How to develop an Asynchronous REST API with Python, Flask, Gunicorn and Celery
Table of Contents
What is REST API ?
API (Application Programming Interface) is a software interface that allows one application to communicate with another application. REST API (Representational State Transfer) can be understood as a web service API where two applications talk to each other over a network (e.g. internet). Imagine that you are developing and deploying a system with a lot of interesting functionalities, you want to share it with your clients so that they can integrate your tools into their application workflow. To some extent, the client would appreciate a friendly and easy access to your application server. Instead of reading every line of your code to see what is going on inside algorithms, they prefer an abstract understanding of the behavior of the application like: what does this application do, what are the required formats/types of input/output. To this end, REST API delivers a set of friendly functions like POST, GET, DELETE to your application server in order for clients to easily communicate.
Example: Wikipedia provides a REST API for retrieving the information of a Wikipedia entity. For instance, to get a description of France country:
curl -X GET https://en.wikipedia.org/api/rest_v1/page/summary/France | jq '.extract'
Output:
"France, officially the French Republic, is a transcontinental country predominantly located in Western Europe and spanning overseas regions and territories in the Americas and the Atlantic, Pacific and Indian Oceans. Its metropolitan area extends from the Rhine to the Atlantic Ocean and from the Mediterranean Sea to the English Channel and the North Sea; overseas territories include French Guiana in South America, Saint Pierre and Miquelon in the North Atlantic, the French West Indies, and many islands in Oceania and
the Indian Ocean. Due to its several coastal territories, France has the largest exclusive economic zone in the world. France borders Belgium, Luxembourg, Germany, Switzerland, Monaco, Italy, Andorra, and Spain in continental Europe, as well as the Netherlands,
Suriname, and Brazil in the Americas via its overseas territories in French Guiana and Saint Martin. Its eighteen integral regions
span a combined area of 643,801 km2 (248,573 sq mi) and close to 68 million people. France is a unitary semi-presidential republic
with its capital in Paris, the country's largest city and main cultural and commercial centre; other major urban areas include Marseille, Lyon, Toulouse, Lille, Bordeaux, and Nice."
Flask is a lightweight Python web framework which allows to write web application in Python quickly and easily.
Gunicorn is a Python Web Server Gateway Interface (WSGI) server playing as an intermediate between the web application server and the client. It receives requests from client, forwards it to web application and sends back the result to client.
Flask is shipped with some basic web server features, therefore, for development purpose, it is acceptable if Flask is used as WSGI server. However, in production, it is recommended using a real WSGI server, such as Gunicorn.
Problems of Synchronous API
In synchronous API, a synchronous worker handles a single request at a time, the client and the server communicate uninterruptedly back and forth in the same time frame.
Assuming you are building a web server which supports a long-running task using Flask and Gunicorn.
# server.py
from flask import Flask, jsonify, make_response
import time
app = Flask(__name__)
@app.route("/long_running_task", methods=["POST"])
def long_running_task():
time.sleep(30) ## represents long-running task
return make_response(jsonify({'result': "done long-running task"}), 200)
if __name__ == "__main__":
app.run(host='0.0.0.0')
# web server endpoint
# wsgi.py
from server import app
if __name__ == "__main__":
app.run()
the server is listening at port 5000 and is configured one synchronous worker to handle requests sent from clients.
gunicorn --workers 1 --bind 0.0.0.0:5000 wsgi:app
[2022-10-30 21:06:01 +0100] [976] [INFO] Starting gunicorn 20.1.0
[2022-10-30 21:06:01 +0100] [976] [INFO] Listening at: http://0.0.0.0:5000 (976)
[2022-10-30 21:06:01 +0100] [976] [INFO] Using worker: sync
[2022-10-30 21:06:01 +0100] [978] [INFO] Booting worker with pid: 978
If a client application sends a request to the server for executing the long-running task, its workflow will be blocked for ~30 (s) until it receives the respone from the server. In other words, the whole application is not able to handle others tasks during this time.
One solution for this issue is to use async workers, such Greenlets, gthread for the server side, or asyncio for the client side. However, due to their thread-based nature, these kinds of async workers are only suitable for I/O-bound application.
Asynchronous API
Asynchronous API comes up with the idea that in the web server, a heavy process should stay outside the main workflow of the server as well as outside the request/response cycle between client and server. Instead, it should be handled in background. By this way, when a client sends a request, the server can put the request into a task queue and let a task orchestrator (e.g. Celery) pick up a worker to deal with it, the client is immediately acknowledged with a task_id, the client can continue to do other things without waiting for the termination of the request, they can get back later to the server with the task_id when the result is ready. Also, the server is free to accept other requests from other users.
Celery is a distributed task queue that allows to schedule and process vast amount of tasks on different machines. It has 3 main components:
- A message broker (e.g. RabbitMQ, Redis) is a messaging bridge between the web server application (Flask) and (remote) workers. It manages the task queue by receiving task requests from the application, distributing tasks across different workers and delivering task’ s status back to client.
- A backend (e.g. Redis, MongoDB) stores the task’s results returned from workers.
- A pool of (distributed) workers in which each worker looks at the task queue and pick up a task to handle independently of other workers and outside the context of main system.
The client request/server response cycle is illustrated in the figure below:
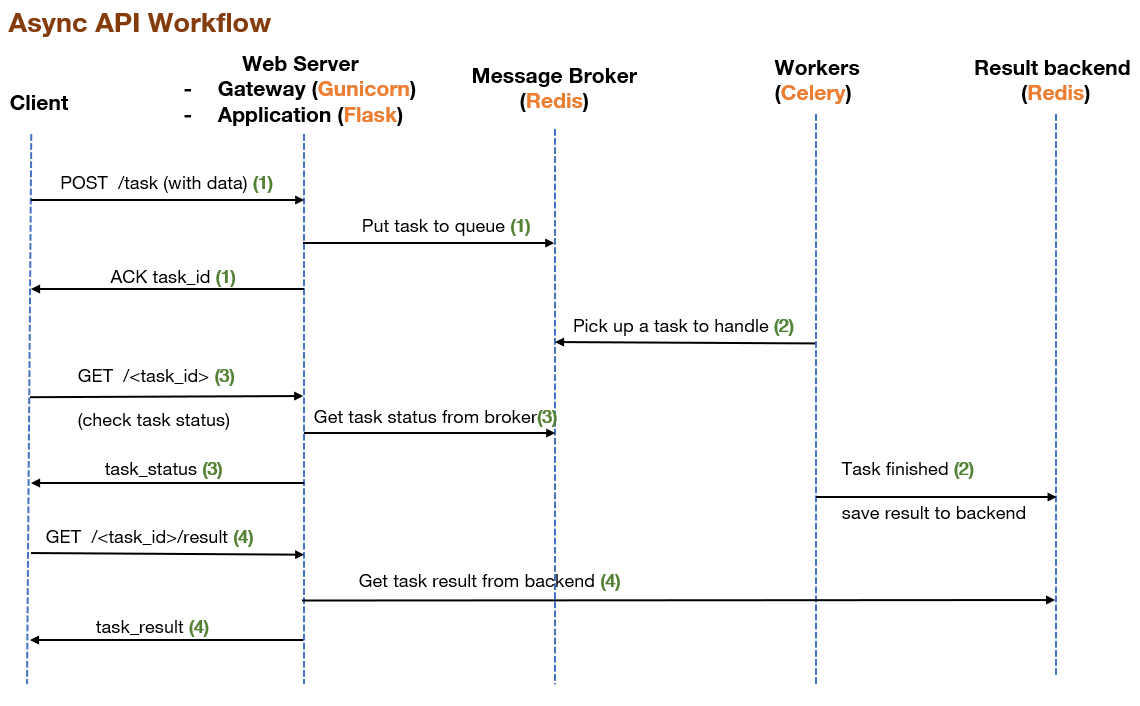
We choose Redis (in-memory key-value database) as Message Broker and Result Backend. More information about Celery’s Broker & Backend can be found at here. Among possible backends, according to my experience, RPC:RabbitMQ should not be considered since it is limited in functionality and contains bugs.
Let’s go ahead and implement each stage in the workflow.
(0) As Celery task queue requires a redis broker and a redis backend. We first install redis via docker:
docker run --name broker-backend -d redis -p 6379:6379
The redis server is listening at port 6379. We next initialize the task queue:
# server.py
...
...
""" CELERY CONFIG """
from celery import Celery
celery = Celery("async_tasks", broker='redis://localhost:6379/0', backend='redis://localhost:6379/0',
task_ignore_result=False, task_track_started=True)
task_ignore_result is set to False to enable storing task’s results to the backend. If the task is picked up by a worker and task_track_started is True, a status STARTED will be reported to the broker.
(1) + (2) Create a celery async task to handle long_running_task. It stays outside the main event loop and is executed by a separate worker.
# server.py
...
...
# create a celery async task that handles `long_running_task`
# by wrapping the function with @celery.task decorator.
@celery.task(bind=True, name='async_tasks.long_running_task', task_acks_late=True)
def async_long_running_task(self):
time.sleep(30) ## represents long-running task
return f"done long-running task {self.request.id}"
With bind=True, the task has access to the attributes of task instance, such as task id, task states. If task_acks_late is enabled, even when the task fails (e.g. killed due to OOM) or timeout, its status will be acknowledged.
We then open a route from client to server for POST /async_long_running_task request. The Flask server accepts the request from client, does not actually execute the request (as in Synchronous API), but rather put it in the task queue using delay function. An task_id will be ACK immediately. The client can do other things, such as making a second request to the server without waiting for the first one to finish.
# server.py
...
...
# create a route from client to server for POST /task request
@app.route('/async_long_running_task', methods=["POST"])
def submit_task_to_taskQueue():
task = async_long_running_task.delay()
return make_response(jsonify({'task_id': task.id}), 202)
Now, let’s launch the Celery workers.
celery -A server.celery worker --concurrency=1 --loglevel=info
--- ***** -----
-- ******* ---- Linux-4.19.128-microsoft-standard-x86_64-with-glibc2.10 2022-11-01 11:55:08
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: async_tasks:0x7f48e2da5130
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 1 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. async_tasks.long_running_task
[2022-11-01 11:55:08,104: INFO/MainProcess] Connected to redis://localhost:6379/0
[2022-11-01 11:55:08,109: INFO/MainProcess] mingle: searching for neighbors
[2022-11-01 11:55:09,119: INFO/MainProcess] mingle: all alone
[2022-11-01 11:55:09,130: INFO/MainProcess] celery@YD-H02M403 ready.
--concurrency=1 indicates the number of workers (1) which defaults to the number of available CPUs. We can also verify that celery workers are correctly connected to redis broker and backend. It currently supports 1 async task class: async_tasks.long_running_task.
Sound good so far ! Let’s try to send a request to the API:
curl -X POST localhost:5000/async_long_running_task
{"task_id":"923733ec-2285-4295-9613-558703248957"}
We receive straight away an unique id 923733ec-2285-4295-9613-558703248957 for the request we’ve sent.
(3) With task_id, we can check the status of the request anytime. For this, we create a route from client to server for GET status /<task_id>.
# server.py
...
...
# create a route from client to server for GET /<task_id> status
@app.route('/async_long_running_task/<task_id>')
def check_task_status(task_id):
task = async_long_running_task.AsyncResult(task_id)
return make_response(jsonify({'task_status': task.status}), 200)
Let’s check the status of request we’ve sent:
curl localhost:5000/async_long_running_task/923733ec-2285-4295-9613-558703248957
{"task_status":"STARTED"}
The task involved would require ~30 (s) to process. If we check its status less than 30 (s) since we launched it, we would get STARTED meaning that the task is started by the worker, but not finished yet. After 30 (s), we will have SUCCESS status:
curl localhost:5000/async_long_running_task/923733ec-2285-4295-9613-558703248957
{"task_status":"SUCCESS"}
For more information about possible built-in states in celery, have a look at here.
Two important remarks:
- State
PENDINGis vague. On the one hand, it means that the task is well positioned in the queue but is not picked up yet by the workers. But on the other hands, it also means the task does not exist because we provided a wrongtask_id. - Apart from built-in states, we can enrich the state set by adding custom states, for example, in order to ensure a smooth tracking of a heavy-duty task, we can detail the progress of the task by adding states such as
IN PROGRESSorSTEP 1,STEP 2.
(4) Once the task is successfully executed, its result is stored in the backend.
# server.py
...
...
# create a route from client to server for GET result /<task_id>
@app.route('/async_long_running_task/<task_id>/result')
def get_task_result(task_id):
task = async_long_running_task.AsyncResult(task_id)
if task.status == "SUCCESS":
return make_response(jsonify({'task_result': task.result}), 200)
else:
return make_response(jsonify({'message': 'Task not finished yet !'}), 200)
We are now able to collect the task’s result by sending a GET result /<task_id> request:
curl localhost:5000/async_long_running_task/923733ec-2285-4295-9613-558703248957/result
{"task_result":"done long-running task 923733ec-2285-4295-9613-558703248957"}
Voilà, in this blog post, we have gone through a step-by-step tutorial on building a simple python-based asynchronous REST API. Hope you enjoyed it ![]()