or distilled models that still yield the accuracy you need: DL models, especially, Transformer-based LM models, become more and more powerful, at the cost of number of model parameters and environmental responsibility (carbon footprint). However, larger model does not necessarily mean better. The data size, the training/fine-tuning recipe also account for the performance of your model (https://www.deeplearning.ai/the-batch/finding-the-best-data-to-parameter-ratio-for-nlp-models/).
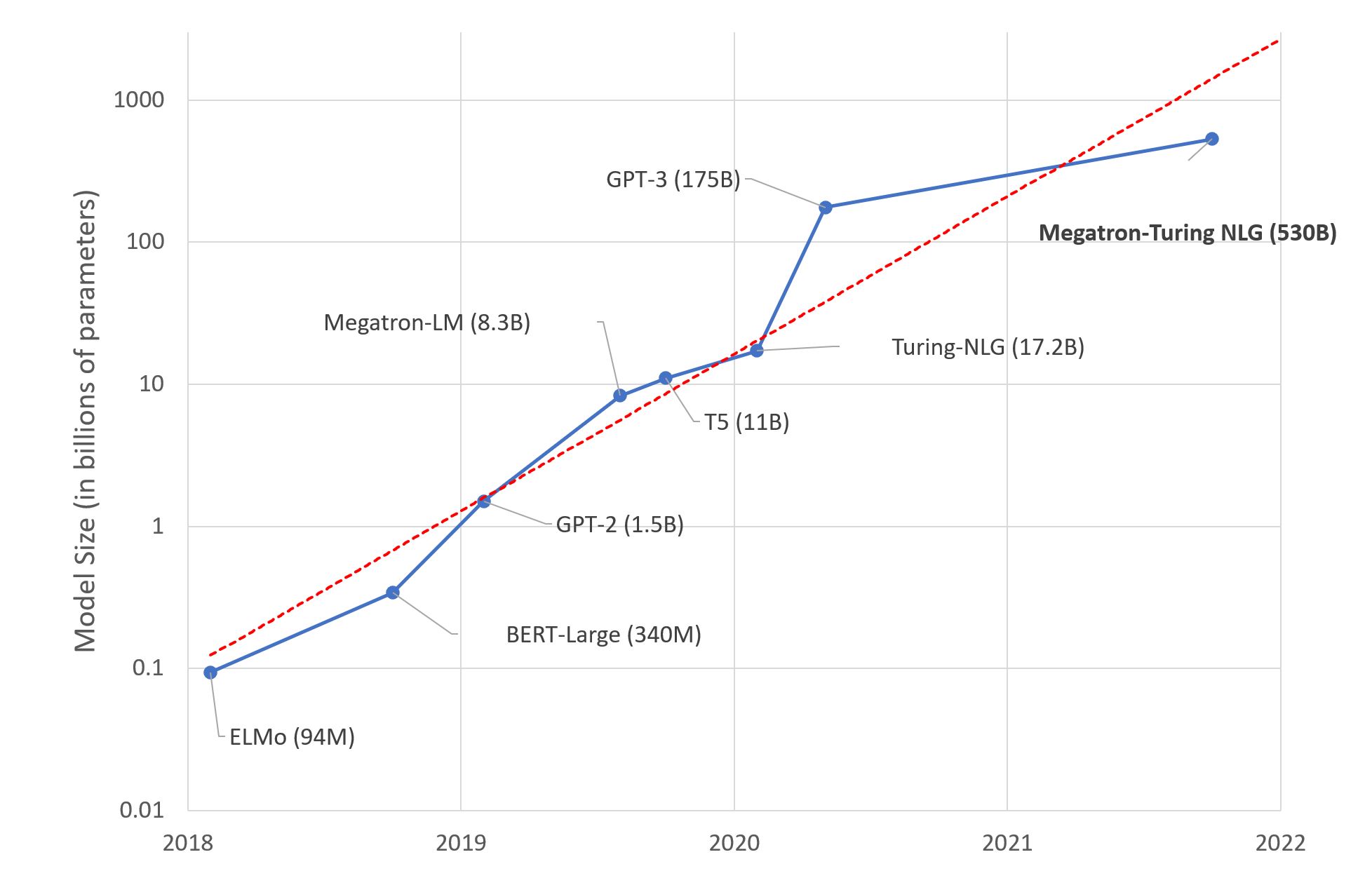 (Source: https://huggingface.co/blog/large-language-models)
(Source: https://huggingface.co/blog/large-language-models)- Optimizing your model: basically, the optimization involves the improvement of running time (latency) and memory throughput and it is done not only at software level (algorithm, training framework, OS, programming language) but also at hardware level (GPU, hardware accelerator). As the AI ecosystem is fragmented, we can have many possible combinations of {OS, framework, runtime, hardware} with different pros/cons for developing a model. This makes the optimization a challenging task.
A solution
Up to this point, you might envision how tough the path from conception to production in ML is. To address two deployment issues mentioned above, a research direction has been identified for AI ecosystem in which the development-production workflow becomes modularizable and the frameworks become interoperable. The idea is to standardize the bridge between development environment and production environment, alternatively stated, the bridge between software (OS, framework) and hardware (CPU, GPU). By this way, different frameworks can be combined with different hardwares without modification. Let’s dive a bit deeper into this standardization process, as demonstrated in the figure below:
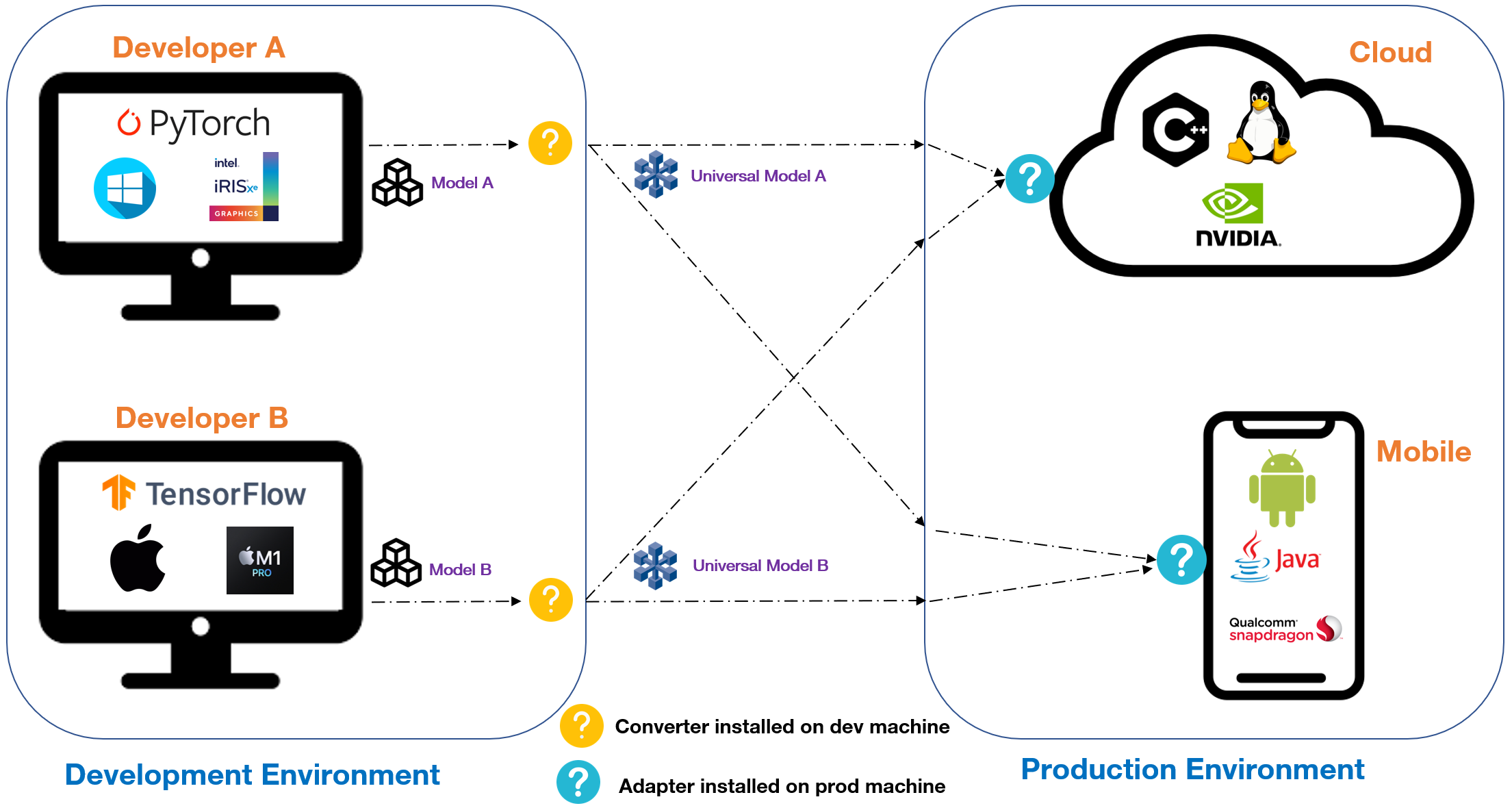
It requires two plugins: (i) a converter to transform the model you are developing in your environment into an universal one that can be loaded, optimized and executed by (ii) an adapter installed on different target platforms.
 ONNX (Open Neural Network eXchange) Converter
ONNX (Open Neural Network eXchange) Converter
According to https://onnx.ai/, ONNX (Open Neural Network eXchange) is an open serialized format built to represent machine learning models. ONNX defines a common set of operators - the building blocks of machine learning and deep learning models - and a common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers. It is backed by many leading AI companies:
 (Source: https://onnx.ai/)
(Source: https://onnx.ai/)
 Adapter: ONNX Runtime
Adapter: ONNX Runtime
ONNX Runtime is a performant inference engine that can read, optimize the ONNX model format and leverage hardware accelerators to perform inference from ONNX format. It is compatible with various technology stack (frameworks, operating systems and hardware platforms).
 (Source: https://onnxruntime.ai)
(Source: https://onnxruntime.ai)
For example, assuming your production environment supports Linux OS x64, Python runtime and NVIDIA GPU as in figure below, then you can install ONNX Runtime via pip install onnxruntime-gpu to be ready for deploying any model created from any technology stack on your dev machine as long as it can be exported to ONNX format.
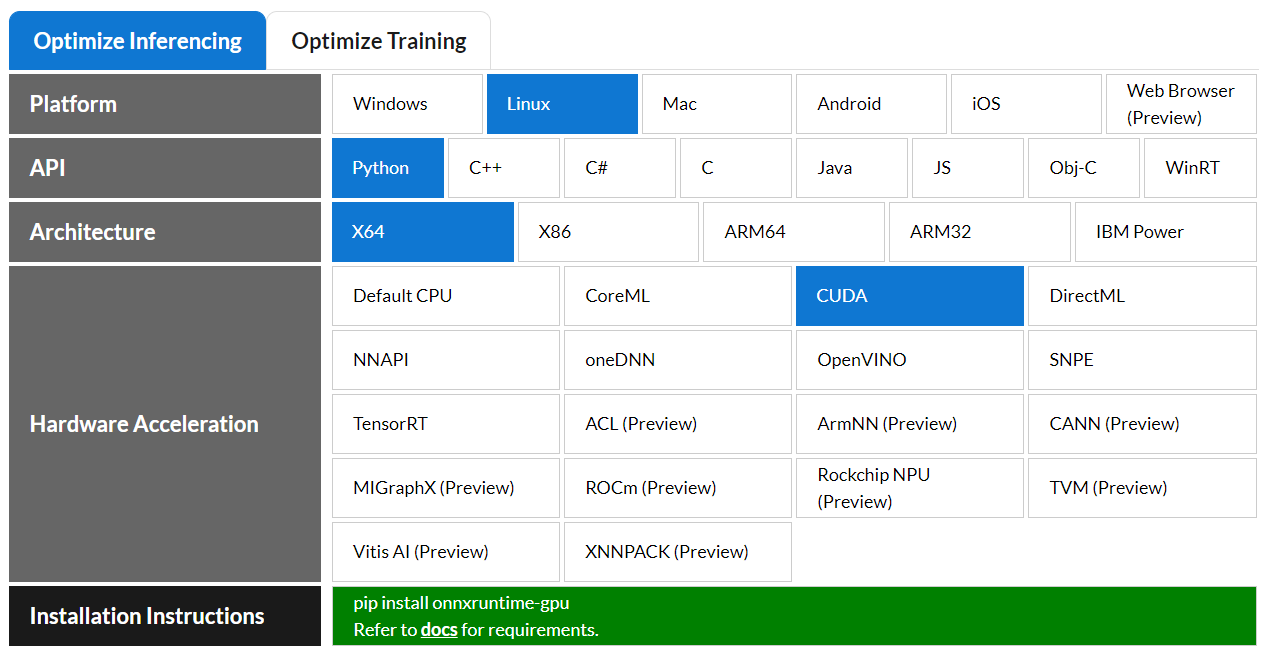
With ONNX and ONNX Runtime, we are able to address two of the issues of putting a ML model in production (compatibility/interoperability and inference performance) introduced earlier in the post. For ML developers, they are liberated from the constraint of framework compatibility and have more freedom to choose their preferred tech stacks. For hardware manufacturers, they can rely on a standard and universal software specification (e.g. ONNX model format) to ease their process of hardware optimization for AI.
Now, let’s go a bit more details into possible inference strategies with ONNX format.
Inference strategies based on ONNX model format
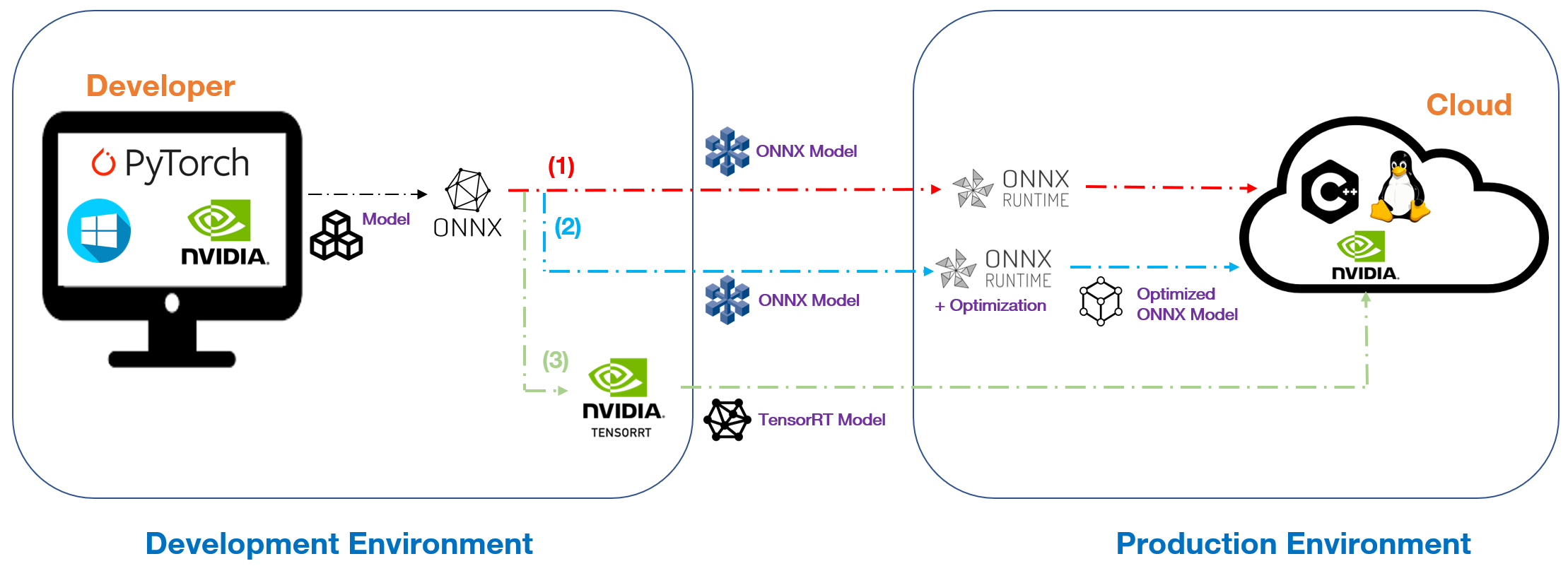
-
(1) After your model is converted into ONNX format, it can be used immediately on targeted device using ONNX Runtime.
-
(2) After your model is converted into ONNX format, ONNX Runtime can further optimize it before performing inference on targeted device. The optimization techniques can be: graph optimization (node pruning, node fusion…) and quantization (e.g. convert FP32 to INT8).
-
(3) It is also possible to convert ONNX model to another format that is optimized for a specific hardware. For example, in the figure above, as Cloud is equipped with NVIDIA GPU, we can convert ONNX model to TensorRT model which is developed dedicatedly for NVIDIA GPUs. ONNX Runtime is no longer in use in this case of course.
Huggingface’s Optimum 
If you are working with Transformers and you want to easily accelerate your model performance leveraging your existing hardware powers, you may think of Optimum. It gathers a set of optimization toolkits (e.g. ONNX Runtime presented above, Intel Neural Compressor, OpenVINO) each of which is designed specifically for each specific hardware. It also provides a high-level API to facilitate the utilization and the optimization in a few lines of code. Typically, an optimization pipeline with Optimum consists of 3 steps:
-
Convert the trained model into the standard format such as ONNX or OpenVINO.
-
Optimize the converted model (e.g. graph optimization, quantization) using available Runtimes such as ONNX Runtime or OpenVINO Runtime.
-
Run the inference on optimized model.
Now, let’s get our hand a bit dirty by trying to accelerate a Transformer model with ONNX and ONNX Runtime using Optimum. In detail, we optimize the inference of a BERT-based model for text classification task (Sentiment Analysis).
Example:
Input: I am learning how to accelerate the inference of a language model using Huggingface's Optimum. I am thinking if it can bring some performance gain. I hope it does."
Output: [{'label': 'POSITIVE', 'score': 0.7894014716148376}]
My machine is equiped with 6GB GPU NVIDIA Quadro RTX 3000. Hence, I’m going to leverage 2 hardware accelerators for NVIDIA via ONNX Runtime : generic accelerator (CUDAExecutionProvider) and TensorRT inference engine (TensorrtExecutionProvider)
For comparison, there are two baselines where the inference is done with native pytorch on either CPU (cpu_torch_model) or GPU (gpu_torch_model).
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
from optimum.onnxruntime import ORTModelForSequenceClassification, ORTOptimizer
from optimum.onnxruntime.configuration import OptimizationConfig
from time import perf_counter
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# baseline: native pytorch CPU
cpu_torch_model = AutoModelForSequenceClassification.from_pretrained(model_id)
cpu_torch_pipe = pipeline("sentiment-analysis", model=cpu_torch_model, tokenizer=tokenizer, device=-1)
# baseline: native pytorch GPU
gpu_torch_model = AutoModelForSequenceClassification.from_pretrained(model_id).to(torch.device('cuda:0'))
gpu_torch_pipe = pipeline("sentiment-analysis", model=gpu_torch_model, tokenizer=tokenizer, device=0)
To optimize the native pytorch model using ONNX Runtime, we first convert it into ONNX format onnx_model and apply graph optimization on converted model.
# convert native pytorch model to ONNX format and graph-optimize it.
onnx_model = ORTModelForSequenceClassification.from_pretrained(model_id, from_transformers=True)
optimizer = ORTOptimizer.from_pretrained(onnx_model)
optimization_config = OptimizationConfig(
optimization_level=2,
optimize_with_onnxruntime_only=False,
optimize_for_gpu=True,
)
optimizer.optimize(save_dir="./optimized", optimization_config=optimization_config)
Next, we define 3 types of inferences for optimized ONNX model:
- Inference on CPU:
# optimized ONNX CPU
optimized_cpu_onnx_model = ORTModelForSequenceClassification.from_pretrained("./optimized/")
optimized_cpu_onnx_pipe = pipeline("sentiment-analysis", model=optimized_cpu_onnx_model, tokenizer=tokenizer)
- Inference on GPU with NVIDIA generic accelerators (CUDA):
# optimized ONNX CUDA
optimized_cuda_onnx_model = ORTModelForSequenceClassification.from_pretrained("./optimized/", provider="CUDAExecutionProvider")
optimized_cuda_onnx_pipe = pipeline("sentiment-analysis", model=optimized_cuda_onnx_model, tokenizer=tokenizer)
- Inference on GPU with NVIDIA TensorRT engine:
# optimized ONNX Tensorrt
## ONNX Runtime graph optimization need to be disabled for the model to be consumed and optimized by TensorRT
optimized_tensorrt_onnx_model = ORTModelForSequenceClassification.from_pretrained(model_id, from_transformers=True, session_options=session_options, provider="TensorrtExecutionProvider")
optimized_tensorrt_onnx_pipe = pipeline("sentiment-analysis", model=optimized_tensorrt_onnx_model, tokenizer=tokenizer)
We measure the latency of inference settings described above with a simple benchmark as following:
intput = "I am learning how to accelerate the inference of a language model using Huggingface's Optimum. \
I am wondering if it can bring some performance gain. I hope it does."
# ref: https://www.philschmid.de/optimizing-transformers-with-optimum
def measure_latency(pipe):
latencies = []
# warm up
for _ in range(50):
_ = pipe(intput)
# Timed run
for _ in range(1000):
start_time = perf_counter()
_ = pipe(intput)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute averaged execution time
avg_time_ms = 1000 * sum(latencies)/len(latencies)
return f"Average latency (ms) : {avg_time_ms:.2f}"
The results are shown below:
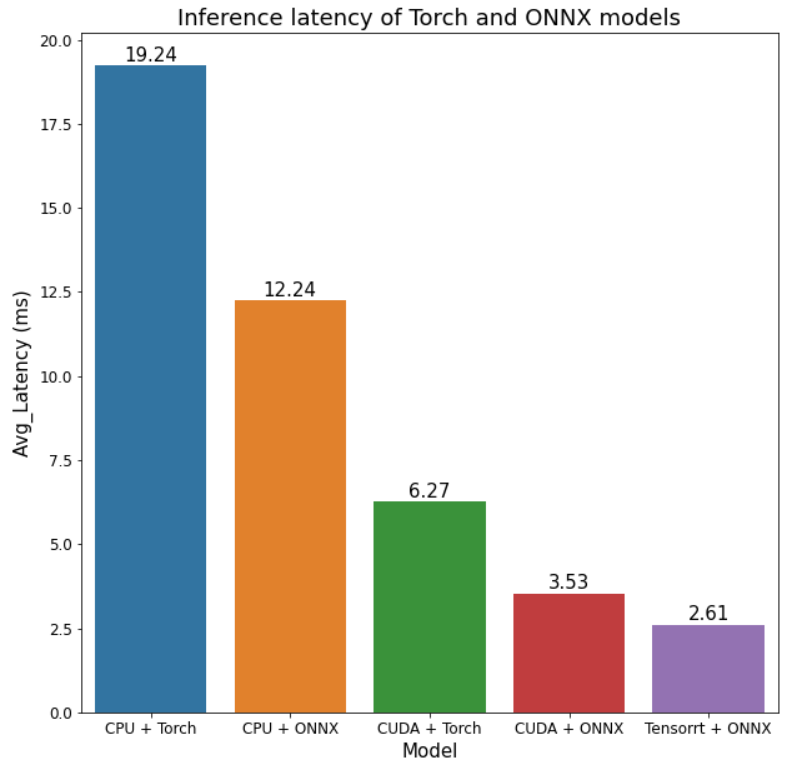
Clearly, with ONNX format and ONNX Runtime, the performance has been significantly boosted even on CPU mode:
-
ONNX Runtime runs inference on CPU accelerates 1.56x w.r.t native pyTorch running on CPU.
-
ONNX Runtime leverages better the GPU hardware than native pyTorch by 2.4x faster on NVIDIA GPU.
Conclusion
This post walked you through the introduction of two challenges for deploying an AI model (Transformer model in particular) in production: (i) the interoperability between different frameworks and (ii) the performance issue. These two challenges can be addressed by standardizing model formats and employing a powerful cross-platform inference engine for running the inference on this format, such as {ONNX format, ONNX Runtime} or {OpenVINO, OpenVINO Runtime}.
If we relax the interoperability aspect and focus on boosting the model performance, then, apart from the method based on converting the original model into standard format as described in this post, kernl, recently released, intervenes directly in GPU kernels that allows to accelerate and optimize your model right on Pytorch with a single line of code, without converting to any standard format. Its benchmark (below) shows impressive improvements over other optimization techniques. Furthermore, they pay more attention to generative models (e.g. Seq2Seq model) which prove to be more difficult to optimize. However, if you don’t have the new generation of NVIDIA GPU (Ampere), you are not able to use this tool yet. (follow up here)
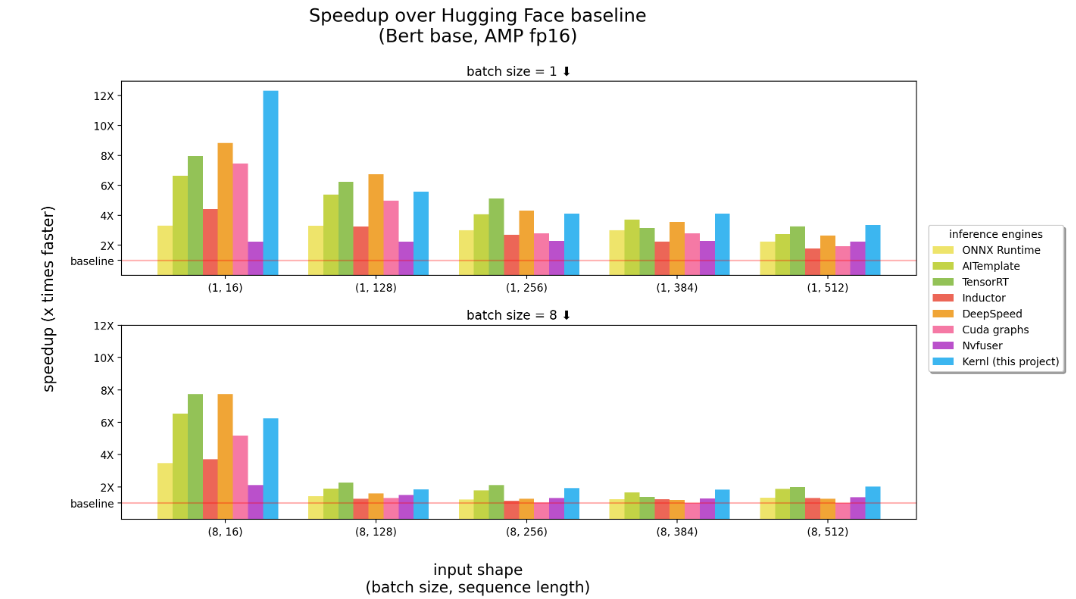 (Source: https://github.com/ELS-RD/kernl)
(Source: https://github.com/ELS-RD/kernl)
References:
- https://www.philschmid.de/optimizing-transformers-with-optimum
- https://odsc.medium.com/interoperable-ai-high-performance-inferencing-of-ml-and-dnn-models-using-open-source-tools-6218f5709071
- https://medium.com/geekculture/onnx-in-a-nutshell-4b584cbae7f5
- https://huggingface.co/blog/convert-transformers-to-onnx